|
|
@@ -23,11 +23,12 @@ graph LR
|
|
|
|
|
|
PaddleX 所提供的预训练的模型产线均可以**快速体验效果**,如果产线效果可以达到您的要求,您可以直接将预训练的模型产线进行**开发集成/部署**,如果效果不及预期,可以使用私有数据对产线中的模型进行**微调**,直到达到满意的效果。
|
|
|
|
|
|
-下面,让我们以登机牌识别的任务为例,介绍PaddleX模型产线工具的本地使用过程,在使用前,请确保您已经按照[PaddleX本地安装教程](../installation/installation.md)完成了PaddleX的安装。
|
|
|
+下面,让我们以登机牌识别的任务为例,介绍PaddleX模型产线工具的本地使用过程。
|
|
|
+在使用前,请确保您已经按照[PaddleX本地安装教程](../installation/installation.md)完成了PaddleX的安装。
|
|
|
|
|
|
## 1、选择产线
|
|
|
|
|
|
-PaddleX中每条产线都可以解决特定任务场景的问题如目标检测、时序预测、语义分割等,您需要根据具体任务选择后续进行开发的产线。例如此处为登机牌识别任务,对应 PaddleX 的【通用 OCR 产线】。更多任务与产线的对应关系可以在 [PaddleX产线列表(CPU/GPU)](../support_list/pipelines_list.md)查询。
|
|
|
+PaddleX中每条产线都可以解决特定任务场景的问题如目标检测、时序预测、语义分割等,您需要根据具体任务选择后续进行开发的产线。例如此处为登机牌识别任务,对应 PaddleX 的[通用OCR产线](./tutorials/ocr_pipelines/OCR.md)。更多任务与产线的对应关系可以在 [PaddleX产线列表(CPU/GPU)](../support_list/pipelines_list.md)查询。
|
|
|
|
|
|
## 2、快速体验
|
|
|
|
|
|
@@ -39,36 +40,34 @@ PaddleX提供了三种可以快速体验产线效果的方式,您可以根据
|
|
|
* 命令行快速体验:[PaddleX产线命令行使用说明](../pipeline_usage/instructions/pipeline_CLI_usage.md)
|
|
|
* Python脚本快速体验:[PaddleX产线Python脚本使用说明](../pipeline_usage/instructions/pipeline_python_API.md)
|
|
|
|
|
|
-以实现登机牌识别任务的通用OCR产线为例,一行命令即可快速体验产线效果:
|
|
|
+以实现登机牌识别任务的通用OCR产线为例,可以用三种方式体验产线效果:
|
|
|
|
|
|
-```bash
|
|
|
-paddlex --pipeline OCR --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png --device gpu:0 --save ./output/
|
|
|
-```
|
|
|
-参数说明:
|
|
|
+**🌐 在线体验**
|
|
|
+
|
|
|
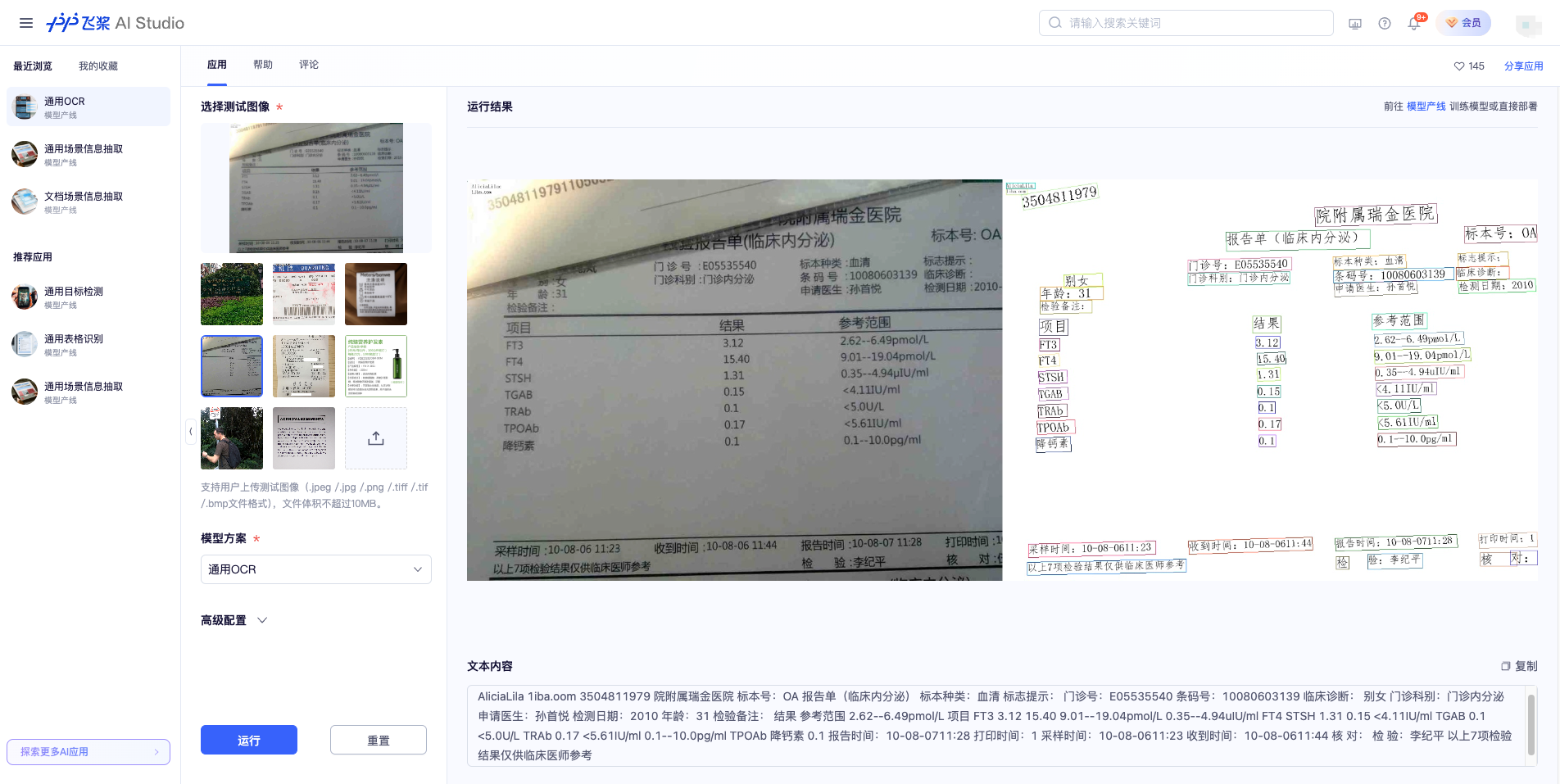
+您可以在AI Studio[在线体验](https://aistudio.baidu.com/community/app/91660/webUI?source=appMineRecent)通用 OCR 产线的效果,用官方提供的 Demo 图片进行识别,例如:
|
|
|
|
|
|
-```bash
|
|
|
---pipeline:产线名称,此处为OCR产线
|
|
|
---input:待处理的输入图片的本地路径或URL
|
|
|
---device 使用的GPU序号(例如gpu:0表示使用第0块GPU,gpu:1,2表示使用第1、2块GPU),也可选择使用CPU(--device cpu)
|
|
|
-```
|
|
|
+
|
|
|
|
|
|
-如需对产线配置进行修改,可获取配置文件后进行修改,获取配置文件方式如下:
|
|
|
+**💻 命令行方式体验**
|
|
|
|
|
|
+一行命令即可快速体验产线效果,使用 [测试文件](https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png),并将 `--input` 替换为本地路径,进行预测:
|
|
|
```bash
|
|
|
-paddlex --get_pipeline_config OCR
|
|
|
+paddlex --pipeline OCR --input general_ocr_002.png --device gpu:0
|
|
|
```
|
|
|
-
|
|
|
-获取产线配置文件后,可将 `--pipeline` 替换为配置文件保存路径,即可使配置文件生效。例如,若配置文件保存路径为 `./ocr.yaml`,只需执行:
|
|
|
+参数说明:
|
|
|
|
|
|
```bash
|
|
|
-paddlex --pipeline ./ocr.yaml --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png --save ./output/
|
|
|
+--pipeline:产线名称,此处为OCR产线
|
|
|
+--input:待处理的输入图片的本地路径或URL
|
|
|
+--device 使用的GPU序号(例如gpu:0表示使用第0号GPU,gpu:1,2表示使用第1、2号GPU),也可选择使用CPU(--device cpu)
|
|
|
```
|
|
|
-其中,`--device` 等参数无需指定,将使用配置文件中的参数。若依然指定了参数,将以指定的参数为准。
|
|
|
+<details>
|
|
|
+ <summary> 👉点击查看运行结果</summary>
|
|
|
|
|
|
运行后,得到的结果为:
|
|
|
|
|
|
```bash
|
|
|
-{'input_path': '/root/.paddlex/predict_input/general_ocr_002.png', 'dt_polys': [array([[ 6, 13],
|
|
|
+{'input_path': 'general_ocr_002.png', 'dt_polys': [array([[ 6, 13],
|
|
|
[64, 13],
|
|
|
[64, 31],
|
|
|
[ 6, 31]], dtype=int16), array([[210, 14],
|
|
|
@@ -81,20 +80,79 @@ paddlex --pipeline ./ocr.yaml --input https://paddle-model-ecology.bj.bcebos.com
|
|
|
可视化结果如下:
|
|
|
|
|
|

|
|
|
+
|
|
|
+</details>
|
|
|
+
|
|
|
+在执行上述命令时,加载的是默认的OCR产线配置文件,若您需要自定义配置文件,可按照下面的步骤进行操作:
|
|
|
+
|
|
|
+<details>
|
|
|
+ <summary> 👉点击展开</summary>
|
|
|
+
|
|
|
+获取OCR产线配置文件:
|
|
|
+```bash
|
|
|
+paddlex --get_pipeline_config OCR
|
|
|
+```
|
|
|
+
|
|
|
+执行后,OCR产线配置文件将被保存在当前路径。若您希望自定义保存位置,可执行如下命令(假设自定义保存位置为 `./my_path`):
|
|
|
+
|
|
|
+```bash
|
|
|
+paddlex --get_pipeline_config OCR --save_path ./my_path
|
|
|
+```
|
|
|
+
|
|
|
+获取产线配置文件后,可将 `--pipeline` 替换为配置文件保存路径,即可使配置文件生效。例如,若配置文件保存路径为 `./ocr.yaml`,只需执行:
|
|
|
+
|
|
|
+```bash
|
|
|
+paddlex --pipeline ./ocr.yaml --input general_ocr_002.png
|
|
|
+```
|
|
|
+其中,`--model`、`--device` 等参数无需指定,将使用配置文件中的参数。若依然指定了参数,将以指定的参数为准。
|
|
|
+</details>
|
|
|
+
|
|
|
+**💻Python脚本体验**
|
|
|
+
|
|
|
+几行代码即可快速体验产线效果:
|
|
|
+
|
|
|
+```python
|
|
|
+from paddlex import create_pipeline
|
|
|
+
|
|
|
+pipeline = create_pipeline(pipeline="ocr")
|
|
|
+
|
|
|
+output = pipeline.predict("general_ocr_002.png")
|
|
|
+for batch in output:
|
|
|
+ for item in batch:
|
|
|
+ res = item['result']
|
|
|
+ res.print()
|
|
|
+ res.save_to_img("./output/")
|
|
|
+ res.save_to_json("./output/")
|
|
|
+```
|
|
|
+
|
|
|
+执行了如下几个步骤:
|
|
|
+
|
|
|
+* `create_pipeline()` 实例化产线对象
|
|
|
+* 传入图片并调用产线对象的 `predict` 方法进行推理预测
|
|
|
+* 对预测结果进行处理
|
|
|
+
|
|
|
+> ❗ Python脚本运行得到的结果与命令行方式相同。
|
|
|
+
|
|
|
+
|
|
|
+如果预训练模型产线的效果符合您的预期,即可直接进行[开发集成/部署](#6开发集成部署),如果不符合,再根据后续步骤对产线的效果进行优化。
|
|
|
## 3、模型选择(可选)
|
|
|
|
|
|
-由于一个产线中可能包含一个或多个模型,在进行模型微调时,您需要根据测试的情况确定微调其中的哪个模型。以此处登机牌识别任务的OCR产线为例,该产线包含文本检测模型(如 `PP-OCRv4_mobile_det`)和文本识别模型(如 `PP-OCRv4_mobile_rec`),如发现文字的定位不准,则需要微调文本检测模型,如果发现文字的识别不准,则需要微调文本识别模型。如果您不清楚产线中包含哪些模型,可以查阅各产线使用教程。
|
|
|
+由于一个产线中可能包含一个或多个单功能模块,在进行模型微调时,您需要根据测试的情况确定微调其中的哪个模块的模型。
|
|
|
+
|
|
|
+以此处登机牌识别任务的OCR产线为例,该产线包含文本检测模型(如 `PP-OCRv4_mobile_det`)和文本识别模型(如 `PP-OCRv4_mobile_rec`),如发现文字的定位不准,则需要微调文本检测模型,如果发现文字的识别不准,则需要微调文本识别模型。如果您不清楚产线中包含哪些模型,可以查阅[模型列表](../support_list/models_list.md)。
|
|
|
+
|
|
|
+
|
|
|
|
|
|
## 4、模型微调(可选)
|
|
|
|
|
|
-在确定好需要微调的模型后,您需要用私有数据集对模型进行训练,PaddleX提供了单模型开发工具,一行命令即可完成模型的训练:
|
|
|
+在确定好需要微调的模型后,您需要用私有数据集对模型进行训练,以文本识别模型( `PP-OCRv4_mobile_rec`)为例,一行命令即可完成模型的训练:
|
|
|
|
|
|
```bash
|
|
|
python main.py -c paddlex/configs/text_recognition/PP-OCRv4_mobile_rec.yaml \
|
|
|
-o Global.mode=train \
|
|
|
-o Global.dataset_dir=your/dataset_dir
|
|
|
```
|
|
|
-此外,对于模型微调中私有数据集的准备、单模型的推理等内容,PaddleX也提供了详细的教程,详细请参考[PaddleX单模型开发工具使用教程](../module_usage/module_develop_guide.md)
|
|
|
+此外,对于模型微调中私有数据集的准备、单模型的推理等内容,PaddleX也提供了详细的教程,详细请参考[PaddleX模块使用教程](../../README.md#-文档)
|
|
|
|
|
|
## 5、产线测试(可选)
|
|
|
|
|
|
@@ -112,28 +170,19 @@ Pipeline:
|
|
|
rec_device: "gpu"
|
|
|
......
|
|
|
```
|
|
|
-随后, 参考[快速体验](#2快速体验)中的命令行方式或Python脚本方式,加载修改后的产线配置文件即可。
|
|
|
+随后, 参考[快速体验](#2快速体验)中的命令行方式或[Python脚本方式](#6开发集成部署),加载修改后的产线配置文件即可。
|
|
|
|
|
|
如果效果满意,即可将微调后的产线进行[开发集成/部署](#6开发集成部署),如果不满意,即可回到[模型选择](#3模型选择可选)尝试继续微调其他任务模块的模型,直到达到满意的效果。
|
|
|
|
|
|
## 6、开发集成/部署
|
|
|
|
|
|
-PaddleX提供了简洁的Python API,用几行代码即可将模型产线集成到您的项目中。此处用于集成登机牌识别的OCR产线示例代码如下:
|
|
|
+如果预训练的产线效果可以达到您对产线推理速度和精度的要求,您可以直接进行开发集成/部署。
|
|
|
|
|
|
-```bash
|
|
|
-from paddlex import create_pipeline
|
|
|
-pipeline = create_pipeline(pipeline="OCR")
|
|
|
-output = pipeline.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_001.png")
|
|
|
-for res in output:
|
|
|
- res.print(json_format=False)
|
|
|
- res.save_to_img("./output/")
|
|
|
- res.save_to_json("./output/res.json")
|
|
|
-```
|
|
|
-更详细的模型产线Python集成方法请参考[PaddleX产线Python脚本使用说明](../pipeline_usage/instructions/pipeline_python_API.md)
|
|
|
+若您需要将产线直接应用在您的Python项目中,可以参考[PaddleX产线Python脚本使用说明](./instructions/pipeline_python_API.md)及[快速体验](#2快速体验)中的Python示例代码。
|
|
|
|
|
|
-同时,PaddleX提供了三种部署方式及详细的部署教程:
|
|
|
+此外,PaddleX 也提供了其他三种部署方式,详细说明如下:
|
|
|
|
|
|
-🚀 **高性能部署**:在实际生产环境中,许多应用对部署策略的性能指标(尤其是响应速度)有着较严苛的标准,以确保系统的高效运行与用户体验的流畅性。为此,PaddleX 提供高性能推理插件,旨在对模型推理及前后处理进行深度性能优化,实现端到端流程的显著提速,详细的高性能部署流程请参考[PaddleX高性能部署指南](../pipeline_deploy/high_performance_deploy.md)。
|
|
|
+🚀 **高性能推理**:在实际生产环境中,许多应用对部署策略的性能指标(尤其是响应速度)有着较严苛的标准,以确保系统的高效运行与用户体验的流畅性。为此,PaddleX 提供高性能推理插件,旨在对模型推理及前后处理进行深度性能优化,实现端到端流程的显著提速,详细的高性能部署流程请参考[PaddleX高性能部署指南](../pipeline_deploy/high_performance_deploy.md)。
|
|
|
|
|
|
☁️ **服务化部署**:服务化部署是实际生产环境中常见的一种部署形式。通过将推理功能封装为服务,客户端可以通过网络请求来访问这些服务,以获取推理结果。PaddleX 支持用户以低成本实现产线的服务化部署,详细的服务化部署流程请参考[PaddleX服务化部署指南](../pipeline_deploy/service_deploy.md)。
|
|
|
|
|
|
@@ -142,20 +191,23 @@ for res in output:
|
|
|
|
|
|
|
|
|
|
|
|
-> ❗ 温馨提醒:PaddleX为每个产线都提供了详细的使用说明,您可以根据需要进行选择,所有产线对应的使用说明如下:
|
|
|
+> ❗ PaddleX为每个产线都提供了详细的使用说明,您可以根据需要进行选择,所有产线对应的使用说明如下:
|
|
|
|
|
|
| 产线名称 | 详细说明 |
|
|
|
|--------------------|----------------------------------------------------------------------------------------------------------------|
|
|
|
-| 文档场景信息抽取v3 | [文档场景信息抽取v3产线Python脚本使用说明](/docs_new/pipeline_usage/tutorials/information_extration_pipelines/document_scene_information_extraction.md) |
|
|
|
-| 通用图像分类 | [通用图像分类产线Python脚本使用说明](/docs_new/pipeline_usage/tutorials/cv_pipelines/image_classification.md) |
|
|
|
-| 通用目标检测 | [通用目标检测产线Python脚本使用说明](/docs_new/pipeline_usage/tutorials/cv_pipelines/image_classification.md) |
|
|
|
-| 通用实例分割 | [通用实例分割产线Python脚本使用说明](/docs_new/pipeline_usage/tutorials/cv_pipelines/instance_segmentation.md) |
|
|
|
-| 通用语义分割 | [通用语义分割产线Python脚本使用说明](/docs_new/pipeline_usage/tutorials/cv_pipelines/semantic_segmentation.md) |
|
|
|
-| 通用图像多标签分类 | [通用图像多标签分类产线Python脚本使用说明](/docs_new/pipeline_usage/tutorials/cv_pipelines/image_multi_label_lassification.md) |
|
|
|
-| 小目标检测 | [小目标检测产线Python脚本使用说明](/docs_new/pipeline_usage/tutorials/cv_pipelines/small_object_detection.md) |
|
|
|
-| 图像异常检测 | [图像异常检测产线Python脚本使用说明](/docs_new/pipeline_usage/tutorials/cv_pipelines/image_anomaly_detection.md) |
|
|
|
-| 通用OCR | [通用OCR产线Python脚本使用说明](/docs_new/pipeline_usage/tutorials/ocr_pipelies/OCR.md) |
|
|
|
-| 通用表格识别 | [通用表格识别产线Python脚本使用说明](/docs_new/pipeline_usage/tutorials/ocr_pipelies/table_recognition.md) |
|
|
|
-| 通用时序预测 | [通用时序预测产线Python脚本使用说明](/docs_new/pipeline_usage/tutorials/time_series_pipelines/time_series_forecasting.md) |
|
|
|
-| 通用时序异常检测 | [通用时序异常检测产线Python脚本使用说明](/docs_new/pipeline_usage/tutorials/time_series_pipelines/time_series_anomaly_detection.md) |
|
|
|
-| 通用时序分类 | [通用时序分类产线Python脚本使用说明](/docs_new/pipeline_usage/tutorials/time_series_pipelines/time_series_classification.md) |
|
|
|
+| 文档场景信息抽取v3 | [文档场景信息抽取v3产线使用教程](./tutorials/information_extration_pipelines/document_scene_information_extraction.md) |
|
|
|
+| 通用图像分类 | [通用图像分类产线使用教程](./tutorials/cv_pipelines/image_classification.md) |
|
|
|
+| 通用目标检测 | [通用目标检测产线使用教程](./tutorials/cv_pipelines/object_detection.md) |
|
|
|
+| 通用实例分割 | [通用实例分割产线使用教程](./tutorials/cv_pipelines/instance_segmentation.md) |
|
|
|
+| 通用语义分割 | [通用语义分割产线使用教程](./tutorials/cv_pipelines/semantic_segmentation.md) |
|
|
|
+| 通用图像多标签分类 | [通用图像多标签分类产线使用教程](./tutorials/cv_pipelines/image_multi_label_classification.md) |
|
|
|
+| 小目标检测 | [小目标检测产线使用教程](./tutorials/cv_pipelines/small_object_detection.md) |
|
|
|
+| 图像异常检测 | [图像异常检测产线使用教程](./tutorials/cv_pipelines/image_anomaly_detection.md) |
|
|
|
+| 通用OCR | [通用OCR产线使用教程](./tutorials/ocr_pipelines/OCR.md) |
|
|
|
+| 通用表格识别 | [通用表格识别产线使用教程](./tutorials/ocr_pipelines/table_recognition.md) |
|
|
|
+| 公式识别 | [公式识别产线使用教程](./tutorials/ocr_pipelines/formula_recognition.md) |
|
|
|
+| 印章识别 | [印章识别产线使用教程](./tutorials/ocr_pipelines/seal_recognition.md) |
|
|
|
+| 时序预测 | [通用时序预测产线使用教程](./tutorials/time_series_pipelines/time_series_forecasting.md) |
|
|
|
+| 时序异常检测 | [通用时序异常检测产线使用教程](./tutorials/time_series_pipelines/time_series_anomaly_detection.md) |
|
|
|
+| 时序分类 | [通用时序分类产线使用教程](./tutorials/time_series_pipelines/time_series_classification.md) |
|
|
|
+
|

 AmberC0209
AmberC0209