|
|
@@ -0,0 +1,616 @@
|
|
|
+English | [简体中文](vehicle_attribute_recognition.md)
|
|
|
+
|
|
|
+# Vehicle Attribute Recognition Pipeline Tutorial
|
|
|
+
|
|
|
+## 1. Introduction to Vehicle Attribute Recognition Pipeline
|
|
|
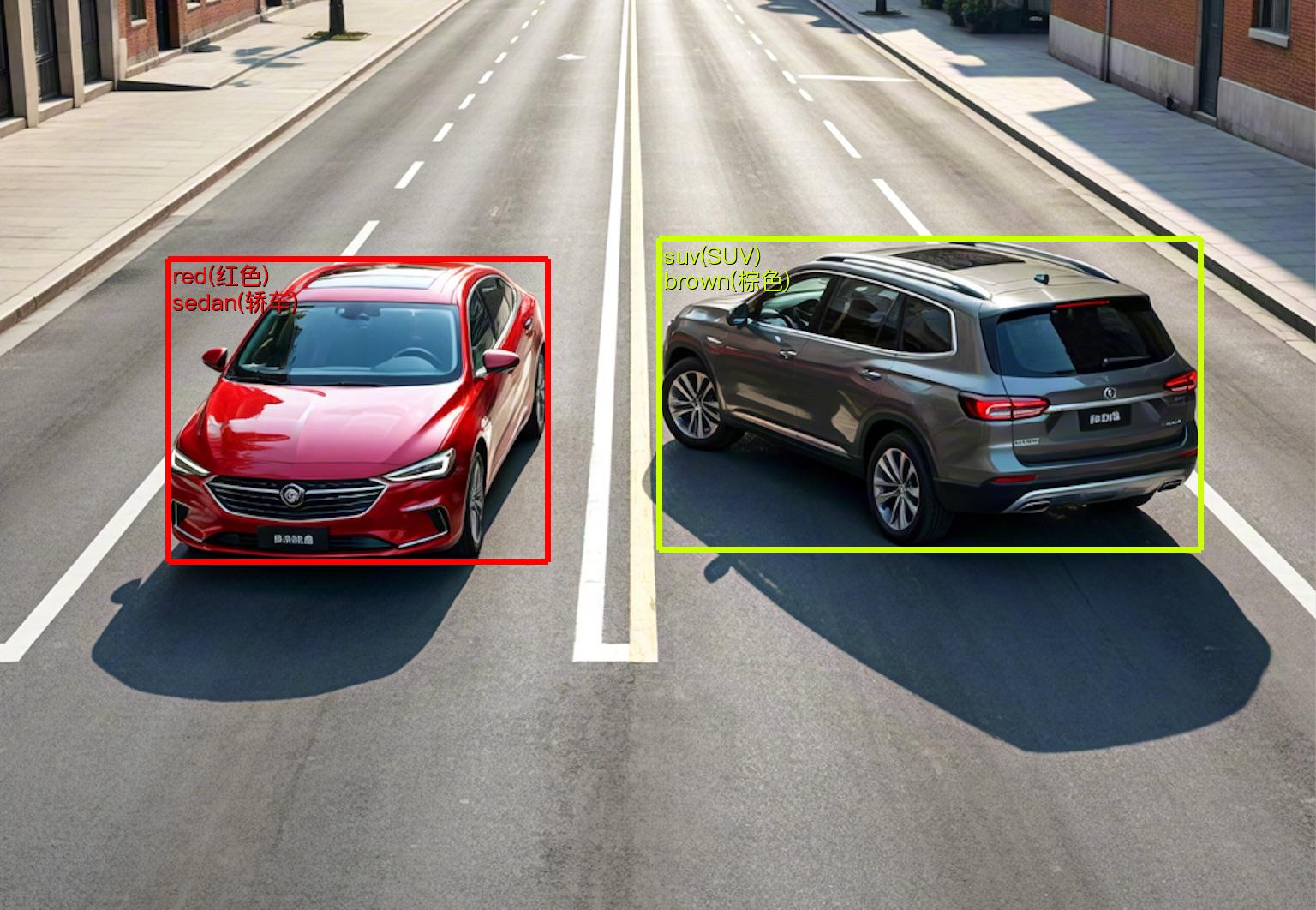
+Vehicle attribute recognition is a crucial component in computer vision systems. Its primary task is to locate and label specific attributes of vehicles in images or videos, such as vehicle type, color, and license plate number. This task not only requires accurately detecting vehicles but also identifying detailed attribute information for each vehicle. The vehicle attribute recognition pipeline is an end-to-end serial system for locating and recognizing vehicle attributes, widely used in traffic management, intelligent parking, security surveillance, autonomous driving, and other fields. It significantly enhances system efficiency and intelligence levels, driving the development and innovation of related industries.
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+**The vehicle attribute recognition pipeline includes a vehicle detection module and a vehicle attribute recognition module**, with several models in each module. Which models to use can be selected based on the benchmark data below. **If you prioritize model accuracy, choose models with higher accuracy; if you prioritize inference speed, choose models with faster inference; if you prioritize model storage size, choose models with smaller storage**.
|
|
|
+
|
|
|
+<details>
|
|
|
+ <summary> 👉Model List Details</summary>
|
|
|
+
|
|
|
+**Vehicle Detection Module**:
|
|
|
+
|
|
|
+<table>
|
|
|
+ <tr>
|
|
|
+ <th>Model</th>
|
|
|
+ <th>mAP 0.5:0.95</th>
|
|
|
+ <th>GPU Inference Time (ms)</th>
|
|
|
+ <th>CPU Inference Time (ms)</th>
|
|
|
+ <th>Model Size (M)</th>
|
|
|
+ <th>Description</th>
|
|
|
+ </tr>
|
|
|
+ <tr>
|
|
|
+ <td>PP-YOLOE-S_vehicle</td>
|
|
|
+ <td>61.3</td>
|
|
|
+ <td>15.4</td>
|
|
|
+ <td>178.4</td>
|
|
|
+ <td>28.79</td>
|
|
|
+ <td rowspan="2">Vehicle detection model based on PP-YOLOE</td>
|
|
|
+ </tr>
|
|
|
+ <tr>
|
|
|
+ <td>PP-YOLOE-L_vehicle</td>
|
|
|
+ <td>63.9</td>
|
|
|
+ <td>32.6</td>
|
|
|
+ <td>775.6</td>
|
|
|
+ <td>196.02</td>
|
|
|
+ </tr>
|
|
|
+</table>
|
|
|
+
|
|
|
+**Note: The above accuracy metrics are mAP(0.5:0.95) on the PPVehicle validation set. All GPU inference times are based on an NVIDIA Tesla T4 machine with FP32 precision. CPU inference speeds are based on an Intel(R) Xeon(R) Gold 5117 CPU @ 2.00GHz with 8 threads and FP32 precision.**
|
|
|
+
|
|
|
+**Vehicle Attribute Recognition Module**:
|
|
|
+
|
|
|
+|Model|mA (%)|GPU Inference Time (ms)|CPU Inference Time (ms)|Model Size (M)|Description|
|
|
|
+|-|-|-|-|-|-|
|
|
|
+|PP-LCNet_x1_0_vehicle_attribute|91.7|3.84845|9.23735|6.7 M|PP-LCNet_x1_0_vehicle_attribute is a lightweight vehicle attribute recognition model based on PP-LCNet.|
|
|
|
+
|
|
|
+**Note: The above accuracy metrics are mA on the VeRi dataset. GPU inference times are based on an NVIDIA Tesla T4 machine with FP32 precision. CPU inference speeds are based on an Intel(R) Xeon(R) Gold 5117 CPU @ 2.00GHz with 8 threads and FP32 precision.**
|
|
|
+
|
|
|
+</details>
|
|
|
+
|
|
|
+## 2. Quick Start
|
|
|
+The pre-trained models provided by PaddleX can quickly demonstrate results. You can experience the effects of the vehicle attribute recognition pipeline online or locally using command line or Python.
|
|
|
+
|
|
|
+### 2.1 Online Experience
|
|
|
+Not supported yet.
|
|
|
+
|
|
|
+### 2.2 Local Experience
|
|
|
+Before using the vehicle attribute recognition pipeline locally, ensure you have installed the PaddleX wheel package according to the [PaddleX Local Installation Tutorial](../../../installation/installation_en.md).
|
|
|
+
|
|
|
+#### 2.2.1 Experience via Command Line
|
|
|
+You can quickly experience the vehicle attribute recognition pipeline with a single command. Use the [test file](https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/vehicle_attribute_002.jpg) and replace `--input` with the local path for prediction.
|
|
|
+
|
|
|
+```bash
|
|
|
+paddlex --pipeline vehicle_attribute_recognition --input vehicle_attribute_002.jpg --device gpu:0
|
|
|
+```
|
|
|
+Parameter Description:
|
|
|
+
|
|
|
+```
|
|
|
+--pipeline: The name of the pipeline, here it is the vehicle attribute recognition pipeline.
|
|
|
+--input: The local path or URL of the input image to be processed.
|
|
|
+--device: The index of the GPU to use (e.g., gpu:0 means using the first GPU, gpu:1,2 means using the second and third GPUs). You can also choose to use the CPU (--device cpu).
|
|
|
+```
|
|
|
+
|
|
|
+When executing the above Python script, the default vehicle attribute recognition pipeline configuration file is loaded. If you need a custom configuration file, you can run the following command to obtain it:
|
|
|
+
|
|
|
+<details>
|
|
|
+ <summary> 👉Click to Expand</summary>
|
|
|
+
|
|
|
+```
|
|
|
+paddlex --get_pipeline_config vehicle_attribute_recognition
|
|
|
+```
|
|
|
+After execution, the vehicle attribute recognition pipeline configuration file will be saved in the current directory. If you wish to specify a custom save location, you can run the following command (assuming the custom save location is `./my_path`):
|
|
|
+
|
|
|
+```
|
|
|
+paddlex --get_pipeline_config vehicle_attribute_recognition --save_path ./my_path
|
|
|
+```
|
|
|
+
|
|
|
+After obtaining the pipeline configuration file, you can replace `--pipeline` with the saved path of the configuration file to make it effective. For example, if the saved path of the configuration file is `./vehicle_attribute_recognition.yaml`, just execute:
|
|
|
+
|
|
|
+```bash
|
|
|
+paddlex --pipeline ./vehicle_attribute_recognition.yaml --input vehicle_attribute_002.jpg --device gpu:0
|
|
|
+```
|
|
|
+Among them, parameters such as `--model` and `--device` do not need to be specified, and the parameters in the configuration file will be used. If parameters are still specified, the specified parameters will take precedence.
|
|
|
+
|
|
|
+</details>
|
|
|
+
|
|
|
+#### 2.2.2 Integrating via Python Script
|
|
|
+A few lines of code suffice for rapid inference on the production line, taking the vehicle attribute recognition pipeline as an example:
|
|
|
+
|
|
|
+```python
|
|
|
+from paddlex import create_pipeline
|
|
|
+
|
|
|
+pipeline = create_pipeline(pipeline="vehicle_attribute_recognition")
|
|
|
+
|
|
|
+output = pipeline.predict("vehicle_attribute_002.jpg")
|
|
|
+for res in output:
|
|
|
+ res.print() ## Print the structured output of the prediction
|
|
|
+ res.save_to_img("./output/") ## Save the visualized result image
|
|
|
+ res.save_to_json("./output/") ## Save the structured output of the prediction
|
|
|
+```
|
|
|
+The results obtained are the same as those from the command line method.
|
|
|
+
|
|
|
+In the above Python script, the following steps are executed:
|
|
|
+
|
|
|
+(1) Instantiate the `create_pipeline` to create a pipeline object: Specific parameter descriptions are as follows:
|
|
|
+
|
|
|
+| Parameter | Description | Parameter Type | Default Value |
|
|
|
+|-|-|-|-|
|
|
|
+| `pipeline` | The name of the pipeline or the path to the pipeline configuration file. If it is the name of the pipeline, it must be a pipeline supported by PaddleX. | `str` | None |
|
|
|
+| `device` | The device for pipeline model inference. Supports: "gpu", "cpu". | `str` | "gpu" |
|
|
|
+| `use_hpip` | Whether to enable high-performance inference, only available when the pipeline supports high-performance inference. | `bool` | `False` |
|
|
|
+
|
|
|
+(2) Call the `predict` method of the vehicle attribute recognition pipeline object for inference prediction: The `predict` method parameter is `x`, which is used to input data to be predicted, supporting multiple input methods. Specific examples are as follows:
|
|
|
+
|
|
|
+| Parameter Type | Description |
|
|
|
+|----------------|-----------------------------------------------------------------------------------------------------------|
|
|
|
+| Python Var | Supports directly passing in Python variables, such as image data represented by numpy.ndarray. |
|
|
|
+| `str` | Supports passing in the file path of the data to be predicted, such as the local path of an image file: `/root/data/img.jpg`. |
|
|
|
+| `str` | Supports passing in the URL of the data file to be predicted, such as the network URL of an image file: [Example](https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/vehicle_attribute_002.jpg). |
|
|
|
+| `str` | Supports passing in a local directory, which should contain data files to be predicted, such as the local path: `/root/data/`. |
|
|
|
+| `dict` | Supports passing in a dictionary type, where the key needs to correspond to the specific task, such as "img" for the vehicle attribute recognition task, and the value of the dictionary supports the above data types, for example: `{"img": "/root/data1"}`. |
|
|
|
+| `list` | Supports passing in a list, where the elements of the list need to be the above data types, such as `[numpy.ndarray, numpy.ndarray], ["/root/data/img1.jpg", "/root/data/img2.jpg"], ["/root/data1", "/root/data2"], [{"img": "/root/data1"}, {"img": "/root/data2/img.jpg"}]`. |
|
|
|
+
|
|
|
+(3) Obtain the prediction results by calling the `predict` method: The `predict` method is a `generator`, so prediction results need to be obtained through iteration. The `predict` method predicts data in batches, so the prediction results are in the form of a list representing a set of prediction results.
|
|
|
+
|
|
|
+(4) Processing the Prediction Results: The prediction result for each sample is in `dict` format, which supports printing or saving to a file. The supported file types for saving depend on the specific pipeline, such as:
|
|
|
+
|
|
|
+| Method | Description | Method Parameters |
|
|
|
+|----------------|-------------------------------|----------------------------------------------------------------------------------------------------------|
|
|
|
+| print | Print results to the terminal | `- format_json`: bool, whether to format the output content with json indentation, default is True;<br>`- indent`: int, json formatting setting, only effective when format_json is True, default is 4;<br>`- ensure_ascii`: bool, json formatting setting, only effective when format_json is True, default is False; |
|
|
|
+| save_to_json | Save results as a json file | `- save_path`: str, the path to save the file, when it is a directory, the saved file name is consistent with the input file type;<br>`- indent`: int, json formatting setting, default is 4;<br>`- ensure_ascii`: bool, json formatting setting, default is False; |
|
|
|
+| save_to_img | Save results as an image file | `- save_path`: str, the path to save the file, when it is a directory, the saved file name is consistent with the input file type; |
|
|
|
+
|
|
|
+If you have obtained the configuration file, you can customize the configurations for the vehicle attribute recognition pipeline by simply modifying the `pipeline` parameter in the `create_pipeline` method to the path of your pipeline configuration file.
|
|
|
+
|
|
|
+For example, if your configuration file is saved at `./my_path/vehicle_attribute_recognition.yaml`, you only need to execute:
|
|
|
+
|
|
|
+```python
|
|
|
+from paddlex import create_pipeline
|
|
|
+pipeline = create_pipeline(pipeline="./my_path/vehicle_attribute_recognition.yaml")
|
|
|
+output = pipeline.predict("vehicle_attribute_002.jpg")
|
|
|
+for res in output:
|
|
|
+ res.print() # Print the structured output of the prediction
|
|
|
+ res.save_to_img("./output/") # Save the visualized result image
|
|
|
+ res.save_to_json("./output/") # Save the structured output of the prediction
|
|
|
+```
|
|
|
+
|
|
|
+## 3. Development Integration/Deployment
|
|
|
+If the face recognition pipeline meets your requirements for inference speed and accuracy, you can proceed directly with development integration/deployment.
|
|
|
+
|
|
|
+If you need to directly apply the face recognition pipeline in your Python project, you can refer to the example code in [2.2.2 Python Script Integration](#222-python-script-integration).
|
|
|
+
|
|
|
+Additionally, PaddleX provides three other deployment methods, detailed as follows:
|
|
|
+
|
|
|
+🚀 **High-Performance Inference**: In actual production environments, many applications have stringent standards for the performance metrics of deployment strategies (especially response speed) to ensure efficient system operation and smooth user experience. To this end, PaddleX provides high-performance inference plugins aimed at deeply optimizing model inference and pre/post-processing to significantly speed up the end-to-end process. For detailed high-performance inference procedures, please refer to the [PaddleX High-Performance Inference Guide](../../../pipeline_deploy/high_performance_inference.md).
|
|
|
+
|
|
|
+☁️ **Service-Oriented Deployment**: Service-oriented deployment is a common deployment form in actual production environments. By encapsulating inference functionality as services, clients can access these services through network requests to obtain inference results. PaddleX supports users in achieving service-oriented deployment of pipelines at low cost. For detailed service-oriented deployment procedures, please refer to the [PaddleX Service-Oriented Deployment Guide](../../../pipeline_deploy/service_deploy.md).
|
|
|
+
|
|
|
+Below are the API reference and multi-language service invocation examples:
|
|
|
+
|
|
|
+<details>
|
|
|
+<summary>API Reference</summary>
|
|
|
+
|
|
|
+For all operations provided by the service:
|
|
|
+
|
|
|
+- The response body and the request body of POST requests are both JSON data (JSON objects).
|
|
|
+- When the request is successfully processed, the response status code is `200`, and the attributes of the response body are as follows:
|
|
|
+
|
|
|
+ | Name | Type | Meaning |
|
|
|
+ |-|-|-|
|
|
|
+ |`errorCode`|`integer`|Error code. Fixed to `0`. |
|
|
|
+ |`errorMsg`|`string`|Error description. Fixed to `"Success"`. |
|
|
|
+
|
|
|
+ The response body may also have a `result` attribute of type `object`, which stores the operation result information.
|
|
|
+
|
|
|
+- When the request is not successfully processed, the attributes of the response body are as follows:
|
|
|
+
|
|
|
+ | Name | Type | Meaning |
|
|
|
+ |-|-|-|
|
|
|
+ |`errorCode`|`integer`|Error code. Same as the response status code. |
|
|
|
+ |`errorMsg`|`string`|Error description. |
|
|
|
+
|
|
|
+The operations provided by the service are as follows:
|
|
|
+
|
|
|
+- **`infer`**
|
|
|
+
|
|
|
+ Obtain OCR results for an image.
|
|
|
+
|
|
|
+ `POST /ocr`
|
|
|
+
|
|
|
+ - The attributes of the request body are as follows:
|
|
|
+
|
|
|
+ | Name | Type | Meaning | Required |
|
|
|
+ |-|-|-|-|
|
|
|
+ |`image`|`string`|The URL of an accessible image file or the Base64 encoded result of the image file content. |Yes|
|
|
|
+ |`inferenceParams`|`object`|Inference parameters. |No|
|
|
|
+
|
|
|
+ The attributes of```markdown
|
|
|
+<details>
|
|
|
+<summary>Python</summary>
|
|
|
+
|
|
|
+```python
|
|
|
+import base64
|
|
|
+import requests
|
|
|
+
|
|
|
+API_URL = "http://localhost:8080/ocr" # Service URL
|
|
|
+image_path = "./demo.jpg"
|
|
|
+output_image_path = "./out.jpg"
|
|
|
+
|
|
|
+# Encode the local image to Base64
|
|
|
+with open(image_path, "rb") as file:
|
|
|
+ image_bytes = file.read()
|
|
|
+ image_data = base64.b64encode(image_bytes).decode("ascii")
|
|
|
+
|
|
|
+payload = {"image": image_data} # Base64 encoded file content or image URL
|
|
|
+
|
|
|
+# Call the API
|
|
|
+response = requests.post(API_URL, json=payload)
|
|
|
+
|
|
|
+# Process the response data
|
|
|
+assert response.status_code == 200
|
|
|
+result = response.json()["result"]
|
|
|
+with open(output_image_path, "wb") as file:
|
|
|
+ file.write(base64.b64decode(result["image"]))
|
|
|
+print(f"Output image saved at {output_image_path}")
|
|
|
+print("\nDetected texts:")
|
|
|
+print(result["texts"])
|
|
|
+```
|
|
|
+
|
|
|
+</details>
|
|
|
+
|
|
|
+<details>
|
|
|
+<summary>C++</summary>
|
|
|
+
|
|
|
+```cpp
|
|
|
+#include <iostream>
|
|
|
+#include "cpp-httplib/httplib.h" // https://github.com/Huiyicc/cpp-httplib
|
|
|
+#include "nlohmann/json.hpp" // https://github.com/nlohmann/json
|
|
|
+#include "base64.hpp" // https://github.com/tobiaslocker/base64
|
|
|
+
|
|
|
+int main() {
|
|
|
+ httplib::Client client("localhost:8080");
|
|
|
+ const std::string imagePath = "./demo.jpg";
|
|
|
+ const std::string outputImagePath = "./out.jpg";
|
|
|
+
|
|
|
+ httplib::Headers headers = {
|
|
|
+ {"Content-Type", "application/json"}
|
|
|
+ };
|
|
|
+
|
|
|
+ // Encode the local image to Base64
|
|
|
+ std::ifstream file(imagePath, std::ios::binary | std::ios::ate);
|
|
|
+ std::streamsize size = file.tellg();
|
|
|
+ file.seekg(0, std::ios::beg);
|
|
|
+
|
|
|
+ std::vector<char> buffer(size);
|
|
|
+ if (!file.read(buffer.data(), size)) {
|
|
|
+ std::cerr << "Error reading file." << std::endl;
|
|
|
+ return 1;
|
|
|
+ }
|
|
|
+ std::string bufferStr(reinterpret_cast<const char*>(buffer.data()), buffer.size());
|
|
|
+ std::string encodedImage = base64::to_base64(bufferStr);
|
|
|
+
|
|
|
+ nlohmann::json jsonObj;
|
|
|
+ jsonObj["image"] = encodedImage;
|
|
|
+ std::string body = jsonObj.dump();
|
|
|
+
|
|
|
+ // Call the API
|
|
|
+ auto response = client.Post("/ocr", headers, body, "application/json");
|
|
|
+ // Process the response data
|
|
|
+ if (response && response->status == 200) {
|
|
|
+ nlohmann::json jsonResponse = nlohmann::json::parse(response->body);
|
|
|
+ auto result = jsonResponse["result"];
|
|
|
+
|
|
|
+ encodedImage = result["image"];
|
|
|
+ std::string decodedString = base64::from_base64(encodedImage);
|
|
|
+ std::vector<unsigned char> decodedImage(decodedString.begin(), decodedString.end());
|
|
|
+ std::ofstream outputImage(outputImagePath, std::ios::binary | std::ios::out);
|
|
|
+ if (outputImage.is_open()) {
|
|
|
+ outputImage.write(reinterpret_cast<char*>(decodedImage.data()), decodedImage.size());
|
|
|
+ outputImage.close();
|
|
|
+ std::cout << "Output image saved at " << outputImagePath << std::endl;
|
|
|
+ } else {
|
|
|
+ std::cerr << "Unable to open file for writing: " << outputImagePath << std::endl;
|
|
|
+ }
|
|
|
+
|
|
|
+ auto texts = result["texts"];
|
|
|
+ std::cout << "\nDetected texts:" << std::endl;
|
|
|
+ for (const auto& text : texts) {
|
|
|
+ std::cout << text << std::endl;
|
|
|
+ }
|
|
|
+ } else {
|
|
|
+ std::cout << "Failed to send HTTP request." << std::endl;
|
|
|
+ return 1;
|
|
|
+ }
|
|
|
+
|
|
|
+ return 0;
|
|
|
+}
|
|
|
+
|
|
|
+```
|
|
|
+
|
|
|
+</details>
|
|
|
+``````markdown
|
|
|
+# Tutorial on Artificial Intelligence and Computer Vision
|
|
|
+
|
|
|
+This tutorial, intended for numerous developers, covers the basics and applications of AI and Computer Vision.
|
|
|
+
|
|
|
+<details>
|
|
|
+<summary>Java</summary>
|
|
|
+
|
|
|
+```java
|
|
|
+import okhttp3.*;
|
|
|
+import com.fasterxml.jackson.databind.ObjectMapper;
|
|
|
+import com.fasterxml.jackson.databind.JsonNode;
|
|
|
+import com.fasterxml.jackson.databind.node.ObjectNode;
|
|
|
+
|
|
|
+import java.io.File;
|
|
|
+import java.io.FileOutputStream;
|
|
|
+import java.io.IOException;
|
|
|
+import java.util.Base64;
|
|
|
+
|
|
|
+public class Main {
|
|
|
+ public static void main(String[] args) throws IOException {
|
|
|
+ String API_URL = "http://localhost:8080/ocr"; // Service URL
|
|
|
+ String imagePath = "./demo.jpg"; // Local image path
|
|
|
+ String outputImagePath = "./out.jpg"; // Output image path
|
|
|
+
|
|
|
+ // Encode the local image to Base64
|
|
|
+ File file = new File(imagePath);
|
|
|
+ byte[] fileContent = java.nio.file.Files.readAllBytes(file.toPath());
|
|
|
+ String imageData = Base64.getEncoder().encodeToString(fileContent);
|
|
|
+
|
|
|
+ ObjectMapper objectMapper = new ObjectMapper();
|
|
|
+ ObjectNode params = objectMapper.createObjectNode();
|
|
|
+ params.put("image", imageData); // Base64-encoded file content or image URL
|
|
|
+
|
|
|
+ // Create an OkHttpClient instance
|
|
|
+ OkHttpClient client = new OkHttpClient();
|
|
|
+ MediaType JSON = MediaType.get("application/json; charset=utf-8");
|
|
|
+ RequestBody body = RequestBody.create(params.toString(), JSON);
|
|
|
+ Request request = new Request.Builder()
|
|
|
+ .url(API_URL)
|
|
|
+ .post(body)
|
|
|
+ .build();
|
|
|
+
|
|
|
+ // Call the API and process the response
|
|
|
+ try (Response response = client.newCall(request).execute()) {
|
|
|
+ if (response.isSuccessful()) {
|
|
|
+ String responseBody = response.body().string();
|
|
|
+ JsonNode resultNode = objectMapper.readTree(responseBody);
|
|
|
+ JsonNode result = resultNode.get("result");
|
|
|
+ String base64Image = result.get("image").asText();
|
|
|
+ JsonNode texts = result.get("texts");
|
|
|
+
|
|
|
+ byte[] imageBytes = Base64.getDecoder().decode(base64Image);
|
|
|
+ try (FileOutputStream fos = new FileOutputStream(outputImagePath)) {
|
|
|
+ fos.write(imageBytes);
|
|
|
+ }
|
|
|
+ System.out.println("Output image saved at " + outputImagePath);
|
|
|
+ System.out.println("\nDetected texts: " + texts.toString());
|
|
|
+ } else {
|
|
|
+ System.err.println("Request failed with code: " + response.code());
|
|
|
+ }
|
|
|
+ }
|
|
|
+ }
|
|
|
+}
|
|
|
+```
|
|
|
+
|
|
|
+</details>
|
|
|
+
|
|
|
+<details>
|
|
|
+<summary>Go</summary>
|
|
|
+
|
|
|
+```go
|
|
|
+package main
|
|
|
+
|
|
|
+import (
|
|
|
+ "bytes"
|
|
|
+ "encoding/base64"
|
|
|
+ "encoding/json"
|
|
|
+ "fmt"
|
|
|
+ "io/ioutil"
|
|
|
+ "net/http"
|
|
|
+)
|
|
|
+
|
|
|
+func main() {
|
|
|
+ API_URL := "http://localhost:8080/ocr"
|
|
|
+ imagePath := "./demo.jpg"
|
|
|
+ outputImagePath := "./out.jpg"
|
|
|
+
|
|
|
+ // Encode the local image to Base64
|
|
|
+ imageBytes, err := ioutil.ReadFile(imagePath)
|
|
|
+ if err != nil {
|
|
|
+ fmt.Println("Error reading image file:", err)
|
|
|
+ return
|
|
|
+ }
|
|
|
+ imageData := base64.StdEncoding.EncodeToString(imageBytes)
|
|
|
+
|
|
|
+ payload := map[string]string{"image": imageData} // Base64-encoded file content or image URL
|
|
|
+ payloadBytes, err := json.Marshal(payload)
|
|
|
+ if err != nil {
|
|
|
+ fmt.Println("Error marshaling payload:", err)
|
|
|
+ return
|
|
|
+ }
|
|
|
+
|
|
|
+ // Call the API
|
|
|
+ client := &http.Client{}
|
|
|
+ req, err := http.NewRequest("POST", API_URL, bytes.NewBuffer(payloadBytes))
|
|
|
+ if err != nil {
|
|
|
+ fmt.Println("Error creating request:", err)
|
|
|
+ return
|
|
|
+ }
|
|
|
+
|
|
|
+ res, err := client.Do(req)
|
|
|
+ if err != nil {
|
|
|
+ fmt.Println("Error sending request:", err)
|
|
|
+ return
|
|
|
+ }
|
|
|
+ defer res.Body.Close()
|
|
|
+
|
|
|
+ // Process the response
|
|
|
+ body, err := ioutil.ReadAll(res.Body)
|
|
|
+ if err != nil {
|
|
|
+ fmt.Println("Error reading response body:", err)
|
|
|
+ return
|
|
|
+ }```markdown
|
|
|
+# An English Tutorial on Artificial Intelligence and Computer Vision
|
|
|
+
|
|
|
+This tutorial document is intended for numerous developers and covers content related to artificial intelligence and computer vision.
|
|
|
+
|
|
|
+<details>
|
|
|
+<summary>C#</summary>
|
|
|
+
|
|
|
+```csharp
|
|
|
+using System;
|
|
|
+using System.IO;
|
|
|
+using System.Net.Http;
|
|
|
+using System.Net.Http.Headers;
|
|
|
+using System.Text;
|
|
|
+using System.Threading.Tasks;
|
|
|
+using Newtonsoft.Json.Linq;
|
|
|
+
|
|
|
+class Program
|
|
|
+{
|
|
|
+ static readonly string API_URL = "http://localhost:8080/ocr";
|
|
|
+ static readonly string imagePath = "./demo.jpg";
|
|
|
+ static readonly string outputImagePath = "./out.jpg";
|
|
|
+
|
|
|
+ static async Task Main(string[] args)
|
|
|
+ {
|
|
|
+ var httpClient = new HttpClient();
|
|
|
+
|
|
|
+ // Encode the local image to Base64
|
|
|
+ byte[] imageBytes = File.ReadAllBytes(imagePath);
|
|
|
+ string image_data = Convert.ToBase64String(imageBytes);
|
|
|
+
|
|
|
+ var payload = new JObject{ { "image", image_data } }; // Base64 encoded file content or image URL
|
|
|
+ var content = new StringContent(payload.ToString(), Encoding.UTF8, "application/json");
|
|
|
+
|
|
|
+ // Call the API
|
|
|
+ HttpResponseMessage response = await httpClient.PostAsync(API_URL, content);
|
|
|
+ response.EnsureSuccessStatusCode();
|
|
|
+
|
|
|
+ // Process the API response
|
|
|
+ string responseBody = await response.Content.ReadAsStringAsync();
|
|
|
+ JObject jsonResponse = JObject.Parse(responseBody);
|
|
|
+
|
|
|
+ string base64Image = jsonResponse["result"]["image"].ToString();
|
|
|
+ byte[] outputImageBytes = Convert.FromBase64String(base64Image);
|
|
|
+
|
|
|
+ File.WriteAllBytes(outputImagePath, outputImageBytes);
|
|
|
+ Console.WriteLine($"Output image saved at {outputImagePath}");
|
|
|
+ Console.WriteLine("\nDetected texts:");
|
|
|
+ Console.WriteLine(jsonResponse["result"]["texts"].ToString());
|
|
|
+ }
|
|
|
+}
|
|
|
+```
|
|
|
+
|
|
|
+</details>
|
|
|
+
|
|
|
+<details>
|
|
|
+<summary>Node.js</summary>
|
|
|
+
|
|
|
+```js
|
|
|
+const axios = require('axios');
|
|
|
+const fs = require('fs');
|
|
|
+
|
|
|
+const API_URL = 'http://localhost:8080/ocr';
|
|
|
+const imagePath = './demo.jpg';
|
|
|
+const outputImagePath = "./out.jpg";
|
|
|
+
|
|
|
+let config = {
|
|
|
+ method: 'POST',
|
|
|
+ maxBodyLength: Infinity,
|
|
|
+ url: API_URL,
|
|
|
+ data: JSON.stringify({
|
|
|
+ 'image': encodeImageToBase64(imagePath) // Base64 encoded file content or image URL
|
|
|
+ })
|
|
|
+};
|
|
|
+
|
|
|
+// Encode the local image to Base64
|
|
|
+function encodeImageToBase64(filePath) {
|
|
|
+ const bitmap = fs.readFileSync(filePath);
|
|
|
+ return Buffer.from(bitmap).toString('base64');
|
|
|
+}
|
|
|
+
|
|
|
+// Call the API
|
|
|
+axios.request(config)
|
|
|
+.then((response) => {
|
|
|
+ // Process the API response
|
|
|
+ const result = response.data["result"];
|
|
|
+ const imageBuffer = Buffer.from(result["image"], 'base64');
|
|
|
+ fs.writeFile(outputImagePath, imageBuffer, (err) => {
|
|
|
+ if (err) throw err;
|
|
|
+ console.log(`Output image saved at ${outputImagePath}`);
|
|
|
+ });
|
|
|
+ console.log("\nDetected texts:");
|
|
|
+ console.log(result["texts"]);
|
|
|
+})
|
|
|
+.catch((error) => {
|
|
|
+ console.log(error);
|
|
|
+});
|
|
|
+```
|
|
|
+
|
|
|
+</details>
|
|
|
+
|
|
|
+<details>
|
|
|
+<summary>PHP</summary>
|
|
|
+
|
|
|
+```php
|
|
|
+<?php
|
|
|
+
|
|
|
+$API_URL = "http://localhost:8080/ocr"; // Service URL
|
|
|
+$image_path = "./demo.jpg";
|
|
|
+$output_image_path = "./out.jpg";
|
|
|
+
|
|
|
+// Encode the local image to Base64
|
|
|
+$image_data = base64_encode(file_get_contents($image_path));
|
|
|
+$payload = array("image" => $image_data); // Base64 encoded file content or image URL
|
|
|
+
|
|
|
+// Call the API
|
|
|
+$ch = curl_init($API_URL);
|
|
|
+curl_setopt($ch, CURLOPT_POST, true);
|
|
|
+curl_setopt($ch, CURLOPT_POSTFIELDS, json_encode($payload));
|
|
|
+curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
|
|
|
+$response = curl_exec($ch);
|
|
|
+curl_close($ch);
|
|
|
+
|
|
|
+// Process the API response
|
|
|
+$result = json_decode($response, true)["result"];
|
|
|
+file_put_contents($output
|
|
|
+```
|
|
|
+
|
|
|
+<details>
|
|
|
+<details>
|
|
|
+<br/>
|
|
|
+
|
|
|
+📱 **Edge Deployment**: Edge deployment is a method where computing and data processing functions are placed on the user's device itself, allowing the device to process data directly without relying on remote servers. PaddleX supports deploying models on edge devices such as Android. For detailed edge deployment procedures, please refer to the [PaddleX Edge Deployment Guide](../../../pipeline_deploy/edge_deploy_en.md).
|
|
|
+You can choose an appropriate method to deploy your model pipeline based on your needs, and proceed with subsequent AI application integration.
|
|
|
+
|
|
|
+
|
|
|
+## 4. Custom Development
|
|
|
+If the default model weights provided by the Face Recognition Pipeline do not meet your expectations in terms of accuracy or speed for your specific scenario, you can try to further **fine-tune** the existing models using **your own domain-specific or application-specific data** to enhance the recognition performance of the pipeline in your scenario.
|
|
|
+
|
|
|
+### 4.1 Model Fine-tuning
|
|
|
+Since the Face Recognition Pipeline consists of two modules (face detection and face recognition), the suboptimal performance of the pipeline may stem from either module.
|
|
|
+
|
|
|
+You can analyze images with poor recognition results. If you find that many faces are not detected during the analysis, it may indicate deficiencies in the face detection model. In this case, you need to refer to the [Custom Development](../../../module_usage/tutorials/cv_modules/face_detection_en.md#IV.-Custom-Development) section in the [Face Detection Module Development Tutorial](../../../module_usage/tutorials/cv_modules/face_detection_en.md) and use your private dataset to fine-tune the face detection model. If matching errors occur in detected faces, it suggests that the face feature model needs further improvement. You should refer to the [Custom Development](../../../module_usage/tutorials/cv_modules/face_feature_en.md#IV.-Custom-Development) section in the [Face Feature Module Development Tutorial](../../../module_usage/tutorials/cv_modules/face_feature_en.md) to fine-tune the face feature model.
|
|
|
+
|
|
|
+### 4.2 Model Application
|
|
|
+After completing fine-tuning training with your private dataset, you will obtain local model weight files.
|
|
|
+
|
|
|
+To use the fine-tuned model weights, you only need to modify the pipeline configuration file by replacing the local paths of the fine-tuned model weights with the corresponding paths in the pipeline configuration file:
|
|
|
+
|
|
|
+```bash
|
|
|
+
|
|
|
+......
|
|
|
+Pipeline:
|
|
|
+ device: "gpu:0"
|
|
|
+ det_model: "BlazeFace" # Can be modified to the local path of the fine-tuned face detection model
|
|
|
+ rec_model: "MobileFaceNet" # Can be modified to the local path of the fine-tuned face recognition model
|
|
|
+ det_batch_size: 1
|
|
|
+ rec_batch_size: 1
|
|
|
+ device: gpu
|
|
|
+......
|
|
|
+```
|
|
|
+Subsequently, refer to the command-line method or Python script method in [2.2 Local Experience](#22-Local-Experience) to load the modified pipeline configuration file.
|
|
|
+Note: Currently, setting separate `batch_size` for face detection and face recognition models is not supported.
|
|
|
+
|
|
|
+## 5. Multi-hardware Support
|
|
|
+PaddleX supports various mainstream hardware devices such as NVIDIA GPUs, Kunlun XPU, Ascend NPU, and Cambricon MLU. **Simply modifying the `--device` parameter** allows seamless switching between different hardware.
|
|
|
+
|
|
|
+For example, when running the face recognition pipeline using Python and changing the running device from an NVIDIA GPU to an Ascend NPU, you only need to modify the `device` in the script to `npu`:
|
|
|
+
|
|
|
+```python
|
|
|
+from paddlex import create_pipeline
|
|
|
+
|
|
|
+pipeline = create_pipeline(
|
|
|
+ pipeline="face_recognition",
|
|
|
+ device="npu:0" # gpu:0 --> npu:0
|
|
|
+)
|
|
|
+```
|
|
|
+If you want to use the face recognition pipeline on more types of hardware, please refer to the [PaddleX Multi-device Usage Guide](../../../other_devices_support/multi_devices_use_guide_en.md).
|

 zhangyubo0722
zhangyubo0722