| Parameter |
Description |
Type |
Options |
Default Value |
input |
Data to be predicted, supports multiple input types, required |
Python Var|str|list |
- Python Var: Such as
numpy.ndarray representing image data
- str: Such as the local path of an image file or PDF file:
/root/data/img.jpg; such as URL link, such as the network URL of an image file or PDF file: Example; such as local directory, the directory must contain the images to be predicted, such as the local path: /root/data/ (currently does not support prediction of PDF files in the directory, PDF files need to be specified to a specific file path)
- List: The list elements must be the above types of data, such as
[numpy.ndarray, numpy.ndarray], ["/root/data/img1.jpg", "/root/data/img2.jpg"], ["/root/data1", "/root/data2"]
|
None |
device |
Pipeline inference device |
str|None |
- CPU: Such as
cpu indicating using CPU for inference;
- GPU: Such as
gpu:0 indicating using the 1st GPU for inference;
- NPU: Such as
npu:0 indicating using the 1st NPU for inference;
- XPU: Such as
xpu:0 indicating using the 1st XPU for inference;
- MLU: Such as
mlu:0 indicating using the 1st MLU for inference;
- DCU: Such as
dcu:0 indicating using the 1st DCU for inference;
- None: If set to
None, it will default to using the parameter value initialized by the pipeline. During initialization, it will preferentially use the local GPU 0 device, if not available, it will use the CPU device;
|
None |
use_doc_orientation_classify |
Whether to use the document orientation classification module |
bool|None |
- bool:
True or False;
- None: If set to
None, it will default to using the parameter value initialized by the pipeline, initialized to True;
|
None |
use_doc_unwarping |
Whether to use the document unwarping module |
bool|None |
- bool:
True or False;
- None: If set to
None, it will default to using the parameter value initialized by the pipeline, initialized to True;
|
None |
text_det_limit_side_len |
Image side length limit for text detection |
int|None |
- int: Any integer greater than
0;
- None: If set to
None, it will default to using the parameter value initialized by the pipeline, initialized to 960;
|
None |
text_det_limit_type |
Image side length limit type for text detection |
str|None |
- str: Supports
min and max, min indicates ensuring the shortest side of the image is not less than det_limit_side_len, max indicates ensuring the longest side of the image is not greater than limit_side_len
- None: If set to
None, it will default to using the parameter value initialized by the pipeline, initialized to max;
|
None |
text_det_thresh |
Detection pixel threshold, only pixels with scores greater than this threshold in the output probability map will be considered as text pixels |
float|None |
- float: Any floating-point number greater than
0
- None: If set to
None, it will default to using the parameter value initialized by the pipeline 0.3
|
None |
text_det_box_thresh |
Detection box threshold, the result will be considered as a text region if the average score of all pixels within the detection box is greater than this threshold |
float|None |
- float: Any floating-point number greater than
0
- None: If set to
None, it will default to using the parameter value initialized by the pipeline 0.6
|
None |
text_det_unclip_ratio |
Text detection expansion ratio, this method is used to expand the text region, the larger the value, the larger the expanded area |
float|None |
- float: Any floating-point number greater than
0
- None: If set to
None, it will default to using the parameter value initialized by the pipeline 2.0
|
None |
text_rec_score_thresh |
Text recognition threshold, text results with scores greater than this threshold will be retained |
float|None |
- float: Any floating-point number greater than
0
- None: If set to
None, it will default to using the parameter value initialized by the pipeline 0.0, meaning no threshold
|
None |
use_layout_detection |
Whether to use the layout detection module |
bool|None |
- bool:
True or False;
- None: If set to
None, the default value initialized by the pipeline will be used, initialized as True;
|
None |
layout_threshold |
Confidence threshold for layout detection; only scores above this threshold will be output |
float|dict|None |
- float: Any floating-point number greater than
0
- dict: Key is an integer category ID, value is any floating-point number greater than
0
- None: If set to
None, the default value initialized by the pipeline will be used, initialized as 0.5
|
None |
layout_nms |
Whether to use NMS post-processing for layout detection |
bool|None |
- bool:
True or False;
- None: If set to
None, the default value initialized by the pipeline will be used, initialized as True;
|
None |
layout_unclip_ratio |
Scale factor for the side length of detection boxes; if not specified, the default PaddleX official model configuration will be used |
float|list|None |
- float: A floating-point number greater than 0, e.g., 1.1, indicating that the center of the detection box remains unchanged, and both the width and height are scaled by 1.1 times
- list: e.g., [1.2, 1.5], indicating that the center of the detection box remains unchanged, the width is scaled by 1.2 times, and the height is scaled by 1.5 times
- None: If set to
None, the default value initialized by the pipeline will be used, initialized as 1.0
|
layout_merge_bboxes_mode |
Merging mode for detection boxes output by the model; if not specified, the default PaddleX official model configuration will be used |
string|None |
- large: When set to large, only the outermost box will be retained for overlapping detection boxes, and the inner overlapping boxes will be removed.
- small: When set to small, only the innermost boxes will be retained for overlapping detection boxes, and the outer overlapping boxes will be removed.
- union: No filtering of boxes will be performed; both inner and outer boxes will be retained.
- None: If set to
None, the default value initialized by the pipeline will be used, initialized as large
|
None |
(3) Process the prediction results. The prediction result for each sample is of type `dict`, and supports operations such as printing, saving as an image, saving as an `xlsx` file, saving as an `HTML` file, and saving as a `json` file:
| Method |
Description |
Parameter |
Type |
Parameter Description |
Default Value |
print() |
Print the result to the terminal |
format_json |
bool |
Whether to format the output content using JSON indentation |
True |
indent |
int |
Specify the indentation level to beautify the output JSON data, making it more readable. This is only effective when format_json is True |
4 |
ensure_ascii |
bool |
Control whether non-ASCII characters are escaped to Unicode. When set to True, all non-ASCII characters will be escaped; False retains the original characters. This is only effective when format_json is True |
False |
save_to_json() |
Save the result as a JSON file |
save_path |
str |
The file path for saving. When it is a directory, the saved file name will match the input file name |
N/A |
indent |
int |
Specify the indentation level to beautify the output JSON data, making it more readable. This is only effective when format_json is True |
4 |
ensure_ascii |
bool |
Control whether non-ASCII characters are escaped to Unicode. When set to True, all non-ASCII characters will be escaped; False retains the original characters. This is only effective when format_json is True |
False |
save_to_img() |
Save the result as an image file |
save_path |
str |
The file path for saving, supporting both directory and file paths |
N/A |
save_to_xlsx() |
Save the result as an xlsx file |
save_path |
str |
The file path for saving, supporting both directory and file paths |
N/A |
save_to_html() |
Save the result as an HTML file |
save_path |
str |
The file path for saving, supporting both directory and file paths |
N/A |
- Calling the `print()` method will print the result to the terminal, with the printed content explained as follows:
- `input_path`: `(str)` The input path of the image to be predicted
- `model_settings`: `(Dict[str, bool])` Configuration parameters required for the pipeline model
- `use_doc_preprocessor`: `(bool)` Controls whether to enable the document preprocessing sub-pipeline
- `use_layout_detection`: `(bool)` Controls whether to enable the layout detection sub-pipeline
- `use_ocr_model`: `(bool)` Controls whether to enable the OCR sub-pipeline
- `layout_det_res`: `(Dict[str, Union[List[numpy.ndarray], List[float]]])` Output result of the layout detection sub-module. Only exists when `use_layout_detection=True`
- `input_path`: `(Union[str, None])` The image path accepted by the layout detection module, saved as `None` when the input is a `numpy.ndarray`
- `page_index`: `(Union[int, None])` If the input is a PDF file, it indicates the current page number of the PDF, otherwise it is `None`
- `boxes`: `(List[Dict])` List of detection boxes for layout seal regions, each element in the list contains the following fields
- `cls_id`: `(int)` The class ID of the detection box
- `score`: `(float)` The confidence score of the detection box
- `coordinate`: `(List[float])` The coordinates of the four corners of the detection box, in the order of x1, y1, x2, y2, representing the x-coordinate of the top-left corner, the y-coordinate of the top-left corner, the x-coordinate of the bottom-right corner, and the y-coordinate of the bottom-right corner
- `doc_preprocessor_res`: `(Dict[str, Union[str, Dict[str, bool], int]])` The output result of the document preprocessing sub-pipeline. Exists only when `use_doc_preprocessor=True`
- `input_path`: `(Union[str, None])` The image path accepted by the image preprocessing sub-pipeline, saved as `None` when the input is `numpy.ndarray`
- `model_settings`: `(Dict)` Model configuration parameters for the preprocessing sub-pipeline
- `use_doc_orientation_classify`: `(bool)` Controls whether to enable document orientation classification
- `use_doc_unwarping`: `(bool)` Controls whether to enable document unwarping
- `angle`: `(int)` The prediction result of document orientation classification. When enabled, the values are [0,1,2,3], corresponding to [0°,90°,180°,270°] respectively; when not enabled, it is -1
- `dt_polys`: `(List[numpy.ndarray])` List of polygons for text detection. Each detection box is represented by a numpy array of 4 vertex coordinates, with the array shape being (4, 2) and the data type being int16
- `dt_scores`: `(List[float])` List of confidence scores for text detection boxes
- `text_det_params`: `(Dict[str, Dict[str, int, float]])` Configuration parameters for the text detection module
- `limit_side_len`: `(int)` The side length limit value during image preprocessing
- `limit_type`: `(str)` The processing method for the side length limit
- `thresh`: `(float)` Confidence threshold for text pixel classification
- `box_thresh`: `(float)` Confidence threshold for text detection boxes
- `unclip_ratio`: `(float)` Expansion coefficient for text detection boxes
- `text_type`: `(str)` Type of text detection, currently fixed as "general"
- `text_rec_score_thresh`: `(float)` Filtering threshold for text recognition results
- `rec_texts`: `(List[str])` List of text recognition results, only includes texts with confidence scores exceeding `text_rec_score_thresh`
- `rec_scores`: `(List[float])` List of confidence scores for text recognition, filtered by `text_rec_score_thresh`
- `rec_polys`: `(List[numpy.ndarray])` List of text detection boxes after confidence filtering, same format as `dt_polys`
- `rec_boxes`: `(numpy.ndarray)` Array of rectangular bounding boxes for detection boxes, with shape (n, 4) and dtype int16. Each row represents the [x_min, y_min, x_max, y_max] coordinates of a rectangle, where (x_min, y_min) is the top-left coordinate and (x_max, y_max) is the bottom-right coordinate
- Calling the `save_to_json()` method will save the above content to the specified `save_path`. If specified as a directory, the saved path will be `save_path/{your_img_basename}.json`; if specified as a file, it will be saved directly to that file. Since JSON files do not support saving numpy arrays, the `numpy.array` types will be converted to lists.
- Calling the `save_to_img()` method will save the visualization results to the specified `save_path`. If specified as a directory, the saved path will be `save_path/{your_img_basename}_ocr_res_img.{your_img_extension}`; if specified as a file, it will be saved directly to that file. (The pipeline usually contains many result images, it is not recommended to specify a specific file path directly, otherwise multiple images will be overwritten, leaving only the last image)
- Calling the `save_to_html()` method will save the above content to the specified `save_path`. If specified as a directory, the saved path will be `save_path/{your_img_basename}.html`; if specified as a file, it will be saved directly to that file. In the general table recognition pipeline v2, the HTML form of the table in the image will be written to the specified HTML file.
- Calling the `save_to_xlsx()` method will save the above content to the specified `save_path`. If specified as a directory, the saved path will be `save_path/{your_img_basename}.xlsx`; if specified as a file, it will be saved directly to that file. In the general table recognition pipeline v2, the Excel form of the table in the image will be written to the specified XLSX file.
* Additionally, it also supports obtaining visualized images and prediction results through attributes, as follows:
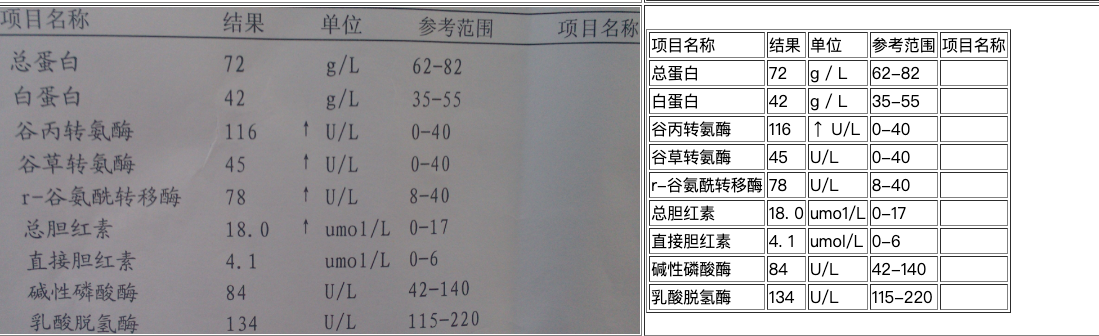 The General Table Recognition Pipeline v2 includes mandatory modules such as table structure recognition, table classification, table cell localization, text detection, and text recognition, as well as optional modules like layout area detection, document image orientation classification, and text image correction.
If you prioritize model accuracy, choose a model with higher accuracy; if you care more about inference speed, choose a model with faster inference speed; if you are concerned about model storage size, choose a model with a smaller storage size.
The General Table Recognition Pipeline v2 includes mandatory modules such as table structure recognition, table classification, table cell localization, text detection, and text recognition, as well as optional modules like layout area detection, document image orientation classification, and text image correction.
If you prioritize model accuracy, choose a model with higher accuracy; if you care more about inference speed, choose a model with faster inference speed; if you are concerned about model storage size, choose a model with a smaller storage size.

{kind=link}