👉 校验结果详情(点击展开)
校验结果文件具体内容为:
{
"done_flag": true,
"check_pass": true,
"attributes": {
"num_classes": 2,
"train_samples": 79,
"train_sample_paths": [
"check_dataset/demo_img/pexels-photo-634007.jpeg",
"check_dataset/demo_img/pexels-photo-59576.png"
],
"val_samples": 19,
"val_sample_paths": [
"check_dataset/demo_img/peasant-farmer-farmer-romania-botiza-47862.jpeg",
"check_dataset/demo_img/pexels-photo-715546.png"
]
},
"analysis": {
"histogram": "check_dataset/histogram.png"
},
"dataset_path": "./dataset/instance_seg_coco_examples",
"show_type": "image",
"dataset_type": "COCOInstSegDataset"
}
上述校验结果中,check_pass 为 True 表示数据集格式符合要求,其他部分指标的说明如下:
attributes.num_classes:该数据集类别数为 2;attributes.train_samples:该数据集训练集样本数量为 79;attributes.val_samples:该数据集验证集样本数量为 19;attributes.train_sample_paths:该数据集训练集样本可视化图片相对路径列表;attributes.val_sample_paths:该数据集验证集样本可视化图片相对路径列表;
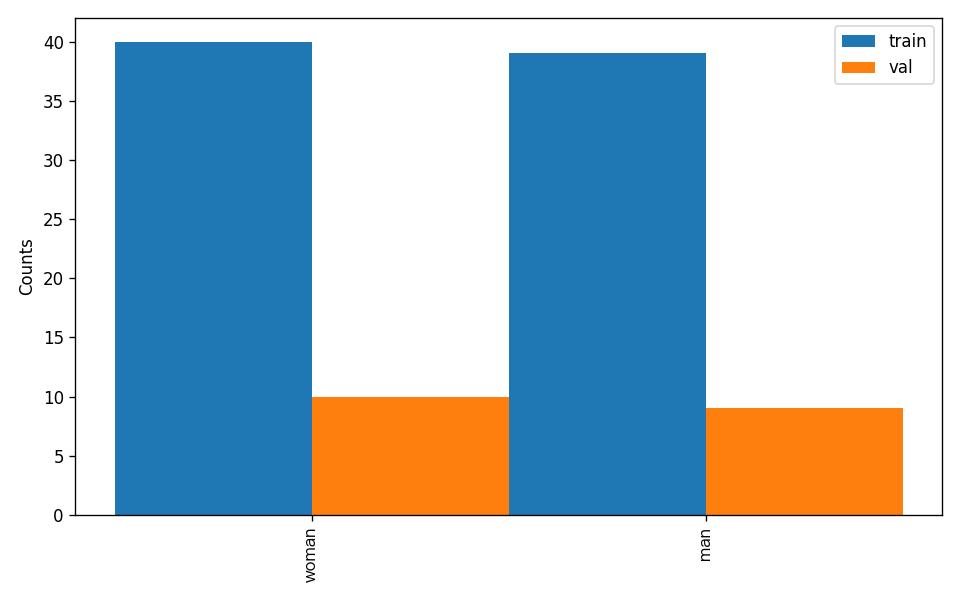
另外,数据集校验还对数据集中所有类别的样本数量分布情况进行了分析,并绘制了分布直方图(histogram.png):
👉 格式转换/数据集划分详情(点击展开)
(1)数据集格式转换
实例分割任务支持LabelMe格式转换为COCO格式,数据集格式转换的参数可以通过修改配置文件中 CheckDataset 下的字段进行设置,配置文件中部分参数的示例说明如下:
CheckDataset:convert:enable: 是否进行数据集格式转换,为True时进行数据集格式转换,默认为False;src_dataset_type: 如果进行数据集格式转换,则需设置源数据集格式,数据可选源格式为LabelMe;
例如,您想将LabelMe的数据集转换为 COCO格式,则需将配置文件修改为:
cd /path/to/paddlex
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/instance_seg_labelme_examples.tar -P ./dataset
tar -xf ./dataset/instance_seg_labelme_examples.tar -C ./dataset/
......
CheckDataset:
......
convert:
enable: True
src_dataset_type: LabelMe
......
随后执行命令:
python main.py -c paddlex/configs/instance_segmentation/Mask-RT-DETR-L.yaml\
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/instance_seg_labelme_examples
数据转换执行之后,原有标注文件会被在原路径下重命名为 xxx.bak。
以上参数同样支持通过追加命令行参数的方式进行设置:
python main.py -c paddlex/configs/instance_segmentation/Mask-RT-DETR-L.yaml\
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/instance_seg_labelme_examples \
-o CheckDataset.convert.enable=True \
-o CheckDataset.convert.src_dataset_type=LabelMe
(2)数据集划分
数据集划分的参数可以通过修改配置文件中 CheckDataset 下的字段进行设置,配置文件中部分参数的示例说明如下:
CheckDataset:split:enable: 是否进行重新划分数据集,为 True 时进行数据集格式转换,默认为 False;train_percent: 如果重新划分数据集,则需要设置训练集的百分比,类型为0-100之间的任意整数,需要保证和 val_percent 值加和为100;
例如,您想重新划分数据集为 训练集占比90%、验证集占比10%,则需将配置文件修改为:
......
CheckDataset:
......
split:
enable: True
train_percent: 90
val_percent: 10
......
随后执行命令:
python main.py -c paddlex/configs/instance_segmentation/Mask-RT-DETR-L.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/instance_seg_labelme_examples
数据划分执行之后,原有标注文件会被在原路径下重命名为 xxx.bak。
以上参数同样支持通过追加命令行参数的方式进行设置:
python main.py -c paddlex/configs/instance_segmentation/Mask-RT-DETR-L.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/instance_seg_labelme_examples \
-o CheckDataset.split.enable=True \
-o CheckDataset.split.train_percent=90 \
-o CheckDataset.split.val_percent=10