
| Model Name | Model Download Link | mIoU (%) | GPU Inference Time (ms) | CPU Inference Time (ms) | Model Size (M) |
|---|---|---|---|---|---|
| OCRNet_HRNet-W48 | Inference Model/Trained Model | 82.15 | 78.9976 | 2226.95 | 249.8 M |
| PP-LiteSeg-T | Inference Model/Trained Model | 73.10 | 7.6827 | 138.683 | 28.5 M |
| Model Name | Model Download Link | mIoU (%) | GPU Inference Time (ms) | CPU Inference Time (ms) | Model Size (M) |
|---|---|---|---|---|---|
| Deeplabv3_Plus-R50 | Inference Model/Trained Model | 80.36 | 61.0531 | 1513.58 | 94.9 M |
| Deeplabv3_Plus-R101 | Inference Model/Trained Model | 81.10 | 100.026 | 2460.71 | 162.5 M |
| Deeplabv3-R50 | Inference Model/Trained Model | 79.90 | 82.2631 | 1735.83 | 138.3 M |
| Deeplabv3-R101 | Inference Model/Trained Model | 80.85 | 121.492 | 2685.51 | 205.9 M |
| OCRNet_HRNet-W18 | Inference Model/Trained Model | 80.67 | 48.2335 | 906.385 | 43.1 M |
| OCRNet_HRNet-W48 | Inference Model/Trained Model | 82.15 | 78.9976 | 2226.95 | 249.8 M |
| PP-LiteSeg-T | Inference Model/Trained Model | 73.10 | 7.6827 | 138.683 | 28.5 M |
| PP-LiteSeg-B | Inference Model/Trained Model | 75.25 | 10.9935 | 194.727 | 47.0 M |
| SegFormer-B0 (slice) | Inference Model/Trained Model | 76.73 | 11.1946 | 268.929 | 13.2 M |
| SegFormer-B1 (slice) | Inference Model/Trained Model | 78.35 | 17.9998 | 403.393 | 48.5 M |
| SegFormer-B2 (slice) | Inference Model/Trained Model | 81.60 | 48.0371 | 1248.52 | 96.9 M |
| SegFormer-B3 (slice) | Inference Model/Trained Model | 82.47 | 64.341 | 1666.35 | 167.3 M |
| SegFormer-B4 (slice) | Inference Model/Trained Model | 82.38 | 82.4336 | 1995.42 | 226.7 M |
| SegFormer-B5 (slice) | Inference Model/Trained Model | 82.58 | 97.3717 | 2420.19 | 229.7 M |
The accuracy metrics of the above models are measured on the Cityscapes dataset. GPU inference time is based on an NVIDIA Tesla T4 machine with FP32 precision. CPU inference speed is based on an Intel(R) Xeon(R) Gold 5117 CPU @ 2.00GHz with 8 threads and FP32 precision.
| Model Name | Model Download Link | mIoU (%) | GPU Inference Time (ms) | CPU Inference Time | Model Size (M) |
|---|---|---|---|---|---|
| SeaFormer_base(slice) | Inference Model/Trained Model | 40.92 | 24.4073 | 397.574 | 30.8 M |
| SeaFormer_large (slice) | Inference Model/Trained Model | 43.66 | 27.8123 | 550.464 | 49.8 M |
| SeaFormer_small (slice) | Inference Model/Trained Model | 38.73 | 19.2295 | 358.343 | 14.3 M |
| SeaFormer_tiny (slice) | Inference Model/Trained Model | 34.58 | 13.9496 | 330.132 | 6.1M |
The accuracy metrics of the SeaFormer series models are measured on the ADE20k dataset. GPU inference time is based on an NVIDIA Tesla T4 machine with FP32 precision. CPU inference speed is based on an Intel(R) Xeon(R) Gold 5117 CPU @ 2.00GHz with 8 threads and FP32 precision.
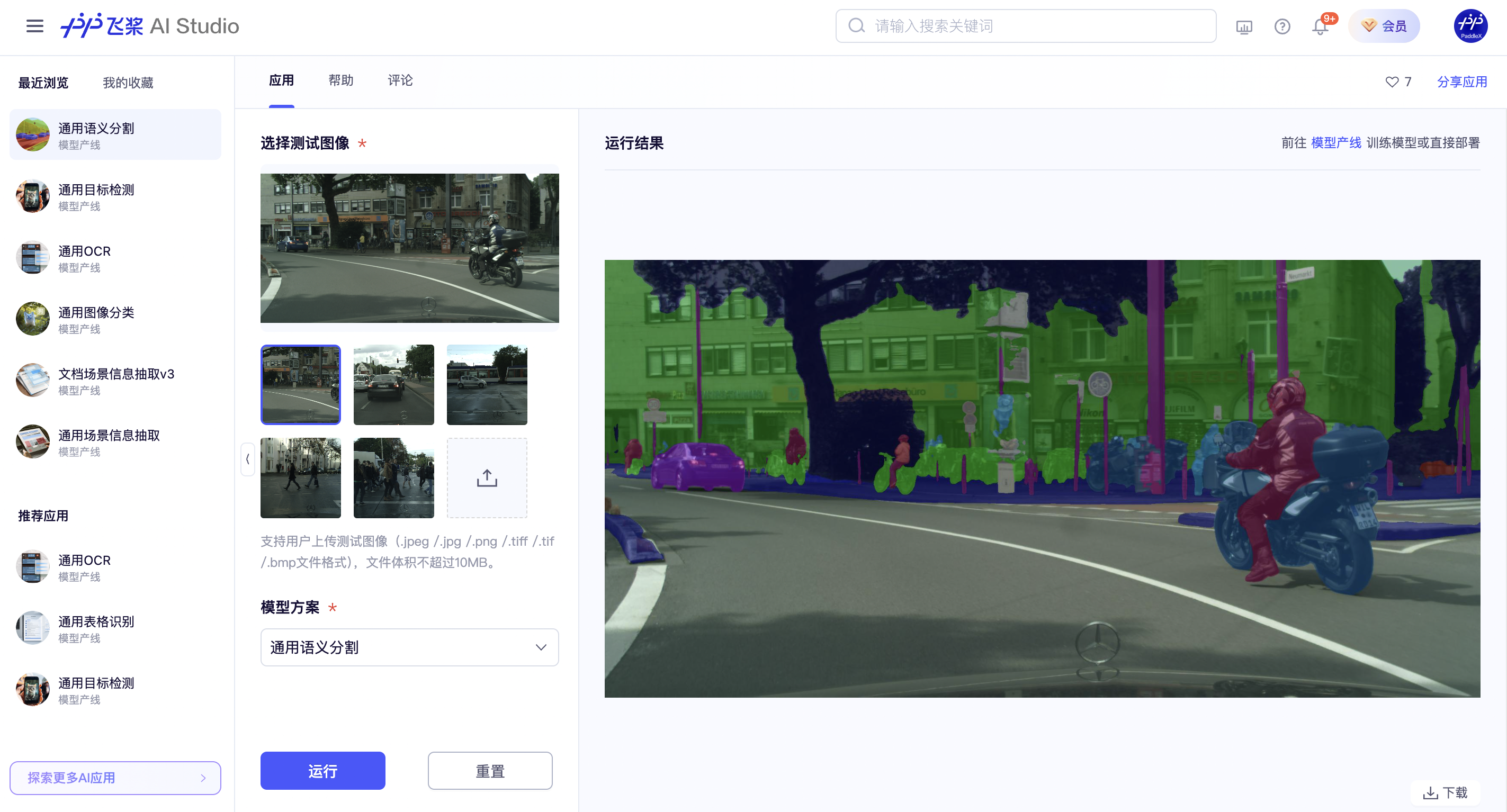 If you are satisfied with the pipeline's performance, you can directly integrate and deploy it. If not, you can also use your private data to fine-tune the model in the pipeline online.
### 2.2 Local Experience
Before using the General Semantic Segmentation Pipeline locally, ensure you have installed the PaddleX wheel package following the [PaddleX Local Installation Tutorial](../../../installation/installation.en.md).
#### 2.2.1 Command Line Experience
Experience the semantic segmentation pipeline with a single command, Use the [test file](https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/application/semantic_segmentation/makassaridn-road_demo.png), and replace `--input` with the local path to perform prediction.
```bash
paddlex --pipeline semantic_segmentation --input makassaridn-road_demo.png --device gpu:0
```
Parameter Explanation:
```
--pipeline: The name of the pipeline, here it is the semantic segmentation pipeline
--input: The local path or URL of the input image to be processed
--device: The GPU index to use (e.g., gpu:0 for the first GPU, gpu:1,2 for the second and third GPUs), or choose to use CPU (--device cpu)
```
When executing the above command, the default semantic segmentation pipeline configuration file is loaded. If you need to customize the configuration file, you can execute the following command to obtain it:
If you are satisfied with the pipeline's performance, you can directly integrate and deploy it. If not, you can also use your private data to fine-tune the model in the pipeline online.
### 2.2 Local Experience
Before using the General Semantic Segmentation Pipeline locally, ensure you have installed the PaddleX wheel package following the [PaddleX Local Installation Tutorial](../../../installation/installation.en.md).
#### 2.2.1 Command Line Experience
Experience the semantic segmentation pipeline with a single command, Use the [test file](https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/application/semantic_segmentation/makassaridn-road_demo.png), and replace `--input` with the local path to perform prediction.
```bash
paddlex --pipeline semantic_segmentation --input makassaridn-road_demo.png --device gpu:0
```
Parameter Explanation:
```
--pipeline: The name of the pipeline, here it is the semantic segmentation pipeline
--input: The local path or URL of the input image to be processed
--device: The GPU index to use (e.g., gpu:0 for the first GPU, gpu:1,2 for the second and third GPUs), or choose to use CPU (--device cpu)
```
When executing the above command, the default semantic segmentation pipeline configuration file is loaded. If you need to customize the configuration file, you can execute the following command to obtain it:
paddlex --get_pipeline_config semantic_segmentation
After execution, the semantic segmentation pipeline configuration file will be saved in the current path. If you wish to customize the save location, execute the following command (assuming the custom save location is ./my_path):
paddlex --get_pipeline_config semantic_segmentation --save_path ./my_path
After obtaining the pipeline configuration file, replace --pipeline with the configuration file save path to make the configuration file take effect. For example, if the configuration file save path is ./semantic_segmentation.yaml, simply execute:
paddlex --pipeline ./semantic_segmentation.yaml --input makassaridn-road_demo.png --device gpu:0
Here, parameters such as --model and --device do not need to be specified, and the parameters in the configuration file will be used. If parameters are still specified, the specified parameters will take precedence.
 The visualized image not saved by default. You can customize the save path through `--save_path`, and then all results will be saved in the specified path.
#### 2.2.2 Python Script Integration
A few lines of code can complete the quick inference of the pipeline. Taking the general semantic segmentation pipeline as an example:
```python
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="semantic_segmentation")
output = pipeline.predict("makassaridn-road_demo.png")
for res in output:
res.print() # Print the structured output of the prediction
res.save_to_img("./output/") # Save the visualization image of the result
res.save_to_json("./output/") # Save the structured output of the prediction
```
The results obtained are the same as those from the command line method.
In the above Python script, the following steps are executed:
(1) Instantiate the `create_pipeline` to create a pipeline object: The specific parameter descriptions are as follows:
The visualized image not saved by default. You can customize the save path through `--save_path`, and then all results will be saved in the specified path.
#### 2.2.2 Python Script Integration
A few lines of code can complete the quick inference of the pipeline. Taking the general semantic segmentation pipeline as an example:
```python
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="semantic_segmentation")
output = pipeline.predict("makassaridn-road_demo.png")
for res in output:
res.print() # Print the structured output of the prediction
res.save_to_img("./output/") # Save the visualization image of the result
res.save_to_json("./output/") # Save the structured output of the prediction
```
The results obtained are the same as those from the command line method.
In the above Python script, the following steps are executed:
(1) Instantiate the `create_pipeline` to create a pipeline object: The specific parameter descriptions are as follows:
| Parameter | Description | Type | Default Value |
|---|---|---|---|
pipeline |
The name of the pipeline or the path to the pipeline configuration file. If it is the name of the pipeline, it must be a pipeline supported by PaddleX. | str |
None |
device |
The device for pipeline model inference. Supports: "gpu", "cpu". | str |
"gpu" |
enable_hpi |
Whether to enable high-performance inference, which is only available when the pipeline supports it. | bool |
False |
| Parameter Type | Description |
|---|---|
| Python Var | Supports directly passing Python variables, such as numpy.ndarray representing image data. |
str |
Supports passing the path of the file to be predicted, such as the local path of an image file: /root/data/img.jpg. |
str |
Supports passing the URL of the file to be predicted, such as the network URL of an image file: Example. |
str |
Supports passing a local directory, which should contain files to be predicted, such as the local path: /root/data/. |
dict |
Supports passing a dictionary type, where the key needs to correspond to a specific task, such as "img" for image classification tasks, and the value of the dictionary supports the above data types, e.g., {"img": "/root/data1"}. |
list |
Supports passing a list, where the list elements need to be the above data types, such as [numpy.ndarray, numpy.ndarray], ["/root/data/img1.jpg", "/root/data/img2.jpg"], ["/root/data1", "/root/data2"], [{"img": "/root/data1"}, {"img": "/root/data2/img.jpg"}]. |
| Method | Description | Method Parameters |
|---|---|---|
| Prints results to the terminal | - format_json: bool, whether to format the output content with json indentation, default is True;- indent: int, json formatting setting, only valid when format_json is True, default is 4;- ensure_ascii: bool, json formatting setting, only valid when format_json is True, default is False; |
|
| save_to_json | Saves results as a json file | - save_path: str, the path to save the file, when it's a directory, the saved file name is consistent with the input file type;- indent: int, json formatting setting, default is 4;- ensure_ascii: bool, json formatting setting, default is False; |
| save_to_img | Saves results as an image file | - save_path: str, the path to save the file, when it's a directory, the saved file name is consistent with the input file type; |
For main operations provided by the service:
200, and the response body properties are as follows:| Name | Type | Description |
|---|---|---|
logId |
string |
UUID for the request. |
errorCode |
integer |
Error code. Fixed as 0. |
errorMsg |
string |
Error description. Fixed as "Success". |
result |
object |
Operation result. |
| Name | Type | Description |
|---|---|---|
logId |
string |
UUID for the request. |
errorCode |
integer |
Error code. Same as the response status code. |
errorMsg |
string |
Error description. |
Main operations provided by the service are as follows:
inferPerforms semantic segmentation on an image.
POST /semantic-segmentation
| Name | Type | Description | Required |
|---|---|---|---|
image |
string |
The URL of an image file accessible by the service or the Base64 encoded result of the image file content. | Yes |
result of the response body has the following properties:| Name | Type | Description |
|---|---|---|
labelMap |
array |
Records the class label of each pixel in the image (arranged in row-major order). |
size |
array |
Image shape. The elements in the array are the height and width of the image, respectively. |
image |
string |
The semantic segmentation result image. The image is in JPEG format and encoded using Base64. |
An example of result is as follows:
{
"labelMap": [
0,
0,
1,
2
],
"size": [
2,
2
],
"image": "xxxxxx"
}
import base64
import requests
API_URL = "http://localhost:8080/semantic-segmentation"
image_path = "./demo.jpg"
output_image_path = "./out.jpg"
with open(image_path, "rb") as file:
image_bytes = file.read()
image_data = base64.b64encode(image_bytes).decode("ascii")
payload = {"image": image_data}
response = requests.post(API_URL, json=payload)
assert response.status_code == 200
result = response.json()["result"]
with open(output_image_path, "wb") as file:
file.write(base64.b64decode(result["image"]))
print(f"Output image saved at {output_image_path}")
#include <iostream>
#include "cpp-httplib/httplib.h" // https://github.com/Huiyicc/cpp-httplib
#include "nlohmann/json.hpp" // https://github.com/nlohmann/json
#include "base64.hpp" // https://github.com/tobiaslocker/base64
int main() {
httplib::Client client("localhost:8080");
const std::string imagePath = "./demo.jpg";
const std::string outputImagePath = "./out.jpg";
httplib::Headers headers = {
{"Content-Type", "application/json"}
};
std::ifstream file(imagePath, std::ios::binary | std::ios::ate);
std::streamsize size = file.tellg();
file.seekg(0, std::ios::beg);
std::vector<char> buffer(size);
if (!file.read(buffer.data(), size)) {
std::cerr << "Error reading file." << std::endl;
return 1;
}
std::string bufferStr(reinterpret_cast<const char*>(buffer.data()), buffer.size());
std::string encodedImage = base64::to_base64(bufferStr);
nlohmann::json jsonObj;
jsonObj["image"] = encodedImage;
std::string body = jsonObj.dump();
auto response = client.Post("/semantic-segmentation", headers, body, "application/json");
if (response && response->status == 200) {
nlohmann::json jsonResponse = nlohmann::json::parse(response->body);
auto result = jsonResponse["result"];
encodedImage = result["image"];
std::string decodedString = base64::from_base64(encodedImage);
std::vector<unsigned char> decodedImage(decodedString.begin(), decodedString.end());
std::ofstream outputImage(outPutImagePath, std::ios::binary | std::ios::out);
if (outputImage.is_open()) {
outputImage.write(reinterpret_cast<char*>(decodedImage.data()), decodedImage.size());
outputImage.close();
std::cout << "Output image saved at " << outPutImagePath << std::endl;
} else {
std::cerr << "Unable to open file for writing: " << outPutImagePath << std::endl;
}
} else {
std::cout << "Failed to send HTTP request." << std::endl;
return 1;
}
return 0;
}
import okhttp3.*;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.node.ObjectNode;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Base64;
public class Main {
public static void main(String[] args) throws IOException {
String API_URL = "http://localhost:8080/semantic-segmentation";
String imagePath = "./demo.jpg";
String outputImagePath = "./out.jpg";
File file = new File(imagePath);
byte[] fileContent = java.nio.file.Files.readAllBytes(file.toPath());
String imageData = Base64.getEncoder().encodeToString(fileContent);
ObjectMapper objectMapper = new ObjectMapper();
ObjectNode params = objectMapper.createObjectNode();
params.put("image", imageData);
OkHttpClient client = new OkHttpClient();
MediaType JSON = MediaType.Companion.get("application/json; charset=utf-8");
RequestBody body = RequestBody.Companion.create(params.toString(), JSON);
Request request = new Request.Builder()
.url(API_URL)
.post(body)
.build();
try (Response response = client.newCall(request).execute()) {
if (response.isSuccessful()) {
String responseBody = response.body().string();
JsonNode resultNode = objectMapper.readTree(responseBody);
JsonNode result = resultNode.get("result");
String base64Image = result.get("image").asText();
JsonNode labelMap = result.get("labelMap");
byte[] imageBytes = Base64.getDecoder().decode(base64Image);
try (FileOutputStream fos = new FileOutputStream(outputImagePath)) {
fos.write(imageBytes);
}
System.out.println("Output image saved at " + outputImagePath);
} else {
System.err.println("Request failed with code: " + response.code());
}
}
}
}
package main
import (
"bytes"
"encoding/base64"
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
)
func main() {
API_URL := "http://localhost:8080/semantic-segmentation"
imagePath := "./demo.jpg"
outputImagePath := "./out.jpg"
imageBytes, err := ioutil.ReadFile(imagePath)
if err != nil {
fmt.Println("Error reading image file:", err)
return
}
imageData := base64.StdEncoding.EncodeToString(imageBytes)
payload := map[string]string{"image": imageData}
payloadBytes, err := json.Marshal(payload)
if err != nil {
fmt.Println("Error marshaling payload:", err)
return
}
client := &http.Client{}
req, err := http.NewRequest("POST", API_URL, bytes.NewBuffer(payloadBytes))
if err != nil {
fmt.Println("Error creating request:", err)
return
}
res, err := client.Do(req)
if err != nil {
fmt.Println("Error sending request:", err)
return
}
defer res.Body.Close()
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println("Error reading response body:", err)
return
}
type Response struct {
Result struct {
Image string `json:"image"`
Labelmap []map[string]interface{} `json:"labelMap"`
} `json:"result"`
}
var respData Response
err = json.Unmarshal([]byte(string(body)), &respData)
if err != nil {
fmt.Println("Error unmarshaling response body:", err)
return
}
outputImageData, err := base64.StdEncoding.DecodeString(respData.Result.Image)
if err != nil {
fmt.Println("Error decoding base64 image data:", err)
return
}
err = ioutil.WriteFile(outputImagePath, outputImageData, 0644)
if err != nil {
fmt.Println("Error writing image to file:", err)
return
}
fmt.Printf("Image saved at %s.jpg\n", outputImagePath)
}
using System;
using System.IO;
using System.Net.Http;
using System.Net.Http.Headers;
using System.Text;
using System.Threading.Tasks;
using Newtonsoft.Json.Linq;
class Program
{
static readonly string API_URL = "http://localhost:8080/semantic-segmentation";
static readonly string imagePath = "./demo.jpg";
static readonly string outputImagePath = "./out.jpg";
static async Task Main(string[] args)
{
var httpClient = new HttpClient();
byte[] imageBytes = File.ReadAllBytes(imagePath);
string image_data = Convert.ToBase64String(imageBytes);
var payload = new JObject{ { "image", image_data } };
var content = new StringContent(payload.ToString(), Encoding.UTF8, "application/json");
HttpResponseMessage response = await httpClient.PostAsync(API_URL, content);
response.EnsureSuccessStatusCode();
string responseBody = await response.Content.ReadAsStringAsync();
JObject jsonResponse = JObject.Parse(responseBody);
string base64Image = jsonResponse["result"]["image"].ToString();
byte[] outputImageBytes = Convert.FromBase64String(base64Image);
File.WriteAllBytes(outputImagePath, outputImageBytes);
Console.WriteLine($"Output image saved at {outputImagePath}");
}
}
const axios = require('axios');
const fs = require('fs');
const API_URL = 'http://localhost:8080/semantic-segmentation'
const imagePath = './demo.jpg'
const outputImagePath = "./out.jpg";
let config = {
method: 'POST',
maxBodyLength: Infinity,
url: API_URL,
data: JSON.stringify({
'image': encodeImageToBase64(imagePath)
})
};
function encodeImageToBase64(filePath) {
const bitmap = fs.readFileSync(filePath);
return Buffer.from(bitmap).toString('base64');
}
axios.request(config)
.then((response) => {
const result = response.data["result"];
const imageBuffer = Buffer.from(result["image"], 'base64');
fs.writeFile(outputImagePath, imageBuffer, (err) => {
if (err) throw err;
console.log(`Output image saved at ${outputImagePath}`);
});
})
.catch((error) => {
console.log(error);
});
<?php
$API_URL = "http://localhost:8080/semantic-segmentation";
$image_path = "./demo.jpg";
$output_image_path = "./out.jpg";
$image_data = base64_encode(file_get_contents($image_path));
$payload = array("image" => $image_data);
$ch = curl_init($API_URL);
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, json_encode($payload));
curl_setopt($ch, CURLOPT_HTTPHEADER, array('Content-Type: application/json'));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$response = curl_exec($ch);
curl_close($ch);
$result = json_decode($response, true)["result"];
file_put_contents($output_image_path, base64_decode($result["image"]));
echo "Output image saved at " . $output_image_path . "\n";
?>
{kind=link}