---
comments: true
---
# PaddleX语义分割任务模块数据标注教程
本文档将介绍如何使用 [Labelme](https://github.com/wkentaro/labelme) 标注工具完成语义分割相关单模型的数据标注。点击上述链接,参考⾸⻚⽂档即可安装数据标注⼯具并查看详细使⽤流程。
## 1. 标注数据示例
该数据集是人工采集的街景数据集,数据种类涵盖了车辆和道路两种类别,包含目标不同角度的拍摄照片。图片示例:
## 2. Labelme标注
### 2.1 Labelme标注工具介绍
`Labelme` 是一个 `python` 语言编写,带有图形界面的图像标注软件。可用于图像分类,目标检测,语义分割等任务,在语义分割的标注任务中,标签存储为 `JSON` 文件。
### 2.2 Labelme安装
为避免环境冲突,建议在 `conda` 环境下安装。
```bash
conda create -n labelme python=3.10
conda activate labelme
pip install pyqt5
pip install labelme
```
### 2.3 Labelme标注过程
#### 2.3.1 准备待标注数据
* 创建数据集根目录,如 `seg_dataset`
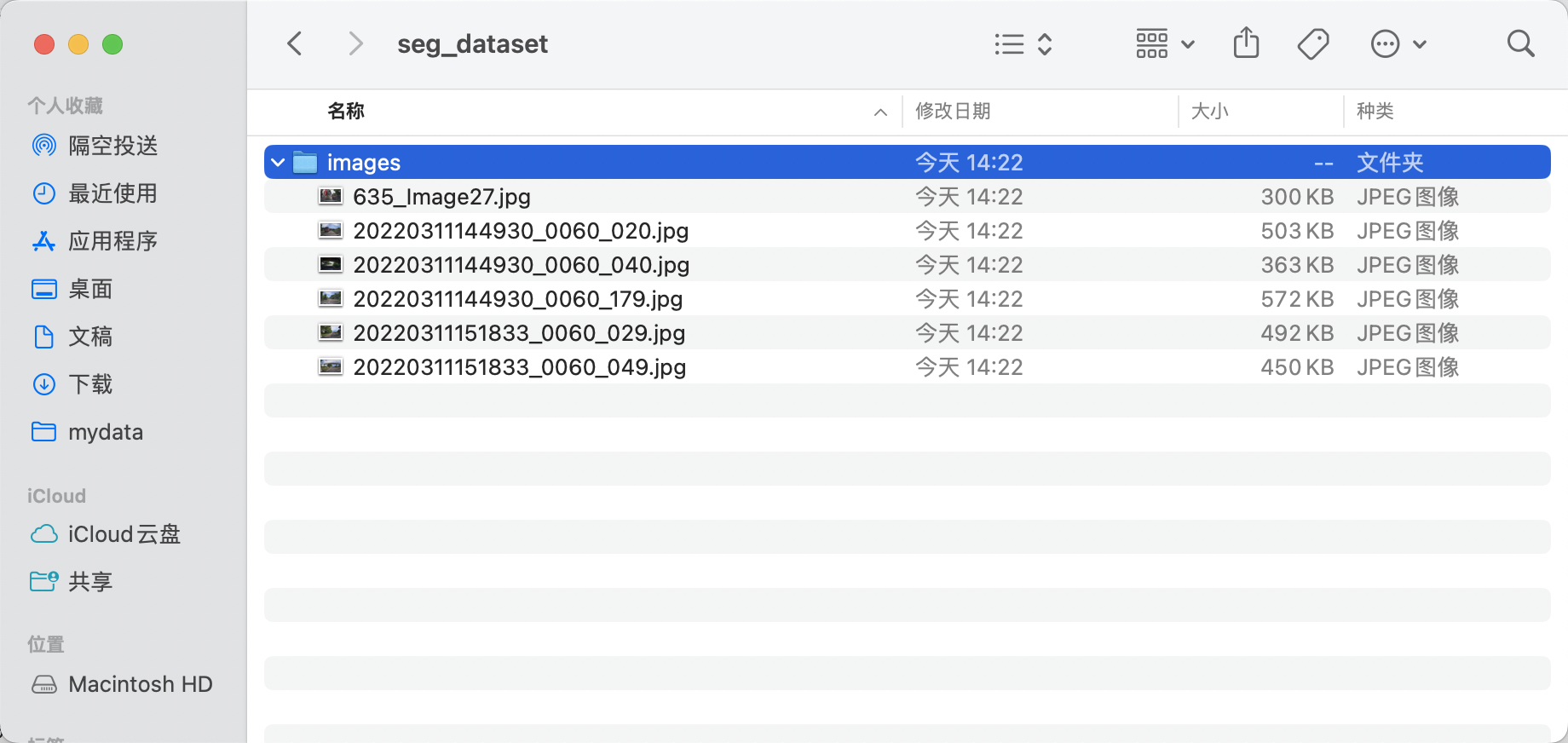
* 在 `seg_dataset` 中创建 `images` 目录(目录名称可修改,但要保持后续命令的图片目录名称正确),并将待标注图片存储在 `images` 目录下,如下图所示:
 #### 2.3.2 启动Labelme
终端进入到待标注数据集根目录,并启动 `labelme` 标注工具。
```bash
# Windows
cd C:\path\to\seg_dataset
# Mac/Linux
cd path/to/seg_dataset
```
```bash
labelme images --nodata --autosave --output annotations
```
* `nodata` 停止将图像数据存储到JSON文件
* `autosave` 自动存储
* `output` 标签文件存储路径
#### 2.3.3 开始图片标注
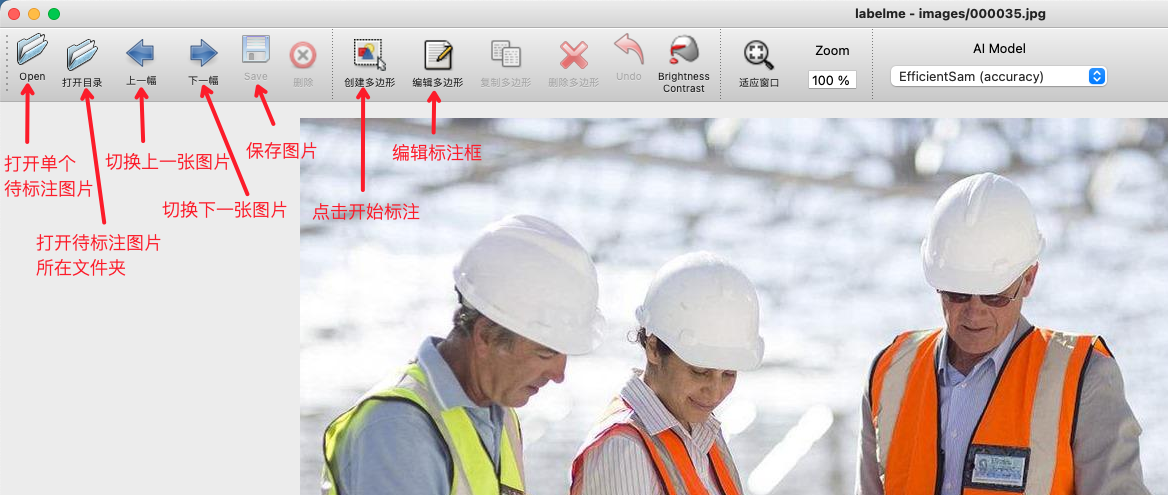
* 启动 `labelme` 后如图所示:
#### 2.3.2 启动Labelme
终端进入到待标注数据集根目录,并启动 `labelme` 标注工具。
```bash
# Windows
cd C:\path\to\seg_dataset
# Mac/Linux
cd path/to/seg_dataset
```
```bash
labelme images --nodata --autosave --output annotations
```
* `nodata` 停止将图像数据存储到JSON文件
* `autosave` 自动存储
* `output` 标签文件存储路径
#### 2.3.3 开始图片标注
* 启动 `labelme` 后如图所示:
 * 点击"编辑"选择标注类型
* 点击"编辑"选择标注类型
 * 选择创建多边形
* 选择创建多边形
 * 在图片上绘制目标轮廓
* 在图片上绘制目标轮廓
 * 出现如下左图所示轮廓线闭合时,弹出类别选择框,可输入或选择目标类别
* 出现如下左图所示轮廓线闭合时,弹出类别选择框,可输入或选择目标类别
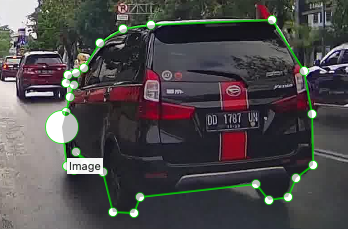
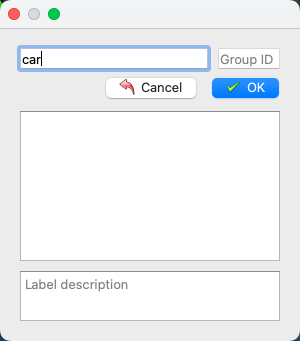 通常情况下,只需要标注前景目标并设置标注类别即可,其他像素默认作为背景。如需要手动标注背景区域,类别必须设置为 _background_,否则格式转换数据集会出现错误。
对于图片中的噪声部分或不参与模型训练的部分,可以使用 __ignore__ 类,模型训练时会自动跳过对应部分。
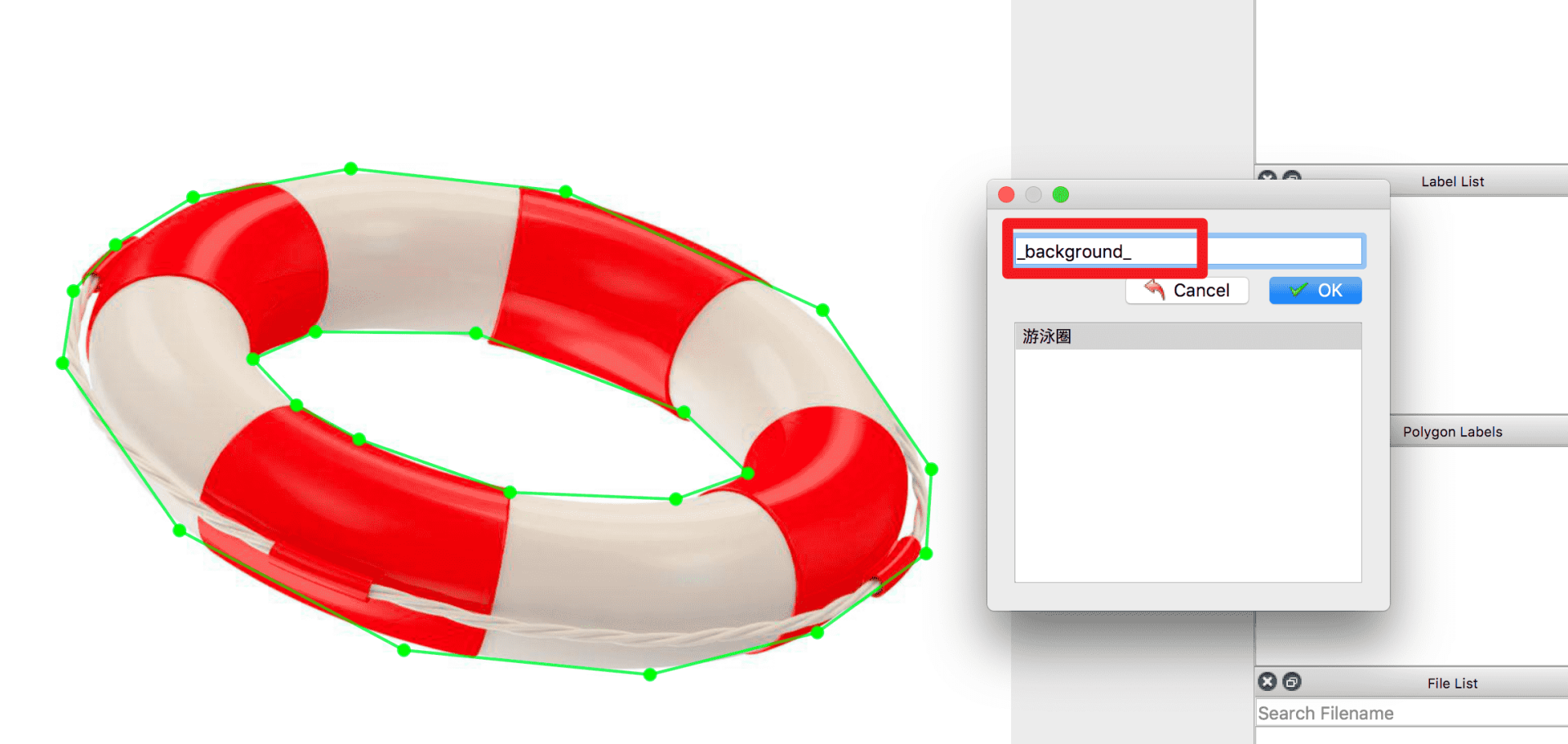
针对带有空洞的目标,在标注完目标外轮廓后,再沿空洞边缘画多边形,并将空洞指定为特定类别,如果空洞是背景则指定为 _background_,示例如下:
通常情况下,只需要标注前景目标并设置标注类别即可,其他像素默认作为背景。如需要手动标注背景区域,类别必须设置为 _background_,否则格式转换数据集会出现错误。
对于图片中的噪声部分或不参与模型训练的部分,可以使用 __ignore__ 类,模型训练时会自动跳过对应部分。
针对带有空洞的目标,在标注完目标外轮廓后,再沿空洞边缘画多边形,并将空洞指定为特定类别,如果空洞是背景则指定为 _background_,示例如下:
 * 标注好后点击存储。(若在启动 `labelme` 时未指定`output` 字段,会在第一次存储时提示选择存储路径,若指定`autosave` 字段使用自动保存,则无需点击存储按钮)
* 标注好后点击存储。(若在启动 `labelme` 时未指定`output` 字段,会在第一次存储时提示选择存储路径,若指定`autosave` 字段使用自动保存,则无需点击存储按钮)
 * 然后点击 "Next Image" 进行下一张图片的标注
* 然后点击 "Next Image" 进行下一张图片的标注
 * 最终标注好的标签文件如图所示
* 最终标注好的标签文件如图所示
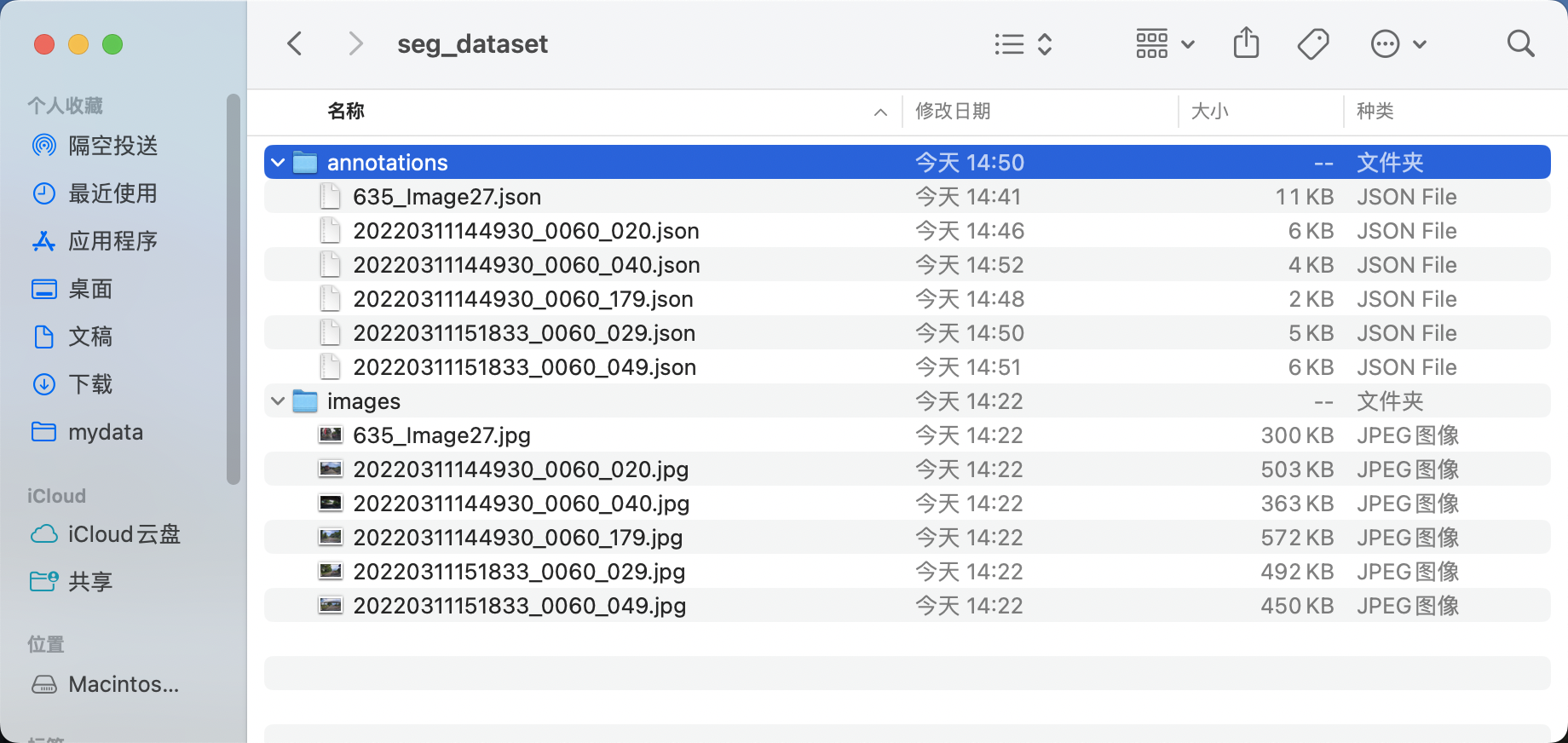 * 调整目录得到安全帽检测标准labelme格式数据集
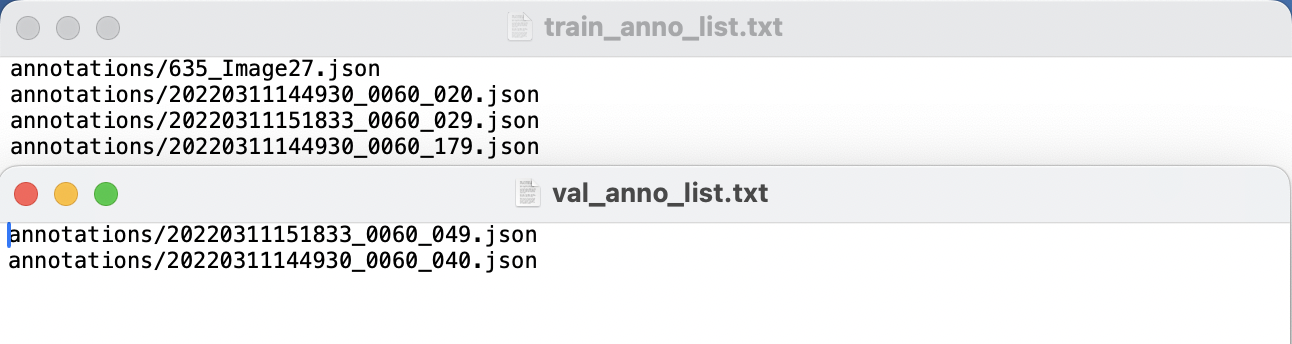
a. 在数据集根目录 seg_datset 下载并执行[目录整理脚本](https://paddle-model-ecology.bj.bcebos.com/paddlex/data/format_seg_labelme_dataset.py)。执行脚本后的 train_anno_list.txt 和 val_anno_list.txt 中具体内容如图所示:
```
python format_seg_labelme_dataset.py
```
* 调整目录得到安全帽检测标准labelme格式数据集
a. 在数据集根目录 seg_datset 下载并执行[目录整理脚本](https://paddle-model-ecology.bj.bcebos.com/paddlex/data/format_seg_labelme_dataset.py)。执行脚本后的 train_anno_list.txt 和 val_anno_list.txt 中具体内容如图所示:
```
python format_seg_labelme_dataset.py
```
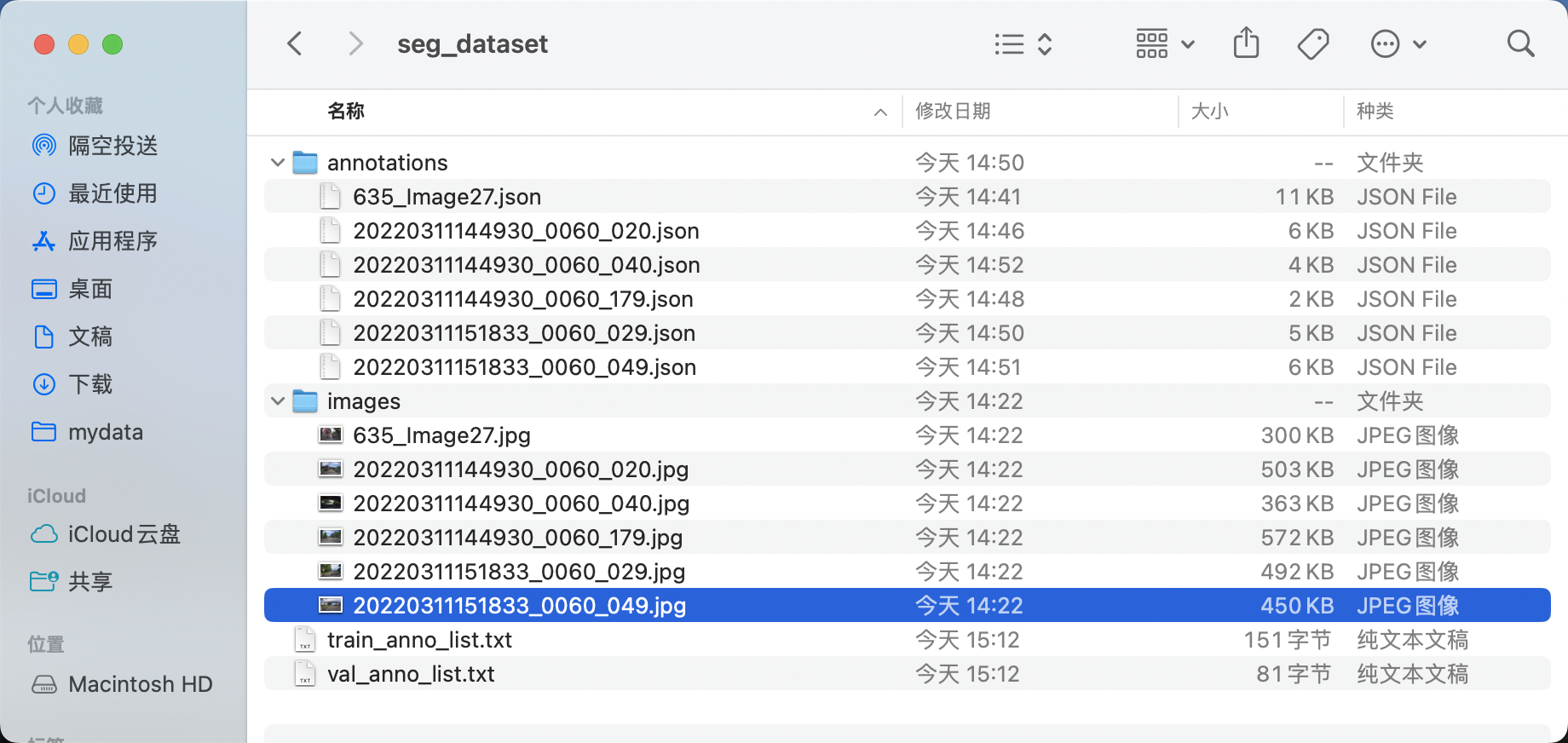
 b. 经过整理得到的最终目录结构如下:
b. 经过整理得到的最终目录结构如下:
 #### 2.3.4 格式转换
使用`LabelMe`标注完成后,需要将数据格式转换为`Seg` 数据格式。下面给出了按照上述教程使用`LableMe`标注完成的数据和进行数据格式转换的代码示例。
```bash
cd /path/to/paddlex
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/seg_dataset_to_convert.tar -P ./dataset
tar -xf ./dataset/seg_dataset_to_convert.tar -C ./dataset/
python main.py -c paddlex/configs/semantic_segmentation/PP-LiteSeg-T.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/seg_dataset_to_convert \
-o CheckDataset.convert.enable=True \
-o CheckDataset.convert.src_dataset_type=LabelMe
```
## 数据格式
PaddleX 针对图像分割任务定义的数据集,名称是SegDataset,组织结构和标注格式如下:
```bash
dataset_dir # 数据集根目录,目录名称可以改变
├── annotations # 存放标注图像的目录,目录名称可以改变,注意与标识文件的内容相对应
├── images # 存放原始图像的目录,目录名称可以改变,注意与标识文件的内容相对应
├── train.txt # 训练集标注文件,文件名称不可改变。每行是原始图像路径和标注图像路径,使用空格分隔,内容举例:images/P0005.jpg annotations/P0005.png
└── val.txt # 验证集标注文件,文件名称不可改变。每行是原始图像路径和标注图像路径,使用空格分隔,内容举例:images/N0139.jpg annotations/N0139.png
```
标注图像是单通道灰度图或者单通道伪彩色图,建议使用`PNG`格式保存。标注图像中每种像素值代表一个类别,类别必须从0开始依次递增,例如0、1、2、3表示4种类别。标注图像的像素存储是8bit,所以标注类别最多支持256类。
请大家参考上述规范准备数据,此外可以参考:[示例数据集](https://paddle-model-ecology.bj.bcebos.com/paddlex/data/seg_optic_examples.tar)
#### 2.3.4 格式转换
使用`LabelMe`标注完成后,需要将数据格式转换为`Seg` 数据格式。下面给出了按照上述教程使用`LableMe`标注完成的数据和进行数据格式转换的代码示例。
```bash
cd /path/to/paddlex
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/seg_dataset_to_convert.tar -P ./dataset
tar -xf ./dataset/seg_dataset_to_convert.tar -C ./dataset/
python main.py -c paddlex/configs/semantic_segmentation/PP-LiteSeg-T.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/seg_dataset_to_convert \
-o CheckDataset.convert.enable=True \
-o CheckDataset.convert.src_dataset_type=LabelMe
```
## 数据格式
PaddleX 针对图像分割任务定义的数据集,名称是SegDataset,组织结构和标注格式如下:
```bash
dataset_dir # 数据集根目录,目录名称可以改变
├── annotations # 存放标注图像的目录,目录名称可以改变,注意与标识文件的内容相对应
├── images # 存放原始图像的目录,目录名称可以改变,注意与标识文件的内容相对应
├── train.txt # 训练集标注文件,文件名称不可改变。每行是原始图像路径和标注图像路径,使用空格分隔,内容举例:images/P0005.jpg annotations/P0005.png
└── val.txt # 验证集标注文件,文件名称不可改变。每行是原始图像路径和标注图像路径,使用空格分隔,内容举例:images/N0139.jpg annotations/N0139.png
```
标注图像是单通道灰度图或者单通道伪彩色图,建议使用`PNG`格式保存。标注图像中每种像素值代表一个类别,类别必须从0开始依次递增,例如0、1、2、3表示4种类别。标注图像的像素存储是8bit,所以标注类别最多支持256类。
请大家参考上述规范准备数据,此外可以参考:[示例数据集](https://paddle-model-ecology.bj.bcebos.com/paddlex/data/seg_optic_examples.tar)





