简体中文 | [English](instance_segmentation_en.md)
# PaddleX实例分割任务模块数据标注教程
本文档将介绍如何使用 [Labelme](https://github.com/wkentaro/labelme) 标注工具完成实例分割相关单模型的数据标注。点击上述链接,参考⾸⻚⽂档即可安装数据标注⼯具并查看详细使⽤流程。
## 1. 标注数据示例
该数据集是水果实例分割数据集,涵盖五种不同的水果,包含目标不同角度的拍摄照片。图片示例:
## 2. Labelme标注
### 2.1 Labelme 标注工具介绍
`Labelme` 是一个 `python` 语言编写,带有图形界面的图像标注软件。可用于图像分类、目标检测、图像分割等任务,在实例分割的标注任务中,标签存储为 `JSON` 文件。
### 2.2 Labelme 安装
为避免环境冲突,建议在 `conda` 环境下安装。
```bash
conda create -n labelme python=3.10
conda activate labelme
pip install pyqt5
pip install labelme
```
### 2.3 Labelme 标注过程
#### 2.3.1 准备待标注数据
* 创建数据集根目录,如 `fruit`。
* 在 `fruit` 中创建 `images` 目录(必须为 `images` 目录),并将待标注图片存储在 `images` 目录下,如下图所示:
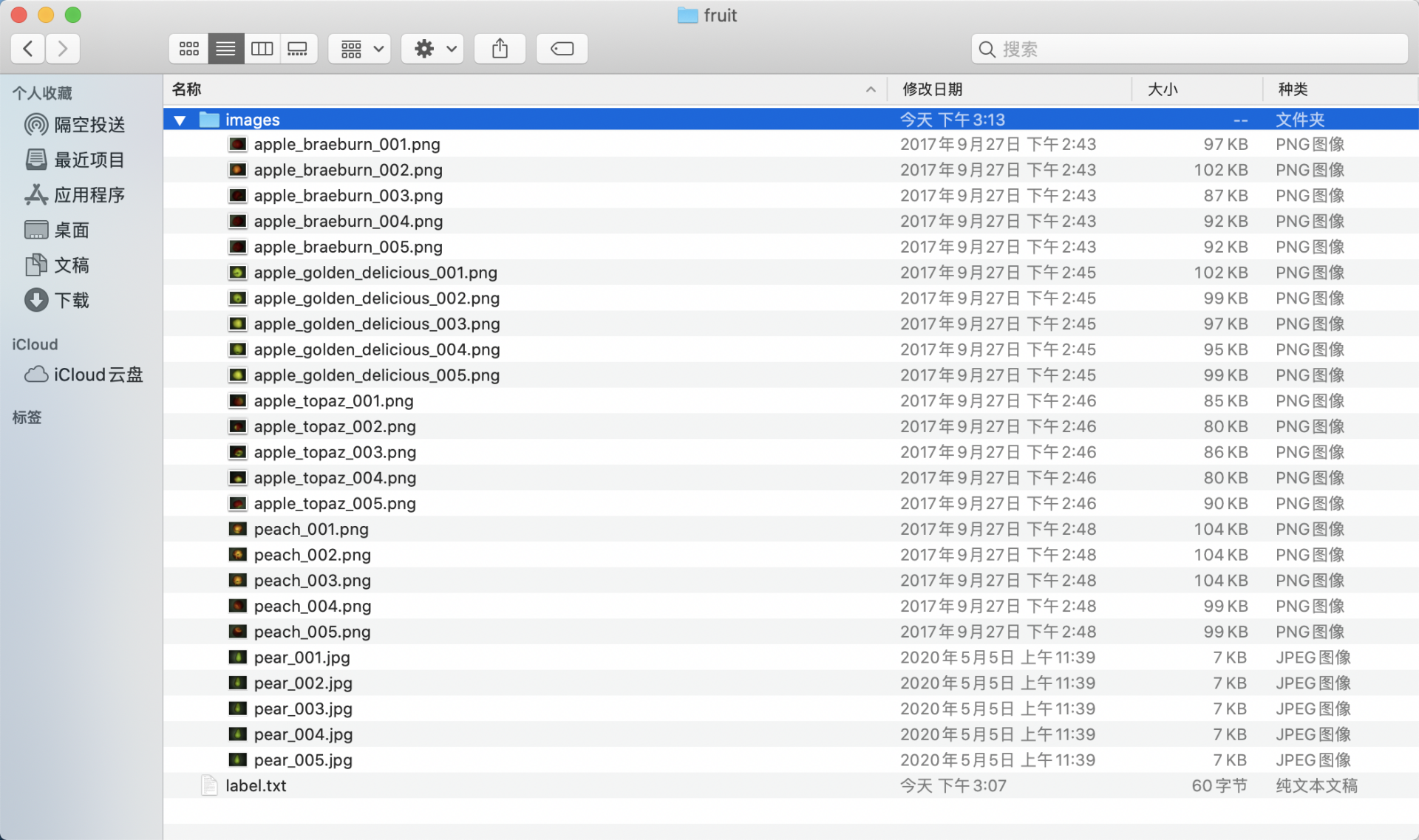
* 在 `fruit` 文件夹中创建待标注数据集的类别标签文件 `label.txt`,并在 `label.txt` 中按行写入待标注数据集的类别。以水果实例分割数据集的 `label.txt` 为例,如下图所示:

#### 2.3.2 启动 Labelme
终端进入到带标注数据集根目录,并启动 `labelme` 标注工具。
```bash
cd path/to/fruit
labelme images --labels label.txt --nodata --autosave --output annotations
```
* `labels` 类别标签路径。
* `nodata` 停止将图像数据存储到JSON文件。
* `autosave` 自动存储。
* `ouput` 标签文件存储路径。
#### 2.3.3 开始图片标注
* 启动 `labelme` 后如图所示:
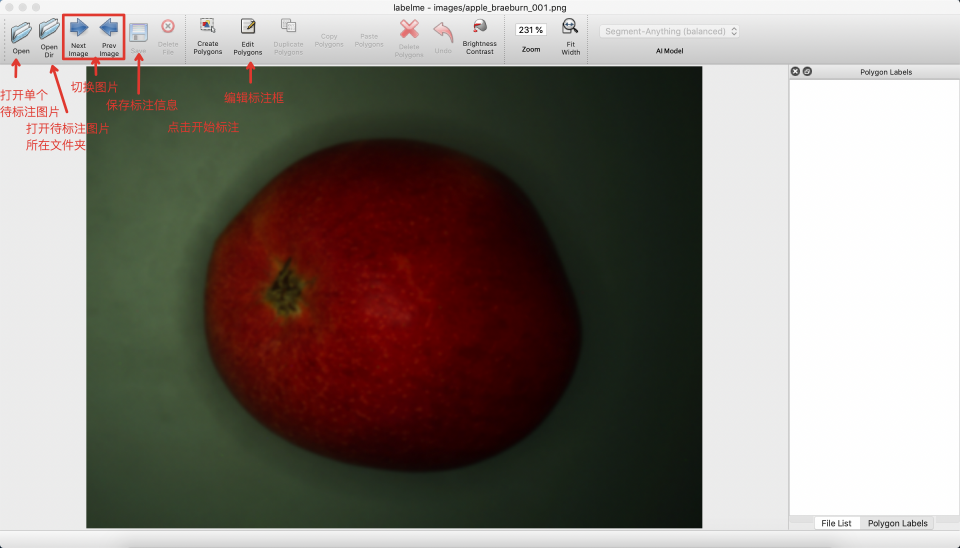
* 点击 `Edit` 选择标注类型,选则 `Create Polygons`。
* 在图片上创建多边形描绘分割区域边界。

* 再次点击选择分割区域类别。
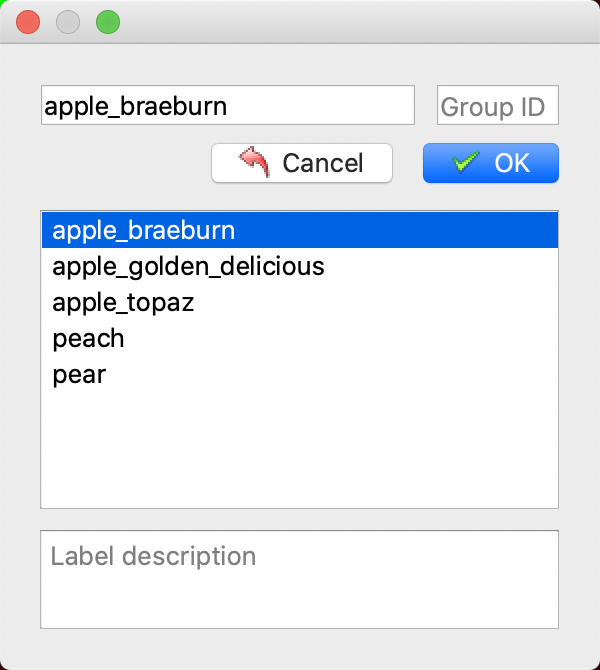
* 标注好后点击存储。(若在启动 `labelme` 时未指定 `output` 字段,会在第一次存储时提示选择存储路径,若指定 `autosave` 字段使用自动保存,则无需点击存储按钮)。
* 然后点击 `Next Image` 进行下一张图片的标注。

* 最终标注好的标签文件如图所示。
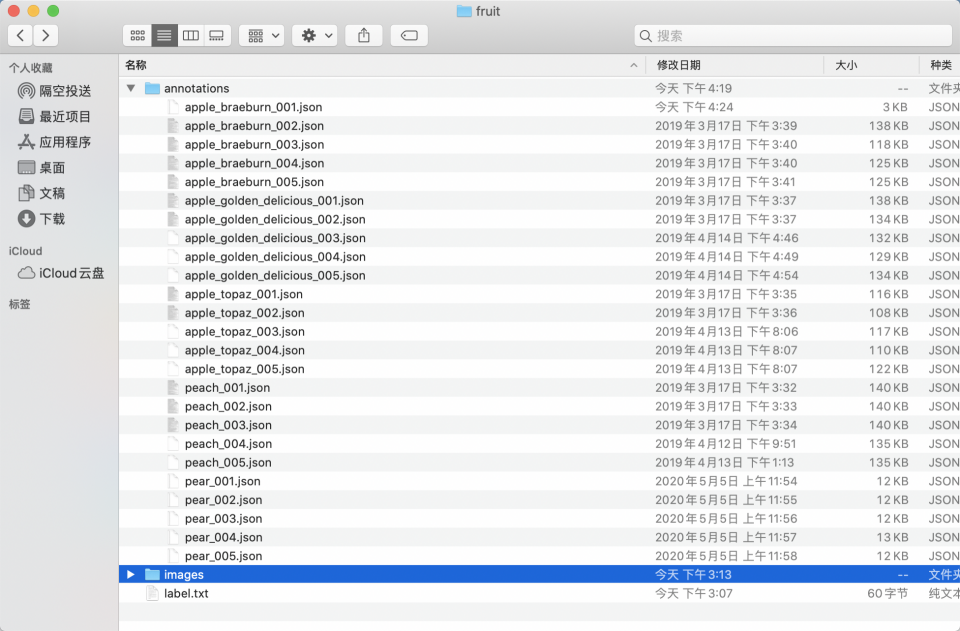
* 调整目录得到水果实例分割标准 `labelme` 格式数据集。
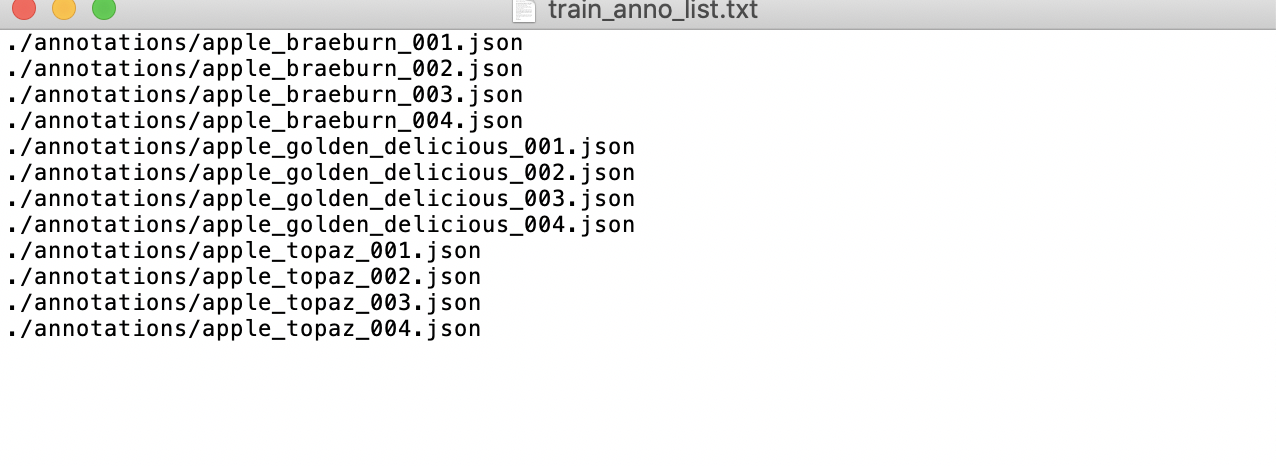
在数据集根目录创建 `train_anno_list.txt` 和 `val_anno_list.txt` 两个文本文件,并将 `annotations` 目录下的全部 `json` 文件路径按一定比例分别写入 `train_anno_list.txt` 和 `val_anno_list.txt`,也可全部写入到 `train_anno_list.txt` 同时创建一个空的 `val_anno_list.txt` 文件,待上传零代码使用数据划分功能进行重新划分。`train_anno_list.txt` 和 `val_anno_list.txt` 的具体填写格式如图所示:
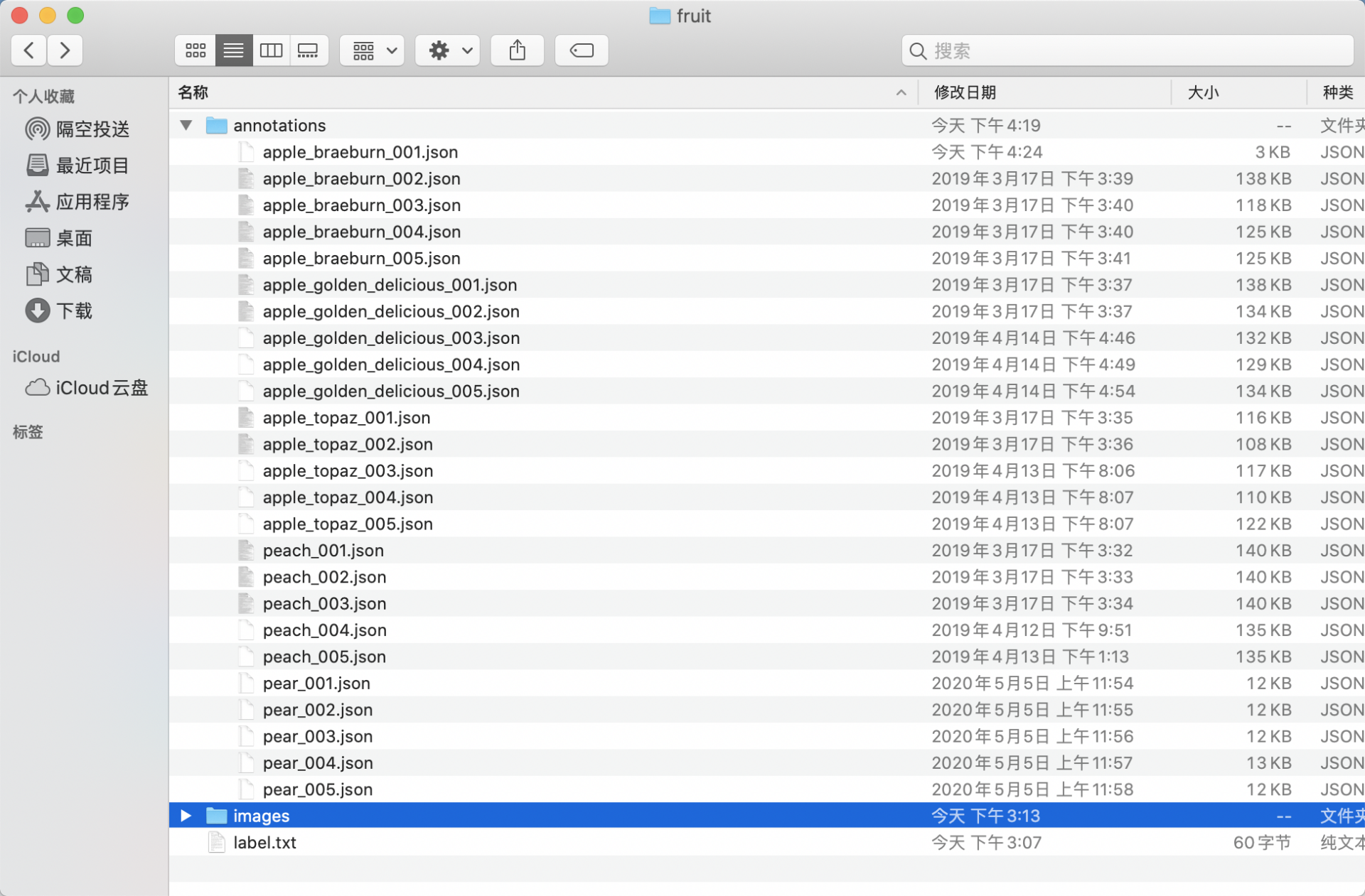
* 经过整理得到的最终目录结构如下:
* 将 `fruit` 目录打包压缩为 `.tar` 或 `.zip` 格式压缩包即可得到水果实例分割标准 `labelme` 格式数据集。
## 3. 数据格式
PaddleX 针对实例分割任务定义的数据集,名称是 **COCOInstSegDataset**,组织结构和标注格式如下:
```bash
dataset_dir # 数据集根目录,目录名称可以改变
├── annotations # 标注文件的保存目录,目录名称不可改变
│ ├── instance_train.json # 训练集标注文件,文件名称不可改变,采用COCO标注格式
│ └── instance_val.json # 验证集标注文件,文件名称不可改变,采用COCO标注格式
└── images # 图像的保存目录,目录名称不可改变
```
标注文件采用 `COCO` 格式。请大家参考上述规范准备数据,此外可以参考:[示例数据集](https://paddle-model-ecology.bj.bcebos.com/paddlex/data/instance_seg_coco_examples.tar)。
当大家使用的是 PaddleX 2.x 版本的实例分割数据集时,请参考[实例分割模块开发教程](../../module_usage/tutorials/cv_modules/instance_segmentation.md)中对应的格式转换部分,将 VOC 格式数据集转换为 COCO 数据集。(模块开发文件中注明)
**注:**
* 实例分割数据要求采用 `COCO` 数据格式标注出数据集中每张图像各个目标区域的像素边界和类别,采用 `[x1,y1,x2,y2,...,xn,yn]` 表示物体的多边形边界(segmentation)。其中,`(xn,yn)` 表示多边形各个角点坐标。标注信息存放到 `annotations` 目录下的 `json` 文件中,训练集 `instance_train.json` 和验证集 `instance_val.json` 分开存放。
* 如果你有一批未标注数据,我们推荐使用 `LabelMe` 进行数据标注。对于使用 `LabelMe` 标注的数据集,PaddleX产线支持进行数据格式转换。
* 为确保格式转换顺利完成,请严格遵循示例数据集的文件命名和组织方式: [LabelMe 示例数据集](https://paddle-model-ecology.bj.bcebos.com/paddlex/data/instance_seg_labelme_examples.tar)。



