| PP-ChatOCR-doc v3 |
paddlex_hps_PP-ChatOCRv3-doc_sdk.tar.gz |
| General image classification |
paddlex_hps_image_classification_sdk.tar.gz |
| General object detection |
paddlex_hps_object_detection_sdk.tar.gz |
| General instance segmentation |
paddlex_hps_instance_segmentation_sdk.tar.gz |
| General semantic segmentation |
paddlex_hps_semantic_segmentation_sdk.tar.gz |
| Image multi-label classification |
paddlex_hps_image_multilabel_classification_sdk.tar.gz |
| General image recognition |
paddlex_hps_PP-ShiTuV2_sdk.tar.gz |
| Pedestrian attribute recognition |
paddlex_hps_pedestrian_attribute_recognition_sdk.tar.gz |
| Vehicle attribute recognition |
paddlex_hps_vehicle_attribute_recognition_sdk.tar.gz |
| Face recognition |
paddlex_hps_face_recognition_sdk.tar.gz |
| Small object detection |
paddlex_hps_small_object_detection_sdk.tar.gz |
| Image anomaly detection |
paddlex_hps_anomaly_detection_sdk.tar.gz |
| Human keypoint detection |
paddlex_hps_human_keypoint_detection_sdk.tar.gz |
| Open vocabulary detection |
paddlex_hps_open_vocabulary_detection_sdk.tar.gz |
| Open vocabulary segmentation |
paddlex_hps_open_vocabulary_segmentation_sdk.tar.gz |
| Rotated object detection |
paddlex_hps_rotated_object_detection_sdk.tar.gz |
| 3D multi-modal fusion detection |
paddlex_hps_3d_bev_detection_sdk.tar.gz |
| General OCR |
paddlex_hps_OCR_sdk.tar.gz |
| General table recognition |
paddlex_hps_table_recognition_sdk.tar.gz |
| General table recognition v2 |
paddlex_hps_table_recognition_v2_sdk.tar.gz |
| General layout parsing |
paddlex_hps_layout_parsing_sdk.tar.gz |
| PP-StructureV3 |
paddlex_hps_PP-StructureV3_sdk.tar.gz |
| Formula recognition |
paddlex_hps_formula_recognition_sdk.tar.gz |
| Seal text recognition |
paddlex_hps_seal_recognition_sdk.tar.gz |
| Document image preprocessing |
paddlex_hps_doc_preprocessor_sdk.tar.gz |
| Time series forecasting |
paddlex_hps_ts_forecast_sdk.tar.gz |
| Time series anomaly detection |
paddlex_hps_ts_anomaly_detection_sdk.tar.gz |
| Time series classification |
paddlex_hps_ts_classification_sdk.tar.gz |
| Multilingual speech recognition |
paddlex_hps_multilingual_speech_recognition_sdk.tar.gz |
| General video classification |
paddlex_hps_video_classification_sdk.tar.gz |
| General video detection |
paddlex_hps_video_detection_sdk.tar.gz |
| Document understanding |
paddlex_hps_doc_understanding_sdk.tar.gz |
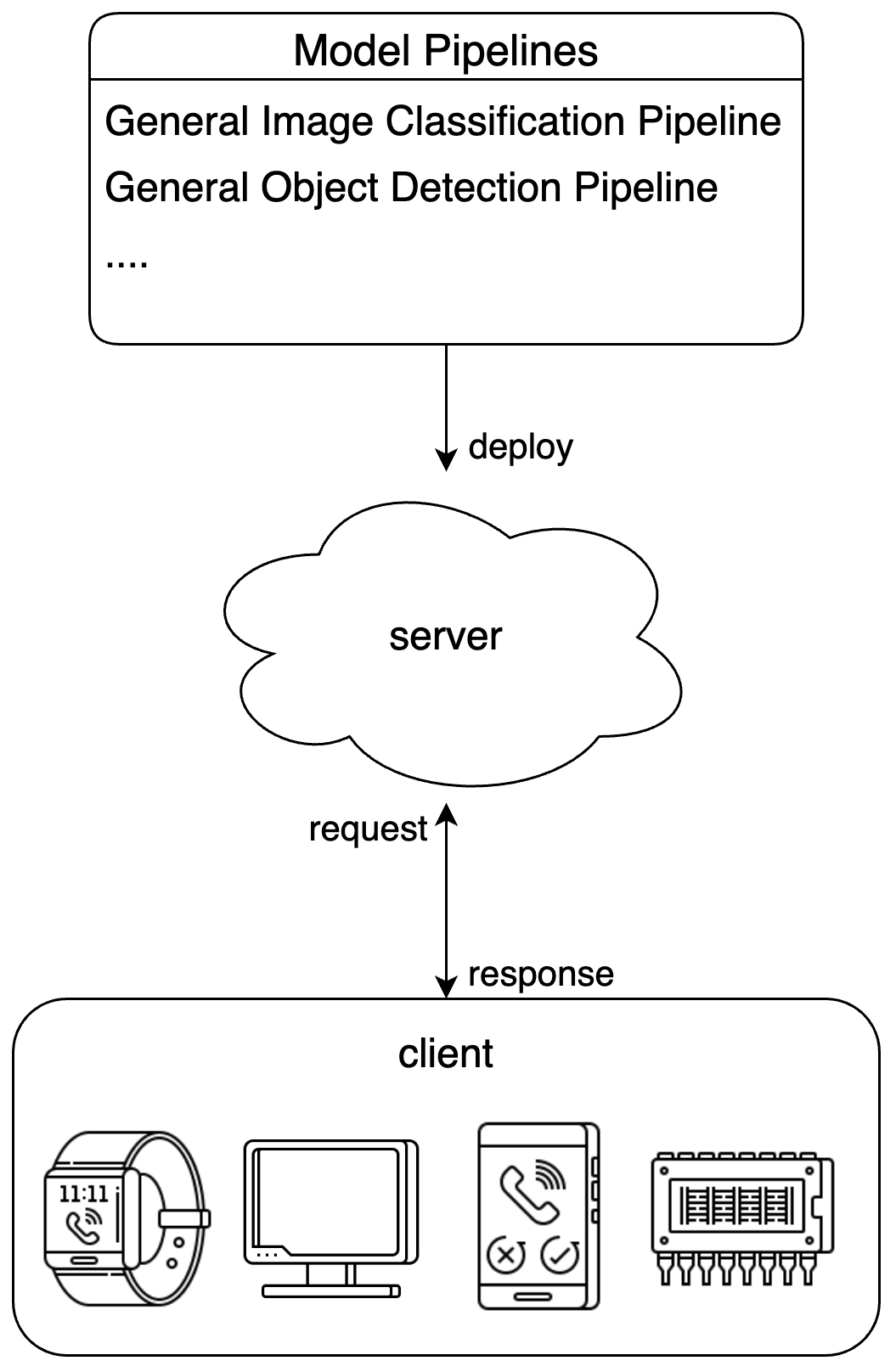 To address different user needs, PaddleX offers multiple pipeline serving solutions:
- **Basic serving**: A simple and easy-to-use serving solution with low development costs.
- **High-stability serving**: Built on [NVIDIA Triton Inference Server](https://developer.nvidia.com/triton-inference-server). Compared to basic serving, this solution offers higher stability and allows users to adjust configurations to optimize performance.
**It is recommended to first use the basic serving solution for quick verification**, and then evaluate whether to try more complex solutions based on actual needs.
Note
- PaddleX serves pipelines rather than modules.
## 1. Basic Serving
### 1.1 Install the Serving Plugin
Execute the following command to install the serving plugin:
```bash
paddlex --install serving
```
### 1.2 Run the Server
Run the server via PaddleX CLI:
```bash
paddlex --serve --pipeline {pipeline name or path to pipeline config file} [{other commandline options}]
```
Take the general image classification pipeline as an example:
```bash
paddlex --serve --pipeline image_classification
```
You can see the following information:
```text
INFO: Started server process [63108]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
```
`--pipeline` can be specified as the official pipeline name or the path to a local pipeline configuration file. PaddleX builds the pipeline and deploys it as a service. If you need to adjust configurations (such as model paths, batch size, device for deployment, etc.), please refer to the "Model Application" section in [General Image Classification Pipeline Tutorial](../pipeline_usage/tutorials/cv_pipelines/image_classification.en.md).
The command-line options related to serving are as follows:
To address different user needs, PaddleX offers multiple pipeline serving solutions:
- **Basic serving**: A simple and easy-to-use serving solution with low development costs.
- **High-stability serving**: Built on [NVIDIA Triton Inference Server](https://developer.nvidia.com/triton-inference-server). Compared to basic serving, this solution offers higher stability and allows users to adjust configurations to optimize performance.
**It is recommended to first use the basic serving solution for quick verification**, and then evaluate whether to try more complex solutions based on actual needs.
Note
- PaddleX serves pipelines rather than modules.
## 1. Basic Serving
### 1.1 Install the Serving Plugin
Execute the following command to install the serving plugin:
```bash
paddlex --install serving
```
### 1.2 Run the Server
Run the server via PaddleX CLI:
```bash
paddlex --serve --pipeline {pipeline name or path to pipeline config file} [{other commandline options}]
```
Take the general image classification pipeline as an example:
```bash
paddlex --serve --pipeline image_classification
```
You can see the following information:
```text
INFO: Started server process [63108]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
```
`--pipeline` can be specified as the official pipeline name or the path to a local pipeline configuration file. PaddleX builds the pipeline and deploys it as a service. If you need to adjust configurations (such as model paths, batch size, device for deployment, etc.), please refer to the "Model Application" section in [General Image Classification Pipeline Tutorial](../pipeline_usage/tutorials/cv_pipelines/image_classification.en.md).
The command-line options related to serving are as follows: