| Parameter |
Description |
Type |
Options |
Default Value |
input |
Data to be predicted, supports multiple input types, required |
Python Var|str|list |
- Python Var: For example, image data represented by
numpy.ndarray
- str: For example, the local path of an image file or PDF file:
/root/data/img.jpg; For URL links, such as the network URL of an image file or PDF file: Example; For local directories, the directory should contain images to be predicted, such as the local path: /root/data/ (currently does not support prediction of directories containing PDF files, PDF files need to be specified to a specific file path)
- List: List elements need to be of the above types, such as
[numpy.ndarray, numpy.ndarray], ["/root/data/img1.jpg", "/root/data/img2.jpg"], ["/root/data1", "/root/data2"]
|
None |
device |
Pipeline inference device |
str|None |
- CPU: For example,
cpu indicates using CPU for inference;
- GPU: For example,
gpu:0 indicates using the first GPU for inference;
- NPU: For example,
npu:0 indicates using the first NPU for inference;
- XPU: For example,
xpu:0 indicates using the first XPU for inference;
- MLU: For example,
mlu:0 indicates using the first MLU for inference;
- DCU: For example,
dcu:0 indicates using the first DCU for inference;
- None: If set to
None, it will use the parameter value initialized by the pipeline by default. During initialization, it will preferentially use the local GPU 0 device, if not available, it will use the CPU device;
|
None |
target_size |
Image resolution actually used during model inference |
int|-1|None|tuple[int,int] |
- int: Any integer greater than
0
- -1: If set to
-1, no rescale operation will be performed, and the original image resolution will be used for prediction
- None: If set to
None, it will use the parameter initialized by the pipeline by default. That is, the original image resolution will be used for prediction
- tuple[int,int]: The actual prediction resolution of the image will be rescaled to this size
|
None |
(3) Process the prediction results. Each prediction result is of `dict` type and supports operations such as printing, saving as an image, and saving as a `json` file:
| Method |
Description |
Parameter |
Type |
Explanation |
Default Value |
print() |
Print the result to the terminal |
format_json |
bool |
Whether to format the output content using JSON indentation |
True |
indent |
int |
Specify the indentation level to beautify the JSON data for better readability. This is only effective when format_json is True |
4 |
ensure_ascii |
bool |
Control whether non-ASCII characters are escaped to Unicode. If set to True, all non-ASCII characters will be escaped; False retains the original characters. This is only effective when format_json is True |
False |
save_to_json() |
Save the result as a JSON file |
save_path |
str |
The file path for saving. If it is a directory, the saved file will have the same name as the input file type |
None |
indent |
int |
Specify the indentation level to beautify the JSON data for better readability. This is only effective when format_json is True |
4 |
ensure_ascii |
bool |
Control whether non-ASCII characters are escaped to Unicode. If set to True, all non-ASCII characters will be escaped; False retains the original characters. This is only effective when format_json is True |
False |
save_to_img() |
Save the result as an image file |
save_path |
str |
The file path for saving, supporting both directory and file paths |
None |
- Calling the `print()` method will print the result to the terminal, with the printed content explained as follows:
- `input_path`: `(str)` The input path of the image to be predicted
- `page_index`: `(Union[int, None])` If the input is a PDF file, this indicates the current page number of the PDF; otherwise, it is `None`
- `pred`: `...` The actual mask predicted by the semantic segmentation model. Since the data is too large to print directly, it is replaced with `...`. The prediction result can be saved as an image using `res.save_to_img` and as a JSON file using `res.save_to_json`.
- Calling the `save_to_json()` method will save the above content to the specified `save_path`. If a directory is specified, the saved path will be `save_path/{your_img_basename}_res.json`. If a file is specified, it will be saved directly to that file. Since JSON files do not support saving NumPy arrays, the `numpy.array` type will be converted to a list format.
- Calling the `save_to_img()` method will save the visualization result to the specified `save_path`. If a directory is specified, the saved path will be `save_path/{your_img_basename}_res.{your_img_extension}`. If a file is specified, it will be saved directly to that file.
* Additionally, it also supports obtaining the visualization image with results and prediction results through attributes, as follows:
API Reference
For the main operations provided by the service:
- The HTTP request method is POST.
- Both the request body and response body are JSON data (JSON objects).
- When the request is successfully processed, the response status code is
200, and the attributes of the response body are as follows:
| Name |
Type |
Meaning |
logId |
string |
The UUID of the request. |
errorCode |
integer |
Error code. Fixed at 0. |
errorMsg |
string |
Error description. Fixed at "Success". |
result |
object |
Operation result. |
- When the request is not successfully processed, the attributes of the response body are as follows:
| Name |
Type |
Meaning |
logId |
string |
The UUID of the request. |
errorCode |
integer |
Error code. Same as the response status code. |
errorMsg |
string |
Error description. |
The main operations provided by the service are as follows:
Perform semantic segmentation on an image.
POST /semantic-segmentation
- The attributes of the request body are as follows:
| Name |
Type |
Meaning |
Required |
image |
string |
The URL of the image file accessible by the server or the Base64 encoded content of the image file. |
Yes |
targetSize |
integer | array | null |
Please refer to the description of the target_size parameter of the pipeline object's predict method. |
No |
- When the request is successfully processed, the
result of the response body has the following attributes:
| Name |
Type |
Meaning |
labelMap |
array |
Records the class label of each pixel in the image (arranged in row-major order). |
size |
array |
Image shape. The elements in the array are the height and width of the image, respectively. |
image |
string| null |
Semantic segmentation result image. The image is in JPEG format and encoded using Base64. |
An example of result is as follows:
{
"labelMap": [
0,
0,
1,
2
],
"size": [
2,
2
],
"image": "xxxxxx"
}
Multi-language Service Call Example
Python
import base64
import requests
API_URL = "http://localhost:8080/semantic-segmentation" # Service URL
image_path = "./demo.jpg"
output_image_path = "./out.jpg"
# Base64 encode the local image
with open(image_path, "rb") as file:
image_bytes = file.read()
image_data = base64.b64encode(image_bytes).decode("ascii")
payload = {"image": image_data} # Base64 encoded file content or image URL
# Call the API
response = requests.post(API_URL, json=payload)
# Handle the API response
assert response.status_code == 200
result = response.json()["result"]
with open(output_image_path, "wb") as file:
file.write(base64.b64decode(result["image"]))
print(f"Output image saved at {output_image_path}")
# result.labelMap records the category label of each pixel in the image (in row-major order) see API reference documentation for details
C++
#include <iostream>
#include "cpp-httplib/httplib.h" // https://github.com/Huiyicc/cpp-httplib
#include "nlohmann/json.hpp" // https://github.com/nlohmann/json
#include "base64.hpp" // https://github.com/tobiaslocker/base64
int main() {
httplib::Client client("localhost:8080");
const std::string imagePath = "./demo.jpg";
const std::string outputImagePath = "./out.jpg";
httplib::Headers headers = {
{"Content-Type", "application/json"}
};
// Base64 encode the local image
std::ifstream file(imagePath, std::ios::binary | std::ios::ate);
std::streamsize size = file.tellg();
file.seekg(0, std::ios::beg);
std::vector<char> buffer(size);
if (!file.read(buffer.data(), size)) {
std::cerr << "Error reading file." << std::endl;
return 1;
}
std::string bufferStr(reinterpret_cast<const char*>(buffer.data()), buffer.size());
std::string encodedImage = base64::to_base64(bufferStr);
nlohmann::json jsonObj;
jsonObj["image"] = encodedImage;
std::string body = jsonObj.dump();
// Call the API
auto response = client.Post("/semantic-segmentation", headers, body, "application/json");
// Handle the API response
if (response && response->status == 200) {
nlohmann::json jsonResponse = nlohmann::json::parse(response->body);
auto result = jsonResponse["result"];
encodedImage = result["image"];
std::string decodedString = base64::from_base64(encodedImage);
std::vector<unsigned char> decodedImage(decodedString.begin(), decodedString.end());
std::ofstream outputImage(outPutImagePath, std::ios::binary | std::ios::out);
if (outputImage.is_open()) {
outputImage.write(reinterpret_cast<char*>(decodedImage.data()), decodedImage.size());
outputImage.close();
std::cout << "Output image saved at " << outPutImagePath << std::endl;
// result.labelMap records the category label of each pixel in the image (in row-major order) see API reference documentation for details
} else {
std::cerr << "Unable to open file for writing: " << outPutImagePath << std::endl;
}
} else {
std::cout << "Failed to send HTTP request." << std::endl;
return 1;
}
return 0;
}
Java
import okhttp3.*;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.node.ObjectNode;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Base64;
public class Main {
public static void main(String[] args) throws IOException {
String API_URL = "http://localhost:8080/semantic-segmentation"; // Service URL
String imagePath = "./demo.jpg"; // Local image
String outputImagePath = "./out.jpg"; // Output image
// Encode the local image using Base64
File file = new File(imagePath);
byte[] fileContent = java.nio.file.Files.readAllBytes(file.toPath());
String imageData = Base64.getEncoder().encodeToString(fileContent);
ObjectMapper objectMapper = new ObjectMapper();
ObjectNode params = objectMapper.createObjectNode();
params.put("image", imageData); // Base64 encoded file content or image URL
// Create an OkHttpClient instance
OkHttpClient client = new OkHttpClient();
MediaType JSON = MediaType.Companion.get("application/json; charset=utf-8");
RequestBody body = RequestBody.Companion.create(params.toString(), JSON);
Request request = new Request.Builder()
.url(API_URL)
.post(body)
.build();
// Call the API and process the response data
try (Response response = client.newCall(request).execute()) {
if (response.isSuccessful()) {
String responseBody = response.body().string();
JsonNode resultNode = objectMapper.readTree(responseBody);
JsonNode result = resultNode.get("result");
String base64Image = result.get("image").asText();
JsonNode labelMap = result.get("labelMap");
byte[] imageBytes = Base64.getDecoder().decode(base64Image);
try (FileOutputStream fos = new FileOutputStream(outputImagePath)) {
fos.write(imageBytes);
}
System.out.println("Output image saved at " + outputImagePath);
// result.labelMap records the class labels of each pixel in the image (arranged in row-major order), see the API reference documentation for details
} else {
System.err.println("Request failed with code: " + response.code());
}
}
}
}
Go
package main
import (
"bytes"
"encoding/base64"
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
)
func main() {
API_URL := "http://localhost:8080/semantic-segmentation"
imagePath := "./demo.jpg"
outputImagePath := "./out.jpg"
// Encode the local image to Base64
imageBytes, err := ioutil.ReadFile(imagePath)
if err != nil {
fmt.Println("Error reading image file:", err)
return
}
imageData := base64.StdEncoding.EncodeToString(imageBytes)
payload := map[string]string{"image": imageData} // Base64-encoded file content or image URL
payloadBytes, err := json.Marshal(payload)
if err != nil {
fmt.Println("Error marshaling payload:", err)
return
}
// Call the API
client := &http.Client{}
req, err := http.NewRequest("POST", API_URL, bytes.NewBuffer(payloadBytes))
if err != nil {
fmt.Println("Error creating request:", err)
return
}
res, err := client.Do(req)
if err != nil {
fmt.Println("Error sending request:", err)
return
}
defer res.Body.Close()
// Process the response data
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println("Error reading response body:", err)
return
}
type Response struct {
Result struct {
Image string `json:"image"`
Labelmap []map[string]interface{} `json:"labelMap"`
} `json:"result"`
}
var respData Response
err = json.Unmarshal([]byte(string(body)), &respData)
if err != nil {
fmt.Println("Error unmarshaling response body:", err)
return
}
outputImageData, err := base64.StdEncoding.DecodeString(respData.Result.Image)
if err != nil {
fmt.Println("Error decoding base64 image data:", err)
return
}
err = ioutil.WriteFile(outputImagePath, outputImageData, 0644)
if err != nil {
fmt.Println("Error writing image to file:", err)
return
}
fmt.Printf("Image saved at %s.jpg\n", outputImagePath)
// result.labelMap records the class labels of each pixel in the image (arranged in row-major order). See the API reference for details.
}
C#
using System;
using System.IO;
using System.Net.Http;
using System.Net.Http.Headers;
using System.Text;
using System.Threading.Tasks;
using Newtonsoft.Json.Linq;
class Program
{
static readonly string API_URL = "http://localhost:8080/semantic-segmentation";
static readonly string imagePath = "./demo.jpg";
static readonly string outputImagePath = "./out.jpg";
static async Task Main(string[] args)
{
var httpClient = new HttpClient();
// Encode the local image in Base64
byte[] imageBytes = File.ReadAllBytes(imagePath);
string image_data = Convert.ToBase64String(imageBytes);
var payload = new JObject{ { "image", image_data } }; // Base64 encoded file content or image URL
var content = new StringContent(payload.ToString(), Encoding.UTF8, "application/json");
// Call the API
HttpResponseMessage response = await httpClient.PostAsync(API_URL, content);
response.EnsureSuccessStatusCode();
// Process the returned data
string responseBody = await response.Content.ReadAsStringAsync();
JObject jsonResponse = JObject.Parse(responseBody);
string base64Image = jsonResponse["result"]["image"].ToString();
byte[] outputImageBytes = Convert.FromBase64String(base64Image);
File.WriteAllBytes(outputImagePath, outputImageBytes);
Console.WriteLine($"Output image saved at {outputImagePath}");
// result.labelMap records the class label of each pixel in the image (arranged in row-major order). See the API reference documentation for details.
}
}
Node.js
const axios = require('axios');
const fs = require('fs');
const API_URL = 'http://localhost:8080/semantic-segmentation'
const imagePath = './demo.jpg'
const outputImagePath = "./out.jpg";
let config = {
method: 'POST',
maxBodyLength: Infinity,
url: API_URL,
data: JSON.stringify({
'image': encodeImageToBase64(imagePath) // Base64 encoded file content or image URL
})
};
// Base64 encode the local image
function encodeImageToBase64(filePath) {
const bitmap = fs.readFileSync(filePath);
return Buffer.from(bitmap).toString('base64');
}
// Call the API
axios.request(config)
.then((response) => {
// Handle the API response
const result = response.data["result"];
const imageBuffer = Buffer.from(result["image"], 'base64');
fs.writeFile(outputImagePath, imageBuffer, (err) => {
if (err) throw err;
console.log(`Output image saved at ${outputImagePath}`);
});
// result.labelMap records the category label of each pixel in the image (in row-major order) see API reference documentation for details
})
.catch((error) => {
console.log(error);
});
PHP
<?php
$API_URL = "http://localhost:8080/semantic-segmentation"; // Service URL
$image_path = "./demo.jpg";
$output_image_path = "./out.jpg";
// Encode the local image using Base64
$image_data = base64_encode(file_get_contents($image_path));
$payload = array("image" => $image_data); // Base64 encoded file content or image URL
// Call the API
$ch = curl_init($API_URL);
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, json_encode($payload));
curl_setopt($ch, CURLOPT_HTTPHEADER, array('Content-Type: application/json'));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$response = curl_exec($ch);
curl_close($ch);
// Process the response data
$result = json_decode($response, true)["result"];
file_put_contents($output_image_path, base64_decode($result["image"]));
echo "Output image saved at " . $output_image_path . "\n";
// result.labelMap records the class labels of each pixel in the image (arranged in row-major order), see the API reference documentation for details
?>

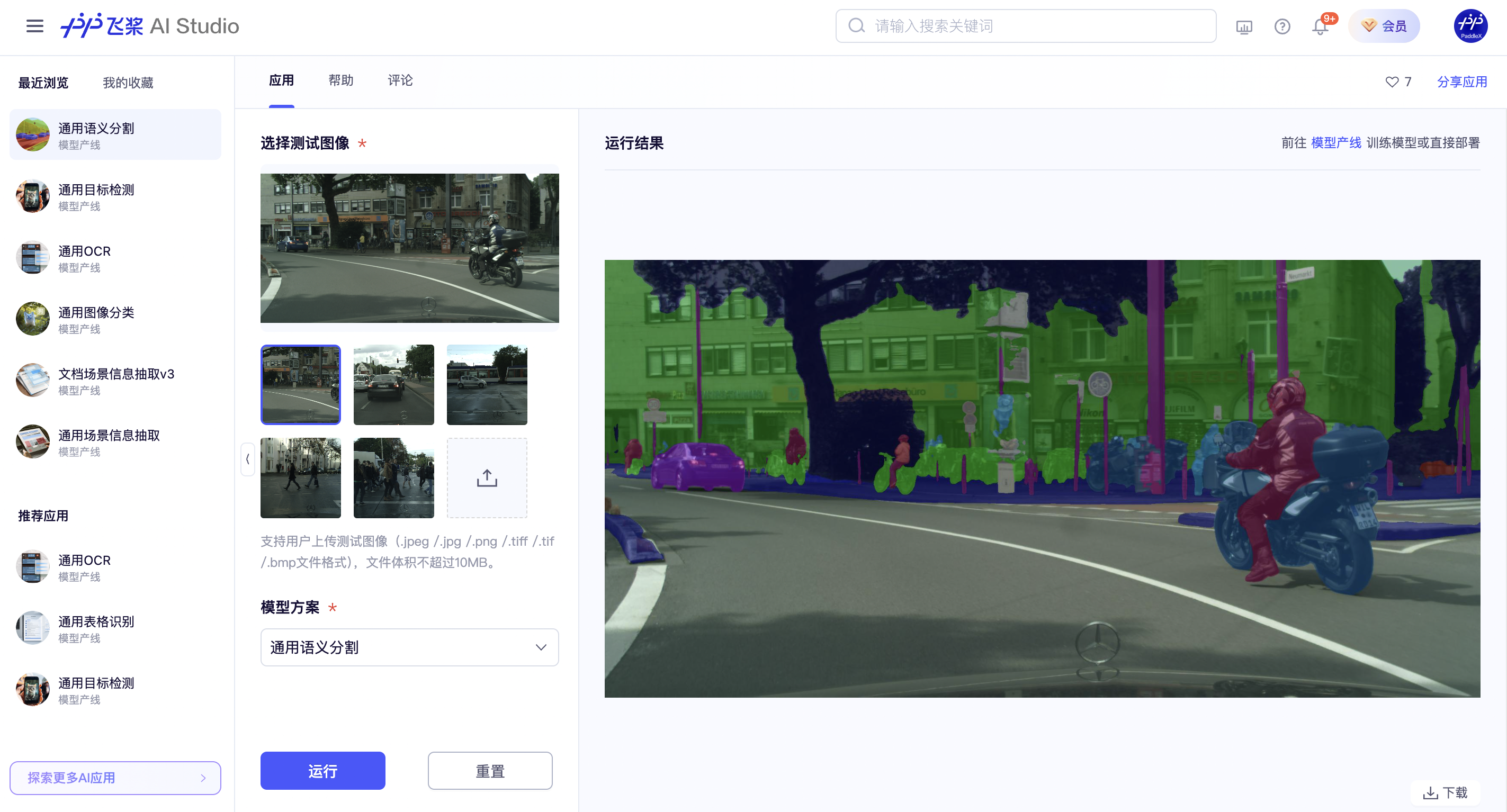 If you are satisfied with the pipeline's performance, you can directly integrate and deploy it. If not, you can also use your private data to fine-tune the model in the pipeline online.
### 2.2 Local Experience
> ❗ Before using the general semantic segmentation pipeline locally, please ensure that you have completed the installation of the PaddleX wheel package according to the [PaddleX Local Installation Guide](../../../installation/installation.en.md).
#### 2.2.1 Command Line Experience
* You can quickly experience the semantic segmentation pipeline effect with a single command. Use the [test file](https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/application/semantic_segmentation/makassaridn-road_demo.png), and replace `--input` with the local path for prediction.
```bash
paddlex --pipeline semantic_segmentation \
--input makassaridn-road_demo.png \
--target_size -1 \
--save_path ./output \
--device gpu:0 \
```
The relevant parameter descriptions can be referred to in the parameter explanations in [2.2.2 Python Script Integration]().
After running, the result will be printed to the terminal, as follows:
```bash
{'res': {'input_path': 'makassaridn-road_demo.png', 'page_index': None, 'pred': '...'}}
```
The explanation of the output result parameters can be found in the [2.2.2 Integration with Python Script](#222-integration-with-python-script) section.
The visualization results are saved under `save_path`, and the visualization result of semantic segmentation is as follows:
If you are satisfied with the pipeline's performance, you can directly integrate and deploy it. If not, you can also use your private data to fine-tune the model in the pipeline online.
### 2.2 Local Experience
> ❗ Before using the general semantic segmentation pipeline locally, please ensure that you have completed the installation of the PaddleX wheel package according to the [PaddleX Local Installation Guide](../../../installation/installation.en.md).
#### 2.2.1 Command Line Experience
* You can quickly experience the semantic segmentation pipeline effect with a single command. Use the [test file](https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/application/semantic_segmentation/makassaridn-road_demo.png), and replace `--input` with the local path for prediction.
```bash
paddlex --pipeline semantic_segmentation \
--input makassaridn-road_demo.png \
--target_size -1 \
--save_path ./output \
--device gpu:0 \
```
The relevant parameter descriptions can be referred to in the parameter explanations in [2.2.2 Python Script Integration]().
After running, the result will be printed to the terminal, as follows:
```bash
{'res': {'input_path': 'makassaridn-road_demo.png', 'page_index': None, 'pred': '...'}}
```
The explanation of the output result parameters can be found in the [2.2.2 Integration with Python Script](#222-integration-with-python-script) section.
The visualization results are saved under `save_path`, and the visualization result of semantic segmentation is as follows:
 #### 2.2.2 Integration with Python Script
* The above command line is for quickly experiencing and viewing the effect. Generally, in a project, it is often necessary to integrate through code. You can complete the fast inference of the pipeline with just a few lines of code. The inference code is as follows:
```python
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="semantic_segmentation")
output = pipeline.predict(input="makassaridn-road_demo.png", target_size = -1)
for res in output:
res.print()
res.save_to_img(save_path="./output/")
res.save_to_json(save_path="./output/")
```
In the above Python script, the following steps are executed:
(1) The semantic segmentation pipeline object is instantiated via `create_pipeline()`, with the following parameter descriptions:
#### 2.2.2 Integration with Python Script
* The above command line is for quickly experiencing and viewing the effect. Generally, in a project, it is often necessary to integrate through code. You can complete the fast inference of the pipeline with just a few lines of code. The inference code is as follows:
```python
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="semantic_segmentation")
output = pipeline.predict(input="makassaridn-road_demo.png", target_size = -1)
for res in output:
res.print()
res.save_to_img(save_path="./output/")
res.save_to_json(save_path="./output/")
```
In the above Python script, the following steps are executed:
(1) The semantic segmentation pipeline object is instantiated via `create_pipeline()`, with the following parameter descriptions:
{kind=link}