👉 校验结果详情(点击展开)
校验结果文件具体内容为:
{
"done_flag": true,
"check_pass": true,
"attributes": {
"train_samples": 606,
"train_sample_paths": [
"..\/ocr_curve_det_dataset_examples\/images\/circle_Aug07834.png",
"..\/ocr_curve_det_dataset_examples\/images\/circle_Aug09943.png",
"..\/ocr_curve_det_dataset_examples\/images\/circle_Aug04079.png",
"..\/ocr_curve_det_dataset_examples\/images\/circle_Aug05701.png",
"..\/ocr_curve_det_dataset_examples\/images\/circle_Aug08324.png",
"..\/ocr_curve_det_dataset_examples\/images\/circle_Aug07451.png",
"..\/ocr_curve_det_dataset_examples\/images\/circle_Aug09562.png",
"..\/ocr_curve_det_dataset_examples\/images\/circle_Aug08237.png",
"..\/ocr_curve_det_dataset_examples\/images\/circle_Aug01788.png",
"..\/ocr_curve_det_dataset_examples\/images\/circle_Aug06481.png"
],
"val_samples": 152,
"val_sample_paths": [
"..\/ocr_curve_det_dataset_examples\/images\/circle_Aug03724.png",
"..\/ocr_curve_det_dataset_examples\/images\/circle_Aug06456.png",
"..\/ocr_curve_det_dataset_examples\/images\/circle_Aug04029.png",
"..\/ocr_curve_det_dataset_examples\/images\/circle_Aug03603.png",
"..\/ocr_curve_det_dataset_examples\/images\/circle_Aug05454.png",
"..\/ocr_curve_det_dataset_examples\/images\/circle_Aug06269.png",
"..\/ocr_curve_det_dataset_examples\/images\/circle_Aug00624.png",
"..\/ocr_curve_det_dataset_examples\/images\/circle_Aug02818.png",
"..\/ocr_curve_det_dataset_examples\/images\/circle_Aug00538.png",
"..\/ocr_curve_det_dataset_examples\/images\/circle_Aug04935.png"
]
},
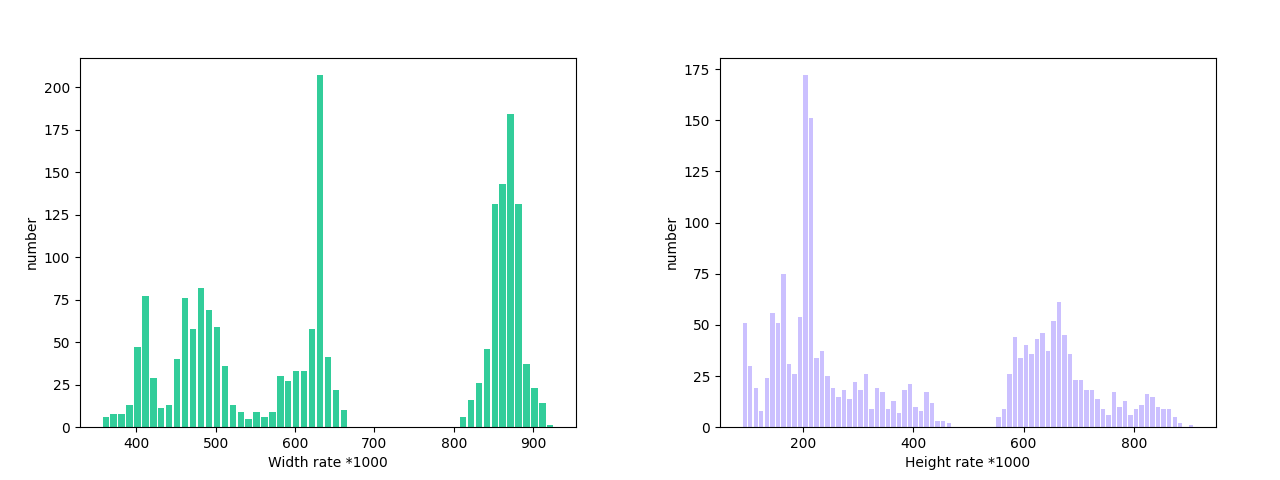
"analysis": {
"histogram": "check_dataset\/histogram.png"
},
"dataset_path": ".\/ocr_curve_det_dataset_examples",
"show_type": "image",
"dataset_type": "TextDetDataset"
}
上述校验结果中,check_pass 为 True 表示数据集格式符合要求,其他部分指标的说明如下:
attributes.train_samples:该数据集训练集样本数量为 606;attributes.val_samples:该数据集验证集样本数量为 152;attributes.train_sample_paths:该数据集训练集样本可视化图片相对路径列表;attributes.val_sample_paths:该数据集验证集样本可视化图片相对路径列表;
数据集校验还对数据集中所有类别的样本数量分布情况进行了分析,并绘制了分布直方图(histogram.png):