 The General OCR pipeline includes mandatory text detection and text recognition modules, as well as optional document image orientation classification, text image correction, and text line orientation classification modules. The document image orientation classification and text image correction modules are integrated as a document preprocessing sub-line into the General OCR pipeline. Each module contains multiple models, and you can choose the model based on the benchmark test data below.
If you prioritize model accuracy, choose a high-accuracy model; if you prioritize inference speed, choose a faster inference model; if you care about model storage size, choose a smaller model.
The General OCR pipeline includes mandatory text detection and text recognition modules, as well as optional document image orientation classification, text image correction, and text line orientation classification modules. The document image orientation classification and text image correction modules are integrated as a document preprocessing sub-line into the General OCR pipeline. Each module contains multiple models, and you can choose the model based on the benchmark test data below.
If you prioritize model accuracy, choose a high-accuracy model; if you prioritize inference speed, choose a faster inference model; if you care about model storage size, choose a smaller model.
Document Image Orientation Classification Module (Optional):
| Model | Model Download Link | Top-1 Acc (%) | CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (M) | Introduction |
|---|---|---|---|---|---|---|
| PP-LCNet_x1_0_doc_ori | Inference Model/Training Model | 99.06 | 2.31 / 0.43 | 3.37 / 1.27 | 7 | A document image classification model based on PP-LCNet_x1_0, with four categories: 0 degrees, 90 degrees, 180 degrees, and 270 degrees. |
Text Image Correction Module (Optional):
| Model | Model Download Link | CER | Model Storage Size (M) | Introduction |
|---|---|---|---|---|
| UVDoc | Inference Model/Training Model | 0.179 | 30.3 M | High-precision text image correction model |
Text Detection Module:
| Model | Model Download Link | Detection Hmean (%) | CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (M) | Introduction |
|---|---|---|---|---|---|---|
| PP-OCRv4_server_det | Inference Model/Training Model | 82.56 | 83.34 / 80.91 | 442.58 / 442.58 | 109 | The server-side text detection model of PP-OCRv4, with higher accuracy, suitable for deployment on high-performance servers |
| PP-OCRv4_mobile_det | Inference Model/Training Model | 77.35 | 8.79 / 3.13 | 51.00 / 28.58 | 4.7 | The mobile text detection model of PP-OCRv4, with higher efficiency, suitable for deployment on edge devices |
| PP-OCRv3_mobile_det | Inference Model/Training Model | 78.68 | 8.44 / 2.91 | 27.87 / 27.87 | 2.1 | The mobile text detection model of PP-OCRv3, with higher efficiency, suitable for deployment on edge devices |
| PP-OCRv3_server_det | Inference Model/Training Model | 80.11 | 65.41 / 13.67 | 305.07 / 305.07 | 102.1 | The server-side text detection model of PP-OCRv3, with higher accuracy, suitable for deployment on high-performance servers |
Text Recognition Module:
| Model | Model Download Link | Recognition Avg Accuracy (%) | CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (M) | Introduction |
|---|---|---|---|---|---|---|
| PP-OCRv4_server_rec_doc | Inference Model/Training Model | 81.53 | 6.65 / 6.65 | 32.92 / 32.92 | 74.7 M | PP-OCRv4_server_rec_doc is trained on a mixed dataset of more Chinese document data and PP-OCR training data, based on PP-OCRv4_server_rec. It enhances the recognition of traditional Chinese characters, Japanese, and special characters, supporting over 15,000 characters. It improves both document-related and general text recognition capabilities. |
| PP-OCRv4_mobile_rec | Inference Model/Training Model | 78.74 | 4.82 / 4.82 | 16.74 / 4.64 | 10.6 M | The lightweight recognition model of PP-OCRv4, with high inference efficiency, suitable for deployment on various hardware devices, including edge devices |
| PP-OCRv4_server_rec | Inference Model/Training Model | 80.61 | 6.58 / 6.58 | 33.17 / 33.17 | 71.2 M | The server-side recognition model of PP-OCRv4, with high inference accuracy, suitable for deployment on various servers |
| en_PP-OCRv4_mobile_rec | Inference Model/Training Model | 70.39 | 4.81 / 4.81 | 16.10 / 5.31 | 6.8 M | The ultra-lightweight English recognition model trained based on the PP-OCRv4 recognition model, supporting English and numeric recognition |
| Model | Model Download Link | Recognition Avg Accuracy(%) | CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (M) | Introduction |
|---|---|---|---|---|---|---|
| PP-OCRv4_server_rec_doc | Inference Model/Training Model | 6.65 / 6.65 | 32.92 / 32.92 | PP-OCRv4_server_rec_doc is trained on a mixed dataset of more Chinese document data and PP-OCR training data based on PP-OCRv4_server_rec. It has added the recognition capabilities for some traditional Chinese characters, Japanese, and special characters. The number of recognizable characters is over 15,000. In addition to the improvement in document-related text recognition, it also enhances the general text recognition capability. | ||
| PP-OCRv4_mobile_rec | Inference Model/Training Model | 78.20 | 4.82 / 4.82 | 16.74 / 4.64 | 10.6 M | The PP-OCRv4 recognition model is an upgrade from PP-OCRv3. Under comparable speed conditions, the effect in Chinese and English scenarios is further improved. The average recognition accuracy of the 80 multilingual models is increased by more than 8%. |
| PP-OCRv4_server_rec | Inference Model/Trained Model | 79.20 | 6.58 / 6.58 | 33.17 / 33.17 | 71.2 M | A high-precision server text recognition model, featuring high accuracy, fast speed, and multilingual support. It is suitable for text recognition tasks in various scenarios. |
| PP-OCRv3_mobile_rec | Inference Model/Training Model | 5.87 / 5.87 | 9.07 / 4.28 | An ultra-lightweight OCR model suitable for mobile applications. It adopts an encoder-decoder structure based on Transformer and enhances recognition accuracy and efficiency through techniques such as data augmentation and mixed precision training. The model size is 10.6M, making it suitable for deployment on resource-constrained devices. It can be used in scenarios such as mobile photo translation and business card recognition. |
| Model | Model Download Link | Recognition Avg Accuracy(%) | GPU Inference Time (ms) | CPU Inference Time | Model Storage Size (M) | Introduction |
|---|---|---|---|---|---|---|
| ch_SVTRv2_rec | Inference Model/Training Model | 68.81 | 8.36801 | 165.706 | 73.9 M | SVTRv2 is a server text recognition model developed by the OpenOCR team of Fudan University's Visual and Learning Laboratory (FVL). It won the first prize in the PaddleOCR Algorithm Model Challenge - Task One: OCR End-to-End Recognition Task. The end-to-end recognition accuracy on the A list is 6% higher than that of PP-OCRv4. |
| Model | Model Download Link | Recognition Avg Accuracy(%) | GPU Inference Time (ms) | CPU Inference Time | Model Storage Size (M) | Introduction |
|---|---|---|---|---|---|---|
| ch_RepSVTR_rec | Inference Model/Training Model | 65.07 | 10.5047 | 51.5647 | 22.1 M | The RepSVTR text recognition model is a mobile text recognition model based on SVTRv2. It won the first prize in the PaddleOCR Algorithm Model Challenge - Task One: OCR End-to-End Recognition Task. The end-to-end recognition accuracy on the B list is 2.5% higher than that of PP-OCRv4, with the same inference speed. |
| Model | Model Download Link | Recognition Avg Accuracy(%) | GPU Inference Time (ms) | CPU Inference Time | Model Storage Size (M) | Introduction |
|---|---|---|---|---|---|---|
| en_PP-OCRv4_mobile_rec | Inference Model/Training Model | [Latest] Further upgraded based on PP-OCRv3, with improved accuracy under comparable speed conditions. | ||||
| en_PP-OCRv3_mobile_rec | Inference Model/Training Model | Ultra-lightweight model, supporting English and numeric recognition. |
| Model | Model Download Link | Recognition Avg Accuracy(%) | GPU Inference Time (ms) | CPU Inference Time | Model Storage Size (M) | Introduction |
|---|---|---|---|---|---|---|
| korean_PP-OCRv3_mobile_rec | Inference Model/Training Model | Korean Recognition | ||||
| japan_PP-OCRv3_mobile_rec | Inference Model/Training Model | Japanese Recognition | ||||
| chinese_cht_PP-OCRv3_mobile_rec | Inference Model/Training Model | Traditional Chinese Recognition | ||||
| te_PP-OCRv3_mobile_rec | Inference Model/Training Model | Telugu Recognition | ||||
| ka_PP-OCRv3_mobile_rec | Inference Model/Training Model | Kannada Recognition | ||||
| ta_PP-OCRv3_mobile_rec | Inference Model/Training Model | Tamil Recognition | ||||
| latin_PP-OCRv3_mobile_rec | Inference Model/Training Model | Latin Recognition | ||||
| arabic_PP-OCRv3_mobile_rec | Inference Model/Training Model | Arabic Script Recognition | ||||
| cyrillic_PP-OCRv3_mobile_rec | Inference Model/Training Model | Cyrillic Script Recognition | ||||
| devanagari_PP-OCRv3_mobile_rec | Inference Model/Training Model | Devanagari Script Recognition |
Text Line Orientation Classification Module (Optional):
| Model | Model Download Link | Top-1 Acc (%) | CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (M) | Introduction |
|---|---|---|---|---|---|---|
| PP-LCNet_x0_25_textline_ori | Inference Model/ Training Model | 95.54 | - | - | 0.32 | A text line orientation classification model based on PP-LCNet_x0_25, with two categories: 0 degrees and 180 degrees. |
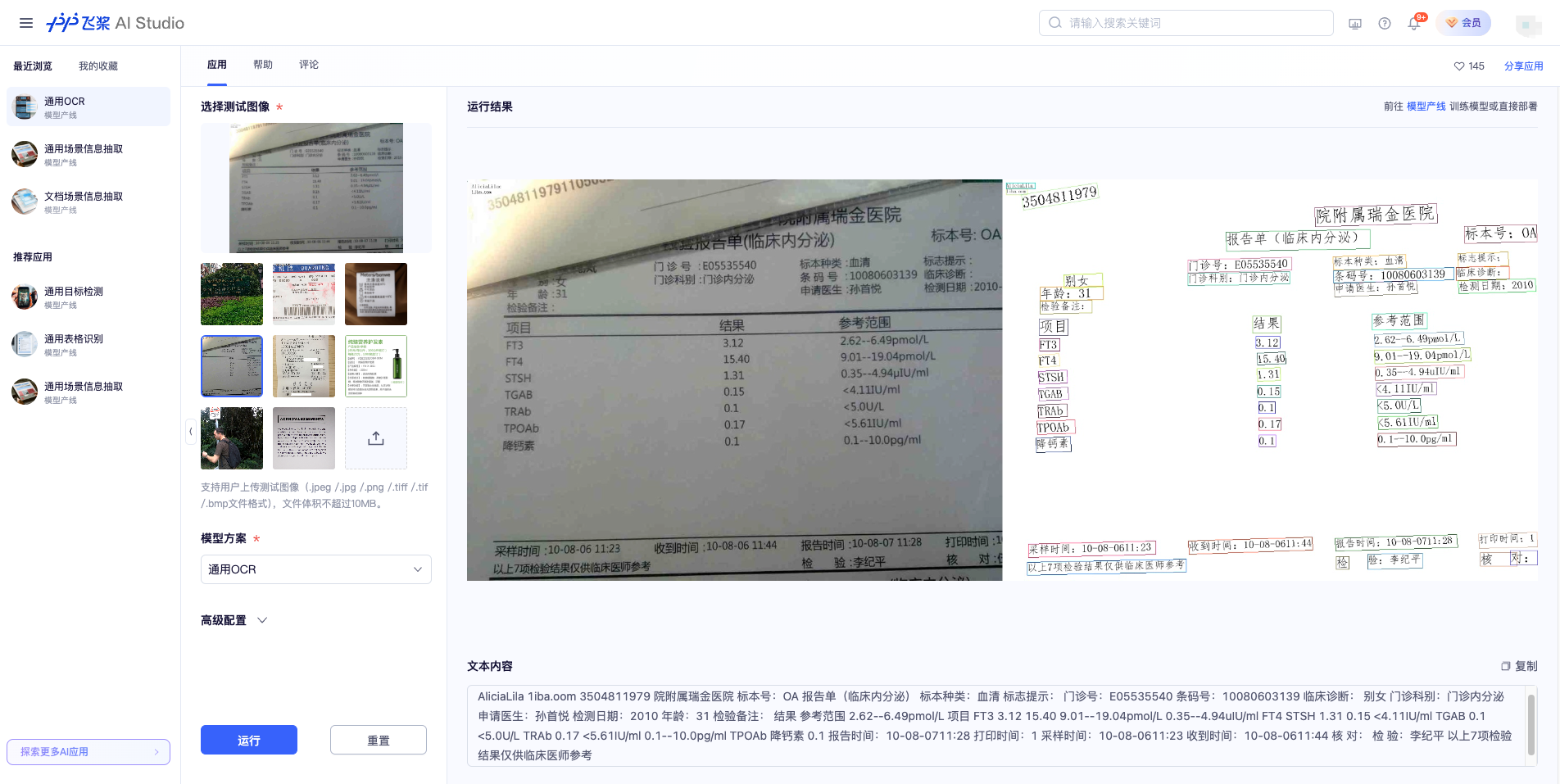 If you are satisfied with the performance of the pipeline, you can directly integrate and deploy it. You can choose to download the deployment package from the cloud, or refer to the methods in [Section 2.2 Local Experience](#22-local-experience) for local deployment. If you are not satisfied with the effect, you can fine-tune the models in the pipeline using your private data. If you have local hardware resources for training, you can start training directly on your local machine; if not, the Star River Zero-Code platform provides a one-click training service. You don't need to write any code—just upload your data and start the training task with one click.
### 2.2 Local Experience
> ❗ Before using the general OCR pipeline locally, please ensure that you have completed the installation of the PaddleX wheel package according to the [PaddleX Installation Guide](../../../installation/installation.en.md).
#### 2.2.1 Command Line Experience
* You can quickly experience the OCR pipeline with a single command. Use the [test image](https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png), and replace `--input` with the local path for prediction.
```bash
paddlex --pipeline OCR \
--input general_ocr_002.png \
--use_doc_orientation_classify False \
--use_doc_unwarping False \
--use_textline_orientation False \
--save_path ./output \
--device gpu:0
```
For details on the relevant parameter descriptions, please refer to the parameter descriptions in [2.2.2 Python Script Integration](#222-python-script-integration).
After running, the results will be printed to the terminal as follows:
```bash
{'res': {'input_path': 'general_ocr_002.png', 'model_settings': {'use_doc_preprocessor': False, 'use_textline_orientation': False}, 'doc_preprocessor_res': {'input_path': '0.jpg', 'model_settings': {'use_doc_orientation_classify': True, 'use_doc_unwarping': False}, 'angle': 0},'dt_polys': [array([[ 3, 10],
[82, 10],
[82, 33],
[ 3, 33]], dtype=int16), ...], 'text_det_params': {'limit_side_len': 960, 'limit_type': 'max', 'thresh': 0.3, 'box_thresh': 0.6, 'unclip_ratio': 2.0}, 'text_type': 'general', 'textline_orientation_angles': [-1, ...], 'text_rec_score_thresh': 0.0, 'rec_texts': ['www.99*', ...], 'rec_scores': [0.8980069160461426, ...], 'rec_polys': [array([[ 3, 10],
[82, 10],
[82, 33],
[ 3, 33]], dtype=int16), ...], 'rec_boxes': array([[ 3, 10, 82, 33], ...], dtype=int16)}}
```
The visualized results are saved under `save_path`, and the OCR visualization results are as follows:
If you are satisfied with the performance of the pipeline, you can directly integrate and deploy it. You can choose to download the deployment package from the cloud, or refer to the methods in [Section 2.2 Local Experience](#22-local-experience) for local deployment. If you are not satisfied with the effect, you can fine-tune the models in the pipeline using your private data. If you have local hardware resources for training, you can start training directly on your local machine; if not, the Star River Zero-Code platform provides a one-click training service. You don't need to write any code—just upload your data and start the training task with one click.
### 2.2 Local Experience
> ❗ Before using the general OCR pipeline locally, please ensure that you have completed the installation of the PaddleX wheel package according to the [PaddleX Installation Guide](../../../installation/installation.en.md).
#### 2.2.1 Command Line Experience
* You can quickly experience the OCR pipeline with a single command. Use the [test image](https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png), and replace `--input` with the local path for prediction.
```bash
paddlex --pipeline OCR \
--input general_ocr_002.png \
--use_doc_orientation_classify False \
--use_doc_unwarping False \
--use_textline_orientation False \
--save_path ./output \
--device gpu:0
```
For details on the relevant parameter descriptions, please refer to the parameter descriptions in [2.2.2 Python Script Integration](#222-python-script-integration).
After running, the results will be printed to the terminal as follows:
```bash
{'res': {'input_path': 'general_ocr_002.png', 'model_settings': {'use_doc_preprocessor': False, 'use_textline_orientation': False}, 'doc_preprocessor_res': {'input_path': '0.jpg', 'model_settings': {'use_doc_orientation_classify': True, 'use_doc_unwarping': False}, 'angle': 0},'dt_polys': [array([[ 3, 10],
[82, 10],
[82, 33],
[ 3, 33]], dtype=int16), ...], 'text_det_params': {'limit_side_len': 960, 'limit_type': 'max', 'thresh': 0.3, 'box_thresh': 0.6, 'unclip_ratio': 2.0}, 'text_type': 'general', 'textline_orientation_angles': [-1, ...], 'text_rec_score_thresh': 0.0, 'rec_texts': ['www.99*', ...], 'rec_scores': [0.8980069160461426, ...], 'rec_polys': [array([[ 3, 10],
[82, 10],
[82, 33],
[ 3, 33]], dtype=int16), ...], 'rec_boxes': array([[ 3, 10, 82, 33], ...], dtype=int16)}}
```
The visualized results are saved under `save_path`, and the OCR visualization results are as follows:
 #### 2.2.2 Python Script Integration
* The above command line is for quick experience and effect checking. Generally, in a project, integration through code is often required. You can complete the quick inference of the pipeline with just a few lines of code. The inference code is as follows:
```python
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="OCR")
output = pipeline.predict(
input="./general_ocr_002.png",
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_textline_orientation=False,
)
for res in output:
res.print()
res.save_to_img(save_path="./output/")
res.save_to_json(save_path="./output/")
```
In the above Python script, the following steps are executed:
(1) The OCR pipeline object is instantiated via `create_pipeline()`, with specific parameter descriptions as follows:
#### 2.2.2 Python Script Integration
* The above command line is for quick experience and effect checking. Generally, in a project, integration through code is often required. You can complete the quick inference of the pipeline with just a few lines of code. The inference code is as follows:
```python
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="OCR")
output = pipeline.predict(
input="./general_ocr_002.png",
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_textline_orientation=False,
)
for res in output:
res.print()
res.save_to_img(save_path="./output/")
res.save_to_json(save_path="./output/")
```
In the above Python script, the following steps are executed:
(1) The OCR pipeline object is instantiated via `create_pipeline()`, with specific parameter descriptions as follows:
| Parameter | Description | Type | Default Value |
|---|---|---|---|
pipeline |
The name of the pipeline or the path to the pipeline configuration file. If it is a pipeline name, it must be supported by PaddleX. | str |
None |
config |
Specific configuration information for the pipeline (if set simultaneously with the pipeline, it takes precedence over the pipeline, and the pipeline name must match the pipeline).
|
dict[str, Any] |
None |
device |
The device used for pipeline inference. It supports specifying specific GPU card numbers, such as "gpu:0", other hardware card numbers, such as "npu:0", or CPU, such as "cpu". | str |
gpu:0 |
use_hpip |
Whether to enable high-performance inference. This is only available if the pipeline supports high-performance inference. | bool |
False |
| Parameter | Description | Type | Options | Default Value |
|---|---|---|---|---|
input |
Data to be predicted, supports multiple input types (required). | Python Var|str|list |
|
None |
device |
The device used for inference. | str|None |
|
None |
use_doc_orientation_classify |
Whether to use the document orientation classification module. | bool|None |
|
None |
use_doc_unwarping |
Whether to use the document unwarping module. | bool|None |
|
None |
use_textline_orientation |
Whether to use the text line orientation classification module. | bool|None |
|
None |
text_det_limit_side_len |
The limit on the side length of the image for text detection. | int|None |
|
None |
text_det_limit_type |
The type of limit on the side length of the image for text detection. | str|None |
|
None |
text_det_thresh |
The detection pixel threshold. Pixels with scores greater than this threshold in the output probability map will be considered as text pixels. | float|None |
|
None |
text_det_box_thresh |
The detection box threshold. A detection result will be considered as a text region if the average score of all pixels within the bounding box is greater than this threshold. | float|None |
|
None |
text_det_unclip_ratio |
The text detection expansion ratio. The larger this value, the larger the expanded area. | float|None |
|
None |
text_rec_score_thresh |
The text recognition score threshold. Text results with scores greater than this threshold will be retained. | float|None |
|
None |
| Method | Description | Parameter | Parameter Type | Parameter Description | Default Value |
|---|---|---|---|---|---|
print() |
Print the result to the terminal | format_json |
bool |
Whether to format the output content using JSON indentation |
True |
indent |
int |
Specify the indentation level to beautify the output JSON data, making it more readable. This is only effective when format_json is True |
4 | ||
ensure_ascii |
bool |
Control whether non-ASCII characters are escaped to Unicode. When set to True, all non-ASCII characters will be escaped; False retains the original characters. This is only effective when format_json is True |
False |
||
save_to_json() |
Save the result as a JSON file | save_path |
str |
The file path for saving. When a directory is specified, the saved file name will match the input file name | None |
indent |
int |
Specify the indentation level to beautify the output JSON data, making it more readable. This is only effective when format_json is True |
4 | ||
ensure_ascii |
bool |
Control whether non-ASCII characters are escaped to Unicode. When set to True, all non-ASCII characters will be escaped; False retains the original characters. This is only effective when format_json is True |
False |
||
save_to_img() |
Save the result as an image file | save_path |
str |
The file path for saving, supporting both directory and file paths | None |
| Attribute | Description |
|---|---|
json |
Get the prediction results in json format |
img |
Get the visualization image in dict format |
For the main operations provided by the service:
200, and the attributes of the response body are as follows:| Name | Type | Meaning |
|---|---|---|
logId |
string |
The UUID of the request. |
errorCode |
integer |
Error code. Fixed as 0. |
errorMsg |
string |
Error message. Fixed as "Success". |
result |
object |
The result of the operation. |
| Name | Type | Meaning |
|---|---|---|
logId |
string |
The UUID of the request. |
errorCode |
integer |
Error code. Same as the response status code. |
errorMsg |
string |
Error message. |
The main operations provided by the service are as follows:
inferObtain OCR results from images.
POST /ocr
| Name | Type | Meaning | Required |
|---|---|---|---|
file |
string |
The URL of an image or PDF file accessible by the server, or the Base64-encoded content of the file. For PDF files exceeding 10 pages, only the first 10 pages will be used. | Yes |
fileType |
integer | null |
The type of the file. 0 for PDF files, 1 for image files. If this attribute is missing, the file type will be inferred from the URL. |
No |
useDocOrientationClassify |
boolean | null |
Refer to the use_doc_orientation_classify parameter description in the pipeline predict method. |
No |
useDocUnwarping |
boolean | null |
Refer to the use_doc_unwarping parameter description in the pipeline predict method. |
No |
useTextlineOrientation |
boolean | null |
Refer to the use_textline_orientation parameter description in the pipeline predict method. |
No |
textDetLimitSideLen |
integer | null |
Refer to the text_det_limit_side_len parameter description in the pipeline predict method. |
No |
textDetLimitType |
string | null |
Refer to the text_det_limit_type parameter description in the pipeline predict method. |
No |
textDetThresh |
number | null |
Refer to the text_det_thresh parameter description in the pipeline predict method. |
No |
textDetBoxThresh |
number | null |
Refer to the text_det_box_thresh parameter description in the pipeline predict method. |
No |
textDetUnclipRatio |
number | null |
Refer to the text_det_unclip_ratio parameter description in the pipeline predict method. |
No |
textRecScoreThresh |
number | null |
Refer to the text_rec_score_thresh parameter description in the pipeline predict method. |
No |
result:| Name | Type | Description |
|---|---|---|
ocrResults |
object |
OCR results. The array length is 1 (for image input) or the smaller of the document page count and 10 (for PDF input). For PDF input, each element in the array represents the processing result for each page of the PDF file. |
dataInfo |
object |
Information about the input data. |
Each element in ocrResults is an object with the following properties:
| Name | Type | Description |
|---|---|---|
prunedResult |
object |
The simplified version of the res field in the JSON representation generated by the predict method of the production object, with the input_path field removed. |
ocrImage |
string | null |
The OCR result image, which marks the detected text positions. The image is in JPEG format and encoded in Base64. |
docPreprocessingImage |
string | null |
The visualization result image. The image is in JPEG format and encoded in Base64. |
inputImage |
string | null |
The input image. The image is in JPEG format and encoded in Base64. |
import base64
import requests
API_URL = "http://localhost:8080/ocr"
file_path = "./demo.jpg"
with open(file_path, "rb") as file:
file_bytes = file.read()
file_data = base64.b64encode(file_bytes).decode("ascii")
payload = {"file": file_data, "fileType": 1}
response = requests.post(API_URL, json=payload)
assert response.status_code == 200
result = response.json()["result"]
for i, res in enumerate(result["ocrResults"]):
print(res["prunedResult"])
ocr_img_path = f"ocr_{i}.jpg"
with open(ocr_img_path, "wb") as f:
f.write(base64.b64decode(res["ocrImage"]))
print(f"Output image saved at {ocr_img_path}")
| Scenario | Fine-Tuning Module | Fine-Tuning Reference Link |
|---|---|---|
| Text is missed in detection | Text Detection Module | Link |
| Text content is inaccurate | Text Recognition Module | Link |
| Vertical or rotated text line correction is inaccurate | Text Line Orientation Classification Module | Link |
| Whole-image rotation correction is inaccurate | Document Image Orientation Classification Module | Link |
| Image distortion correction is inaccurate | Text Image Correction Module | Fine-tuning not supported yet |
{kind=link}