[简体中文](instance_segmentation.md) | English
# PaddleX Instance Segmentation Task Module Data Annotation Tutorial
This document will introduce how to use the [Labelme](https://github.com/wkentaro/labelme) annotation tool to complete data annotation for a single model related to instance segmentation. Click on the link above to install the data annotation tool and view detailed usage instructions by referring to the homepage documentation.
## 1. Annotation Data Example
This dataset is a fruit instance segmentation dataset, covering five different types of fruits, including photos taken from different angles of the targets. Image examples:
## 2. Labelme Annotation
### 2.1 Introduction to Labelme Annotation Tool
`Labelme` is a Python-based image annotation software with a graphical user interface. It can be used for tasks such as image classification, object detection, and image segmentation. For instance segmentation annotation tasks, labels are stored as `JSON` files.
### 2.2 Labelme Installation
To avoid environment conflicts, it is recommended to install in a `conda` environment.
```bash
conda create -n labelme python=3.10
conda activate labelme
pip install pyqt5
pip install labelme
```
### 2.3 Labelme Annotation Process
#### 2.3.1 Prepare Data for Annotation
* Create a root directory for the dataset, such as `fruit`.
* Create an `images` directory (must be named `images`) within `fruit` and store the images to be annotated in the `images` directory, as shown below:
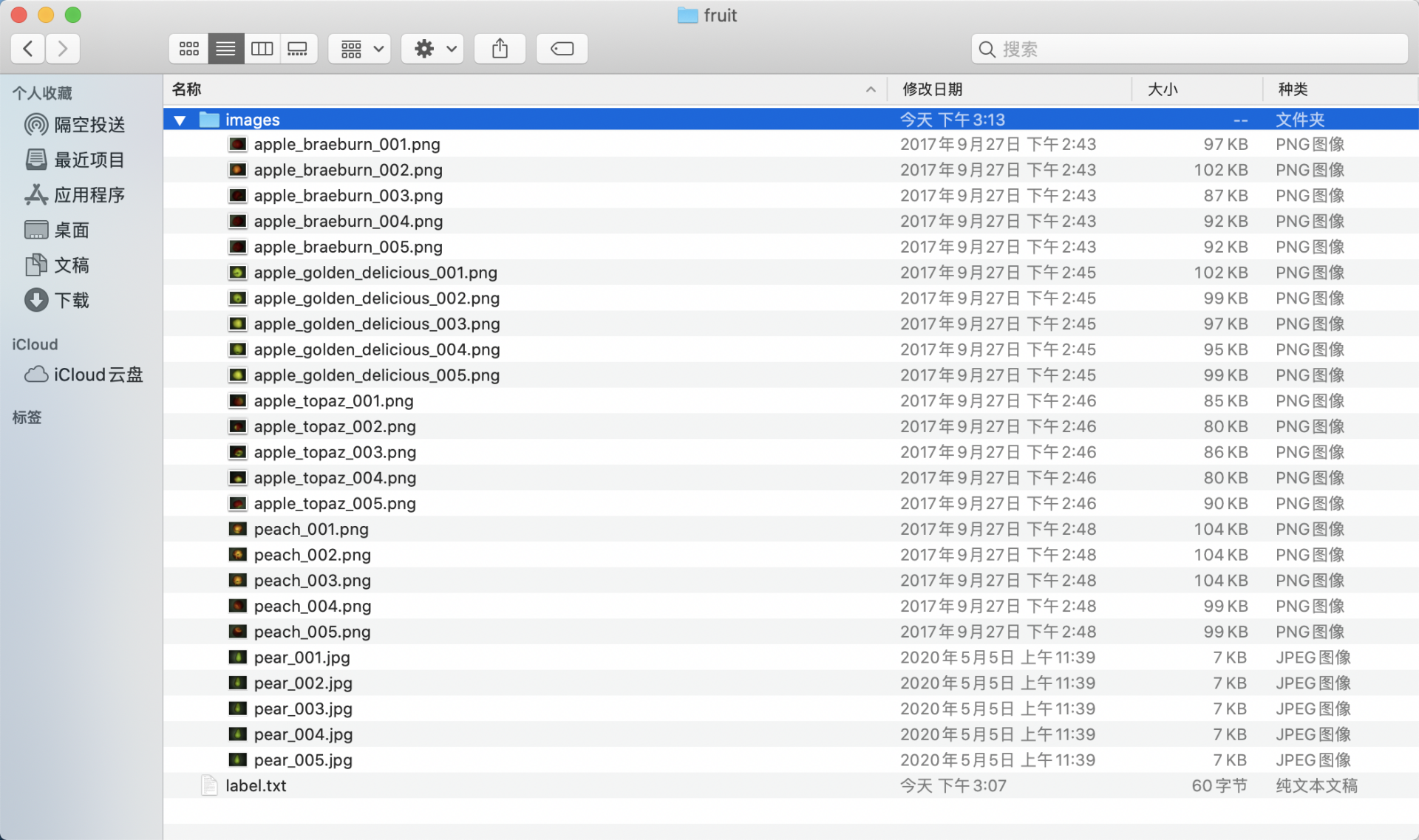
* Create a category label file `label.txt` in the `fruit` folder for the dataset to be annotated, and write the categories of the dataset to be annotated into `label.txt` by line. Taking the fruit instance segmentation dataset's `label.txt` as an example, as shown below:

#### 2.3.2 Start Labelme
Navigate to the root directory of the dataset to be annotated in the terminal and start the `labelme` annotation tool.
```bash
cd path/to/fruit
labelme images --labels label.txt --nodata --autosave --output annotations
```
* `labels` is the path to the category labels.
* `nodata` stops storing image data in the JSON file.
* `autosave` enables automatic saving.
* `output` specifies the path for storing label files.
#### 2.3.3 Begin Image Annotation
* After starting `labelme`, it will look like this:
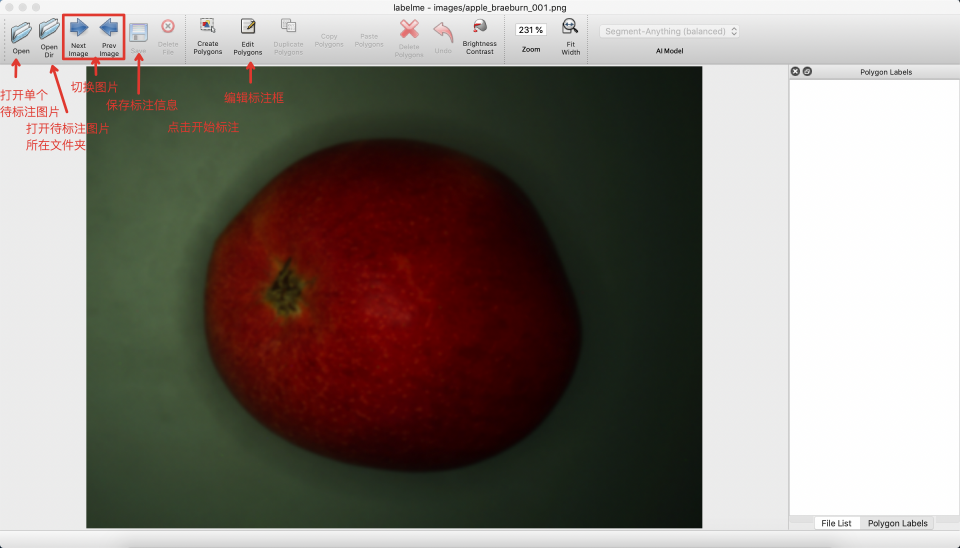
* Click `Edit` to select the annotation type, choose `Create Polygons`.
* Create polygons on the image to outline the boundaries of the segmentation areas.

* Click again to select the category of the segmentation area.
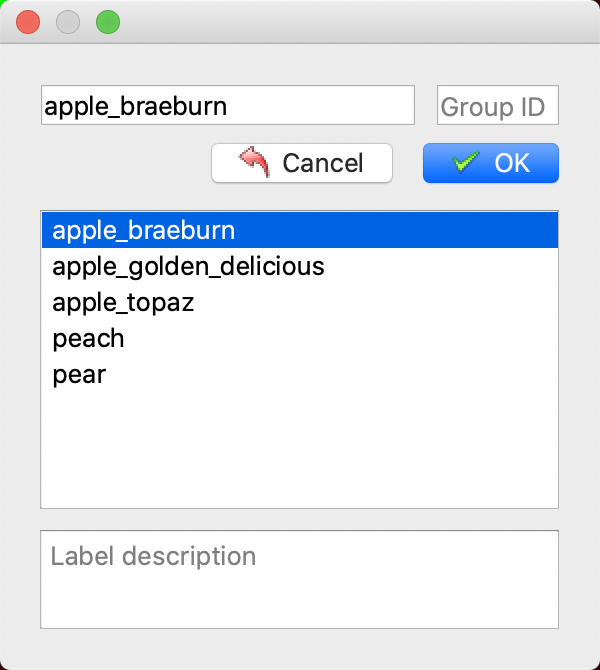
* After annotation, click Save. (If `output` is not specified when starting `labelme`, it will prompt to select a save path upon the first save. If `autosave` is specified, there is no need to click the Save button).
* Then click `Next Image` to annotate the next image.

* The final annotated label file will look like this.
* Adjusting Directory Structure to Obtain a Standard `labelme` Format Dataset for Fruit Instance Segmentation
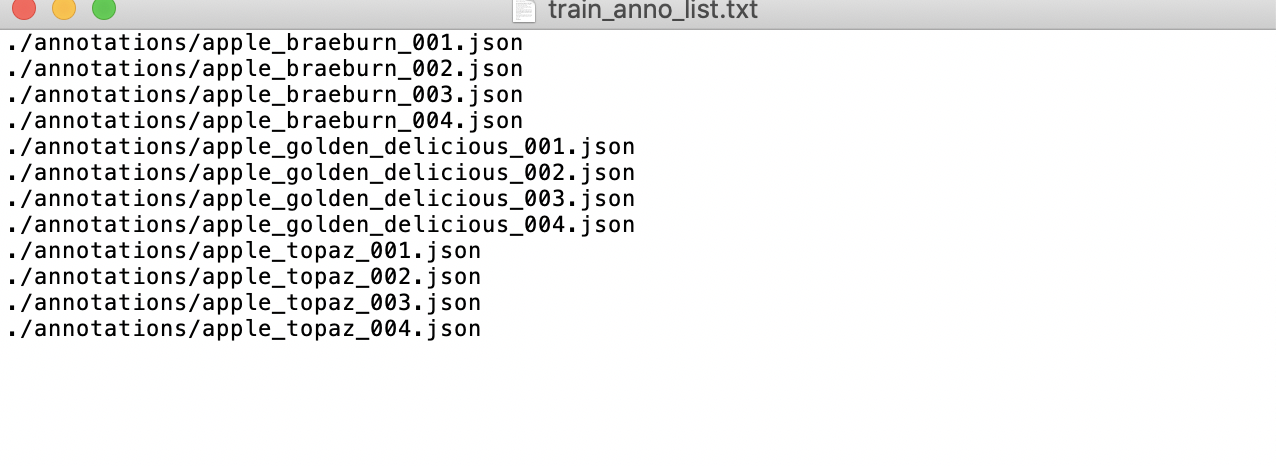
* Prepare the `train_anno_list.txt` and `val_anno_list.txt` text files in the root directory of your dataset. Populate these files with the paths of all `json` files in the `annotations` directory, distributing them into `train_anno_list.txt` and `val_anno_list.txt` at a specified ratio. Alternatively, you can include all paths in `train_anno_list.txt` and create an empty `val_anno_list.txt` file, intending to use a zero-code data splitting feature for re-partitioning upon upload. The specific format for filling `train_anno_list.txt` and `val_anno_list.txt` is illustrated as follows:
* The final directory structure after organization should resemble the following:
* Compress the `fruit` directory into a `.tar` or `.zip` format archive to obtain the standard `labelme` format dataset for fruit instance segmentation.
## 3. Data Format
PaddleX defines a dataset named **COCOInstSegDataset** for instance segmentation tasks, with the following organizational structure and annotation format:
```ruby
dataset_dir # Root directory of the dataset, the directory name can be changed
├── annotations # Directory for saving annotation files, the directory name cannot be changed
│ ├── instance_train.json # Training set annotation file, the file name cannot be changed, using COCO annotation format
│ └── instance_val.json # Validation set annotation file, the file name cannot be changed, using COCO annotation format
└── images # Directory for saving images, the directory name cannot be changed
```
Annotation files adopt the `COCO` format. Please refer to the above specifications for data preparation. Additionally, refer to: [Example Dataset](https://paddle-model-ecology.bj.bcebos.com/paddlex/data/instance_seg_coco_examples.tar).
When using PaddleX 2.x version for instance segmentation datasets, please refer to the corresponding format conversion section in [ Instance Segmentation Module Development Tutorial](../../module_usage/tutorials/cv_modules/instance_segmentation_en.md) to convert VOC format datasets to COCO datasets. (Note in module development documentation)
**Note**:
* Instance segmentation data requires the use of the `COCO` data format to annotate the pixel boundaries and categories of each target area in each image in the dataset. The polygon boundaries (segmentation) of objects are represented as `[x1,y1,x2,y2,...,xn,yn]`, where `(xn,yn)` denotes the coordinates of each corner point of the polygon. Annotation information is stored in `json` files under the `annotations` directory, with separate files for the training set (`instance_train.json`) and validation set (`instance_val.json`).
* If you have a batch of unlabeled data, we recommend using `LabelMe` for data annotation. PaddleX Pipelines support data format conversion for datasets annotated with `LabelMe`.
* To ensure successful format conversion, please strictly follow the file naming and organization of the example dataset: [LabelMe Example Dataset](https://paddle-model-ecology.bj.bcebos.com/paddlex/data/instance_seg_labelme_examples.tar).


