---
comments: true
---
# 公式识别模块使用教程
## 一、概述
公式识别模块是OCR(光学字符识别)系统中的关键组成部分,负责将图像中的数学公式转换为可编辑的文本或计算机可识别的格式。该模块的性能直接影响到整个OCR系统的准确性和效率。公式识别模块通常会输出数学公式的 LaTeX 或 MathML 代码,这些代码将作为输入传递给文本理解模块进行后续处理。
## 二、支持模型列表
| 模型 | 模型下载链接 |
Avg-BLEU(%) |
GPU推理耗时 (ms) |
模型存储大小 (M) |
介绍 |
UniMERNet | 推理模型/训练模型 |
86.13 |
2266.96 |
1.4 G |
UniMERNet是由上海AI Lab研发的一款公式识别模型。该模型采用Donut Swin作为编码器,MBartDecoder作为解码器,并通过在包含简单公式、复杂公式、扫描捕捉公式和手写公式在内的一百万数据集上进行训练,大幅提升了模型对真实场景公式的识别准确率 |
| PP-FormulaNet-S | 推理模型/训练模型 |
87.12 |
202.25 |
167.9 M |
PP-FormulaNet 是由百度飞桨视觉团队开发的一款先进的公式识别模型,支持5万个常见LateX源码词汇的识别。PP-FormulaNet-S 版本采用了 PP-HGNetV2-B4 作为其骨干网络,通过并行掩码和模型蒸馏等技术,大幅提升了模型的推理速度,同时保持了较高的识别精度,适用于简单印刷公式、跨行简单印刷公式等场景。而 PP-FormulaNet-L 版本则基于 Vary_VIT_B 作为骨干网络,并在大规模公式数据集上进行了深入训练,在复杂公式的识别方面,相较于PP-FormulaNet-S表现出显著的提升,适用于简单印刷公式、复杂印刷公式、手写公式等场景。 |
PP-FormulaNet-L | 推理模型/训练模型 |
92.13 |
1976.52 |
535.2 M |
| LaTeX_OCR_rec | 推理模型/训练模型 |
71.63 |
- |
89.7 M |
LaTeX-OCR是一种基于自回归大模型的公式识别算法,通过采用 Hybrid ViT 作为骨干网络,transformer作为解码器,显著提升了公式识别的准确性。 |
**测试环境说明:**
- **性能测试环境**
- **测试数据集**:PaddleX 内部自建公式识别测试集
- **硬件配置**:
- GPU:NVIDIA Tesla T4
- CPU:Intel Xeon Gold 6271C @ 2.60GHz
- 其他环境:Ubuntu 20.04 / cuDNN 8.6 / TensorRT 8.5.2.2
- **推理模式说明**
| 模式 | GPU配置 | CPU配置 | 加速技术组合 |
|-------------|----------------------------------|------------------|---------------------------------------------|
| 常规模式 | FP32精度 / 无TRT加速 | FP32精度 / 8线程 | PaddleInference |
| 高性能模式 | 选择先验精度类型和加速策略的最优组合 | FP32精度 / 8线程 | 选择先验最优后端(Paddle/OpenVINO/TRT等) |
## 三、快速集成
> ❗ 在快速集成前,请先安装 PaddleX 的 wheel 包,详细请参考 [PaddleX本地安装教程](../../../installation/installation.md)
wheel 包的安装后,几行代码即可完成公式识别模块的推理,可以任意切换该模块下的模型,您也可以将公式识别的模块中的模型推理集成到您的项目中。运行以下代码前,请您下载[示例图片](https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_formula_rec_001.png)到本地。
```python
from paddlex import create_model
model = create_model(model_name="PP-FormulaNet-S")
output = model.predict(input="general_formula_rec_001.png", batch_size=1)
for res in output:
res.print()
res.save_to_img(save_path="./output/")
res.save_to_json(save_path="./output/res.json")
```
运行后,得到的结果为:
```bash
{'res': {'input_path': 'general_formula_rec_001.png', 'page_index': None, 'rec_formula': '\\zeta_{0}(\\nu)=-{\\frac{\\nu\\varrho^{-2\\nu}}{\\pi}}\\int_{\\mu}^{\\infty}d\\omega\\int_{C_{+}}d z{\\frac{2z^{2}}{(z^{2}+\\omega^{2})^{\\nu+1}}}\\ \\ {vec\\Psi}(\\omega;z)e^{i\\epsilon z}\\quad,'}}
```
运行结果参数含义如下:
- `input_path`:表示输入待预测公式图像的路径
- `page_index`:如果输入是PDF文件,则表示当前是PDF的第几页,否则为 `None`
- `rec_formula`:表示公式图像的预测LaTeX源码
可视化图片如下,左侧是待预测的公式图像,右边是预测的结果渲染后的公式图像:
 注:如果您需要对公式识别产线进行可视化,需要运行如下命令来对LaTeX渲染环境进行安装。目前公式识别产线可视化只支持Ubuntu环境,其他环境暂不支持。对于复杂公式,LaTeX 结果可能包含部分高级的表示,Markdown等环境中未必可以成功显示:
```bash
sudo apt-get update
sudo apt-get install texlive texlive-latex-base texlive-latex-extra -y
```
相关方法、参数等说明如下:
* `create_model`实例化公式识别模型(此处以`PP-FormulaNet-S`为例),具体说明如下:
注:如果您需要对公式识别产线进行可视化,需要运行如下命令来对LaTeX渲染环境进行安装。目前公式识别产线可视化只支持Ubuntu环境,其他环境暂不支持。对于复杂公式,LaTeX 结果可能包含部分高级的表示,Markdown等环境中未必可以成功显示:
```bash
sudo apt-get update
sudo apt-get install texlive texlive-latex-base texlive-latex-extra -y
```
相关方法、参数等说明如下:
* `create_model`实例化公式识别模型(此处以`PP-FormulaNet-S`为例),具体说明如下:
| 参数 |
参数说明 |
参数类型 |
可选项 |
默认值 |
model_name |
模型名称 |
str |
所有PaddleX支持的模型名称 |
无 |
model_dir |
模型存储路径 |
str |
无 |
无 |
use_hpip |
是否启用高性能推理 |
bool |
无 |
False |
* 其中,`model_name` 必须指定,指定 `model_name` 后,默认使用 PaddleX 内置的模型参数,在此基础上,指定 `model_dir` 时,使用用户自定义的模型。
* 调用公式识别模型的 `predict()` 方法进行推理预测,`predict()` 方法参数有 `input` 和 `batch_size`,具体说明如下:
| 参数 |
参数说明 |
参数类型 |
可选项 |
默认值 |
input |
待预测数据,支持多种输入类型 |
Python Var/str/list |
- Python变量,如
numpy.ndarray表示的图像数据
- 文件路径,如图像文件的本地路径:
/root/data/img.jpg
- URL链接,如图像文件的网络URL:示例
- 本地目录,该目录下需包含待预测数据文件,如本地路径:
/root/data/
- 列表,列表元素需为上述类型数据,如
[numpy.ndarray, numpy.ndarray],[\"/root/data/img1.jpg\", \"/root/data/img2.jpg\"],[\"/root/data1\", \"/root/data2\"]
|
无 |
batch_size |
批大小 |
int |
任意整数 |
1 |
* 对预测结果进行处理,每个样本的预测结果均为对应的Result对象,且支持打印、保存为图片、保存为`json`文件的操作:
| 方法 |
方法说明 |
参数 |
参数类型 |
参数说明 |
默认值 |
print() |
打印结果到终端 |
format_json |
bool |
是否对输出内容进行使用 JSON 缩进格式化 |
True |
indent |
int |
指定缩进级别,以美化输出的 JSON 数据,使其更具可读性,仅当 format_json 为 True 时有效 |
4 |
ensure_ascii |
bool |
控制是否将非 ASCII 字符转义为 Unicode。设置为 True 时,所有非 ASCII 字符将被转义;False 则保留原始字符,仅当format_json为True时有效 |
False |
save_to_json() |
将结果保存为json格式的文件 |
save_path |
str |
保存的文件路径,当为目录时,保存文件命名与输入文件类型命名一致 |
无 |
indent |
int |
指定缩进级别,以美化输出的 JSON 数据,使其更具可读性,仅当 format_json 为 True 时有效 |
4 |
ensure_ascii |
bool |
控制是否将非 ASCII 字符转义为 Unicode。设置为 True 时,所有非 ASCII 字符将被转义;False 则保留原始字符,仅当format_json为True时有效 |
False |
save_to_img() |
将结果保存为图像格式的文件 |
save_path |
str |
保存的文件路径,当为目录时,保存文件命名与输入文件类型命名一致 |
无 |
* 此外,也支持通过属性获取带结果的可视化图像和预测结果,具体如下:
| 属性 |
属性说明 |
json |
获取预测的json格式的结果 |
img |
获取格式为dict的可视化图像 |
关于更多 PaddleX 的单模型推理的 API 的使用方法,可以参考的使用方法,可以参考[PaddleX单模型Python脚本使用说明](../../instructions/model_python_API.md)。
## 四、二次开发
如果你追求更高精度的现有模型,可以使用 PaddleX 的二次开发能力,开发更好的公式识别模型。在使用 PaddleX 开发公式识别模型之前,请务必安装 PaddleX 的 PaddleOCR 相关模型训练插件,安装过程可以参考 [PaddleX本地安装教程](../../../installation/installation.md)
### 4.1 数据准备
在进行模型训练前,需要准备相应任务模块的数据集。PaddleX 针对每一个模块提供了数据校验功能,只有通过数据校验的数据才可以进行模型训练。此外,PaddleX 为每一个模块都提供了 Demo 数据集,您可以基于官方提供的 Demo 数据完成后续的开发。若您希望用私有数据集进行后续的模型训练,可以参考[LaTeX-OCR 公式识别项目](https://github.com/lukas-blecher/LaTeX-OCR)
#### 4.1.1 Demo 数据下载
您可以参考下面的命令将 Demo 数据集下载到指定文件夹:
```bash
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/ocr_rec_latexocr_dataset_example.tar -P ./dataset
tar -xf ./dataset/ocr_rec_latexocr_dataset_example.tar -C ./dataset/
```
#### 4.1.2 数据校验
一行命令即可完成数据校验:
```bash
python main.py -c paddlex/configs/modules/formula_recognition/PP-FormulaNet-S.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/ocr_rec_latexocr_dataset_example
```
执行上述命令后,PaddleX 会对数据集进行校验,并统计数据集的基本信息,命令运行成功后会在 log 中打印出`Check dataset passed !`信息。校验结果文件保存在`./output/check_dataset_result.json`,同时相关产出会保存在当前目录的`./output/check_dataset`目录下,产出目录中包括可视化的示例样本图片和样本分布直方图。
👉 校验结果详情(点击展开)
校验结果文件具体内容为:
{
"done_flag": true,
"check_pass": true,
"attributes": {
"train_samples": 10001,
"train_sample_paths": [
"..\/dataset\/ocr_rec_latexocr_dataset_example\/images\/train_0077809.png",
"..\/dataset\/ocr_rec_latexocr_dataset_example\/images\/train_0161600.png",
"..\/dataset\/ocr_rec_latexocr_dataset_example\/images\/train_0002077.png",
"..\/dataset\/ocr_rec_latexocr_dataset_example\/images\/train_0178425.png",
"..\/dataset\/ocr_rec_latexocr_dataset_example\/images\/train_0010959.png",
"..\/dataset\/ocr_rec_latexocr_dataset_example\/images\/train_0079266.png",
"..\/dataset\/ocr_rec_latexocr_dataset_example\/images\/train_0142495.png",
"..\/dataset\/ocr_rec_latexocr_dataset_example\/images\/train_0196376.png",
"..\/dataset\/ocr_rec_latexocr_dataset_example\/images\/train_0185513.png",
"..\/dataset\/ocr_rec_latexocr_dataset_example\/images\/train_0217146.png"
],
"val_samples": 501,
"val_sample_paths": [
"..\/dataset\/ocr_rec_latexocr_dataset_example\/images\/val_0053264.png",
"..\/dataset\/ocr_rec_latexocr_dataset_example\/images\/val_0100521.png",
"..\/dataset\/ocr_rec_latexocr_dataset_example\/images\/val_0146333.png",
"..\/dataset\/ocr_rec_latexocr_dataset_example\/images\/val_0072788.png",
"..\/dataset\/ocr_rec_latexocr_dataset_example\/images\/val_0002022.png",
"..\/dataset\/ocr_rec_latexocr_dataset_example\/images\/val_0203664.png",
"..\/dataset\/ocr_rec_latexocr_dataset_example\/images\/val_0082217.png",
"..\/dataset\/ocr_rec_latexocr_dataset_example\/images\/val_0208199.png",
"..\/dataset\/ocr_rec_latexocr_dataset_example\/images\/val_0111236.png",
"..\/dataset\/ocr_rec_latexocr_dataset_example\/images\/val_0204453.png"
]
},
"analysis": {
"histogram": "check_dataset\/histogram.png"
},
"dataset_path": "ocr_rec_latexocr_dataset_example",
"show_type": "image",
"dataset_type": "FormulaRecDataset"
}
上述校验结果中,check_pass 为 True 表示数据集格式符合要求,其他部分指标的说明如下:
attributes.train_samples:该数据集训练集样本数量为 9452;attributes.val_samples:该数据集验证集样本数量为 1050;attributes.train_sample_paths:该数据集训练集样本可视化图片相对路径列表;attributes.val_sample_paths:该数据集验证集样本可视化图片相对路径列表;
另外,数据集校验还对数据集中所有类别的样本数量分布情况进行了分析,并绘制了分布直方图(histogram.png):
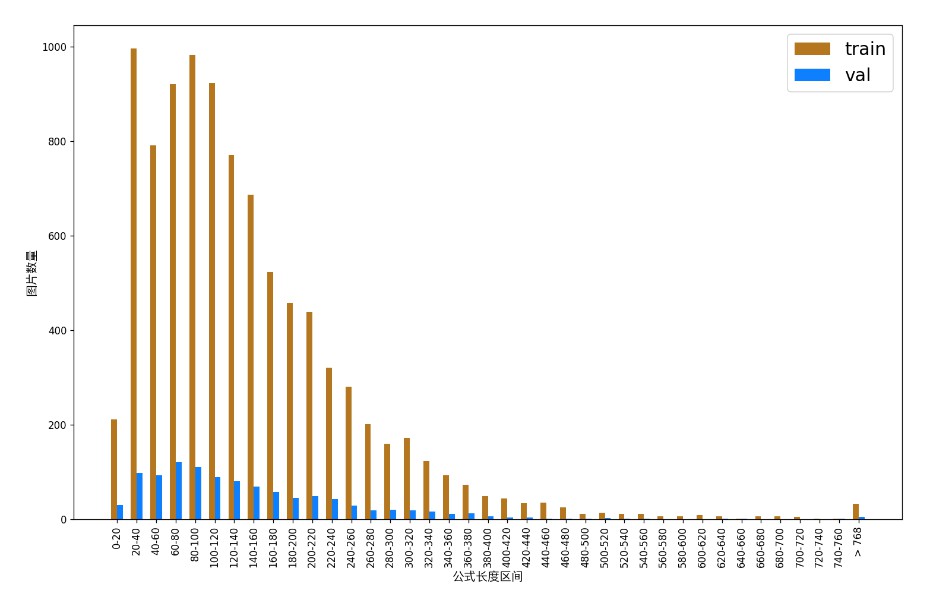
👉 格式转换/数据集划分详情(点击展开)
(1)数据集格式转换
公式识别支持 FormulaRecDataset格式的数据集转换为 LaTeXOCRDataset格式(PKL格式),数据集格式转换的参数可以通过修改配置文件中 CheckDataset 下的字段进行设置,配置文件中部分参数的示例说明如下:
CheckDataset:convert:enable: 是否进行数据集格式转换,公式识别支持 FormulaRecDataset格式的数据集转换为 LaTeXOCRDataset格式,默认为 True;src_dataset_type: 如果进行数据集格式转换,则需设置源数据集格式,默认为 FormulaRecDataset;
例如,您想将 FormulaRecDataset格式的数据集转换为 LaTeXOCRDataset格式,则需将配置文件修改为:
......
CheckDataset:
......
convert:
enable: True
src_dataset_type: FormulaRecDataset
......
随后执行命令:
python main.py -c paddlex/configs/modules/formula_recognition/PP-FormulaNet-S.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/ocr_rec_latexocr_dataset_example
数据转换执行之后,原有标注文件会被在原路径下重命名为 xxx.bak。
以上参数同样支持通过追加命令行参数的方式进行设置:
python main.py -c paddlex/configs/modules/formula_recognition/PP-FormulaNet-S.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/ocr_rec_latexocr_dataset_example \
-o CheckDataset.convert.enable=True \
-o CheckDataset.convert.src_dataset_type=FormulaRecDataset
(2)数据集划分
数据集划分的参数可以通过修改配置文件中 CheckDataset 下的字段进行设置,配置文件中部分参数的示例说明如下:
CheckDataset:split:enable: 是否进行重新划分数据集,为 True 时进行数据集格式转换,默认为 False;train_percent: 如果重新划分数据集,则需要设置训练集的百分比,类型为 0-100 之间的任意整数,需要保证和 val_percent 值加和为100;
例如,您想重新划分数据集为 训练集占比90%、验证集占比10%,则需将配置文件修改为:
......
CheckDataset:
......
split:
enable: True
train_percent: 90
val_percent: 10
......
随后执行命令:
python main.py -c paddlex/configs/modules/formula_recognition/PP-FormulaNet-S.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/ocr_rec_latexocr_dataset_example
数据划分执行之后,原有标注文件会被在原路径下重命名为 xxx.bak。
以上参数同样支持通过追加命令行参数的方式进行设置:
python main.py -c paddlex/configs/modules/formula_recognition/PP-FormulaNet-S.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/ocr_rec_latexocr_dataset_example \
-o CheckDataset.split.enable=True \
-o CheckDataset.split.train_percent=90 \
-o CheckDataset.split.val_percent=10
👉 更多说明(点击展开)
👉 更多说明(点击展开)
在模型评估时,需要指定模型权重文件路径,每个配置文件中都内置了默认的权重保存路径,如需要改变,只需要通过追加命令行参数的形式进行设置即可,如-o Evaluate.weight_path=./output/best_accuracy/best_accuracy.pdparams。
在完成模型评估后,会产出evaluate_result.json,其记录了评估的结果,具体来说,记录了评估任务是否正常完成,以及模型的评估指标,包括 exp_rate ;
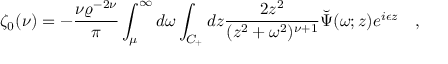{kind=link}