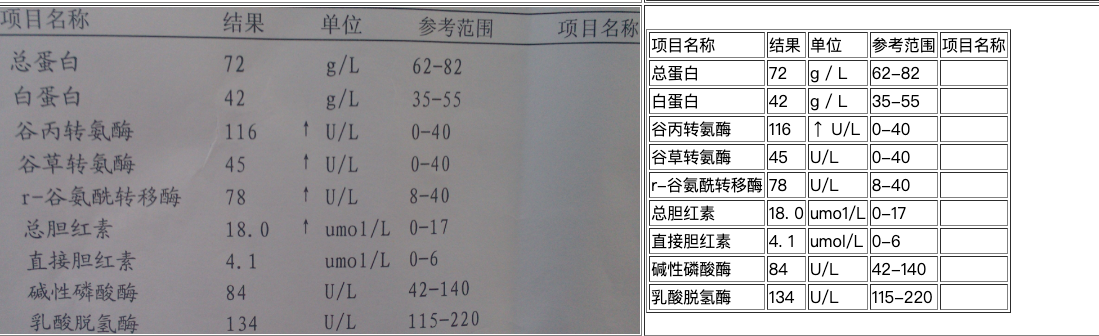
 通用表格识别产线中包含表格结构识别模块、版面区域分析模块、文本检测模块和文本识别模块。
如您更考虑模型精度,请选择精度较高的模型,如您更考虑模型推理速度,请选择推理速度较快的模型,如您更考虑模型存储大小,请选择存储大小较小的模型。
通用表格识别产线中包含表格结构识别模块、版面区域分析模块、文本检测模块和文本识别模块。
如您更考虑模型精度,请选择精度较高的模型,如您更考虑模型推理速度,请选择推理速度较快的模型,如您更考虑模型存储大小,请选择存储大小较小的模型。
表格识别模块模型:
| 模型 | 模型下载链接 | 精度(%) | GPU推理耗时 (ms) | CPU推理耗时(ms) | 模型存储大小 (M) | 介绍 |
|---|---|---|---|---|---|---|
| SLANet | 推理模型/训练模型 | 59.52 | 522.536 | 1845.37 | 6.9 M | SLANet 是百度飞桨视觉团队自研的表格结构识别模型。该模型通过采用CPU 友好型轻量级骨干网络PP-LCNet、高低层特征融合模块CSP-PAN、结构与位置信息对齐的特征解码模块SLA Head,大幅提升了表格结构识别的精度和推理速度。 |
| SLANet_plus | 推理模型/训练模型 | 63.69 | 522.536 | 1845.37 | 6.9 M |
注:以上精度指标测量PaddleX 内部自建英文表格识别数据集。所有模型 GPU 推理耗时基于 NVIDIA Tesla T4 机器,精度类型为 FP32, CPU 推理速度基于 Intel(R) Xeon(R) Gold 5117 CPU @ 2.00GHz,线程数为8,精度类型为 FP32。
版面区域分析模块模型:
| 模型 | 模型下载链接 | mAP(0.5)(%) | GPU推理耗时(ms) | CPU推理耗时 (ms) | 模型存储大小(M) | 介绍 |
|---|---|---|---|---|---|---|
| PicoDet_layout_1x | 推理模型/训练模型 | 86.8 | 13.0 | 91.3 | 7.4 | 基于PicoDet-1x在PubLayNet数据集训练的高效率版面区域定位模型,可定位包含文字、标题、表格、图片以及列表这5类区域 |
| PicoDet_layout_1x_table | 推理模型/训练模型 | 95.7 | 12.623 | 90.8934 | 7.4 M | 基于PicoDet-1x在自建数据集训练的高效率版面区域定位模型,可定位包含表格这1类区域 |
| PicoDet-S_layout_3cls | 推理模型/训练模型 | 87.1 | 13.5 | 45.8 | 4.8 | 基于PicoDet-S轻量模型在中英文论文、杂志和研报等场景上自建数据集训练的高效率版面区域定位模型,包含3个类别:表格,图像和印章 |
| PicoDet-S_layout_17cls | 推理模型/训练模型 | 70.3 | 13.6 | 46.2 | 4.8 | 基于PicoDet-S轻量模型在中英文论文、杂志和研报等场景上自建数据集训练的高效率版面区域定位模型,包含17个版面常见类别,分别是:段落标题、图片、文本、数字、摘要、内容、图表标题、公式、表格、表格标题、参考文献、文档标题、脚注、页眉、算法、页脚、印章 |
| PicoDet-L_layout_3cls | 推理模型/训练模型 | 89.3 | 15.7 | 159.8 | 22.6 | 基于PicoDet-L在中英文论文、杂志和研报等场景上自建数据集训练的高效率版面区域定位模型,包含3个类别:表格,图像和印章 |
| PicoDet-L_layout_17cls | 推理模型/训练模型 | 79.9 | 17.2 | 160.2 | 22.6 | 基于PicoDet-L在中英文论文、杂志和研报等场景上自建数据集训练的高效率版面区域定位模型,包含17个版面常见类别,分别是:段落标题、图片、文本、数字、摘要、内容、图表标题、公式、表格、表格标题、参考文献、文档标题、脚注、页眉、算法、页脚、印章 |
| RT-DETR-H_layout_3cls | 推理模型/训练模型 | 95.9 | 114.6 | 3832.6 | 470.1 | 基于RT-DETR-H在中英文论文、杂志和研报等场景上自建数据集训练的高精度版面区域定位模型,包含3个类别:表格,图像和印章 |
| RT-DETR-H_layout_17cls | 推理模型/训练模型 | 92.6 | 115.1 | 3827.2 | 470.2 | 基于RT-DETR-H在中英文论文、杂志和研报等场景上自建数据集训练的高精度版面区域定位模型,包含17个版面常见类别,分别是:段落标题、图片、文本、数字、摘要、内容、图表标题、公式、表格、表格标题、参考文献、文档标题、脚注、页眉、算法、页脚、印章 |
注:以上精度指标的评估集是 PaddleX 自建的版面区域分析数据集,包含 1w 张图片。以上所有模型 GPU 推理耗时基于 NVIDIA Tesla T4 机器,精度类型为 FP32, CPU 推理速度基于 Intel(R) Xeon(R) Gold 5117 CPU @ 2.00GHz,线程数为8,精度类型为 FP32。
文本检测模块模型:
| 模型 | 模型下载链接 | 检测Hmean(%) | GPU推理耗时(ms) | CPU推理耗时(ms) | 模型存储大小(M) |
|---|---|---|---|---|---|
| PP-OCRv4_mobile_det | 推理模型/训练模型 | 77.79 | 10.6923 | 120.177 | 4.2 M |
| PP-OCRv4_server_det | 推理模型/训练模型 | 82.69 | 83.3501 | 2434.01 | 100.1M |
注:以上精度指标的评估集是 PaddleOCR 自建的中文数据集,覆盖街景、网图、文档、手写多个场景,其中检测包含 500 张图片。以上所有模型 GPU 推理耗时基于 NVIDIA Tesla T4 机器,精度类型为 FP32, CPU 推理速度基于 Intel(R) Xeon(R) Gold 5117 CPU @ 2.00GHz,线程数为8,精度类型为 FP32。
文本识别模块模型:
| 模型 | 模型下载链接 | 识别Avg Accuracy(%) | GPU推理耗时(ms) | CPU推理耗时(ms) | 模型存储大小(M) |
|---|---|---|---|---|---|
| PP-OCRv4_mobile_rec | 推理模型/训练模型 | 78.20 | 7.95018 | 46.7868 | 10.6 M |
| PP-OCRv4_server_rec | 推理模型/训练模型 | 79.20 | 7.19439 | 140.179 | 71.2 M |
注:以上精度指标的评估集是 PaddleOCR 自建的中文数据集 ,覆盖街景、网图、文档、手写多个场景,其中文本识别包含 1.1w 张图片。以上所有模型 GPU 推理耗时基于 NVIDIA Tesla T4 机器,精度类型为 FP32, CPU 推理速度基于 Intel(R) Xeon(R) Gold 5117 CPU @ 2.00GHz,线程数为8,精度类型为 FP32。
 如果您对产线运行的效果满意,可以直接对产线进行集成部署,如果不满意,您也可以利用私有数据对产线中的模型进行在线微调。
### 2.2 本地体验
在本地使用通用表格识别产线前,请确保您已经按照[PaddleX本地安装教程](../../../installation/installation.md)完成了PaddleX的wheel包安装。
### 2.1 命令行方式体验
一行命令即可快速体验表格识别产线效果,使用 [测试文件](https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/table_recognition.jpg),并将 `--input` 替换为本地路径,进行预测
```bash
paddlex --pipeline table_recognition --input table_recognition.jpg --device gpu:0
```
参数说明:
```
--pipeline:产线名称,此处为表格识别产线
--input:待处理的输入图片的本地路径或URL
--device 使用的GPU序号(例如gpu:0表示使用第0块GPU,gpu:1,2表示使用第1、2块GPU),也可选择使用CPU(--device cpu)
```
在执行上述 Python 脚本时,加载的是默认的表格识别产线配置文件,若您需要自定义配置文件,可执行如下命令获取:
如果您对产线运行的效果满意,可以直接对产线进行集成部署,如果不满意,您也可以利用私有数据对产线中的模型进行在线微调。
### 2.2 本地体验
在本地使用通用表格识别产线前,请确保您已经按照[PaddleX本地安装教程](../../../installation/installation.md)完成了PaddleX的wheel包安装。
### 2.1 命令行方式体验
一行命令即可快速体验表格识别产线效果,使用 [测试文件](https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/table_recognition.jpg),并将 `--input` 替换为本地路径,进行预测
```bash
paddlex --pipeline table_recognition --input table_recognition.jpg --device gpu:0
```
参数说明:
```
--pipeline:产线名称,此处为表格识别产线
--input:待处理的输入图片的本地路径或URL
--device 使用的GPU序号(例如gpu:0表示使用第0块GPU,gpu:1,2表示使用第1、2块GPU),也可选择使用CPU(--device cpu)
```
在执行上述 Python 脚本时,加载的是默认的表格识别产线配置文件,若您需要自定义配置文件,可执行如下命令获取:
paddlex --get_pipeline_config table_recognition
执行后,表格识别产线配置文件将被保存在当前路径。若您希望自定义保存位置,可执行如下命令(假设自定义保存位置为 ./my_path ):
paddlex --get_pipeline_config table_recognition --save_path ./my_path
获取产线配置文件后,可将 --pipeline 替换为配置文件保存路径,即可使配置文件生效。例如,若配置文件保存路径为 ./table_recognition.yaml,只需执行:
paddlex --pipeline ./table_recognition.yaml --input table_recognition.jpg --device gpu:0
其中,--model、--device 等参数无需指定,将使用配置文件中的参数。若依然指定了参数,将以指定的参数为准。
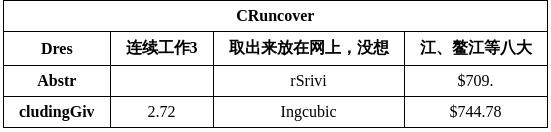
{'input_path': 'table_recognition.jpg', 'layout_result': {'input_path': 'table_recognition.jpg', 'boxes': [{'cls_id': 3, 'label': 'Table', 'score': 0.6014542579650879, 'coordinate': [0, 21, 551, 118]}]}, 'ocr_result': {'dt_polys': [array([[37., 40.],
[75., 40.],
[75., 60.],
[37., 60.]], dtype=float32), array([[123., 37.],
[200., 37.],
[200., 59.],
[123., 59.]], dtype=float32), array([[227., 37.],
[391., 37.],
[391., 58.],
[227., 58.]], dtype=float32), array([[416., 36.],
[535., 38.],
[535., 61.],
[415., 58.]], dtype=float32), array([[35., 73.],
[78., 73.],
[78., 92.],
[35., 92.]], dtype=float32), array([[287., 73.],
[328., 73.],
[328., 92.],
[287., 92.]], dtype=float32), array([[453., 72.],
[495., 72.],
[495., 94.],
[453., 94.]], dtype=float32), array([[ 17., 103.],
[ 94., 103.],
[ 94., 118.],
[ 17., 118.]], dtype=float32), array([[145., 104.],
[178., 104.],
[178., 118.],
[145., 118.]], dtype=float32), array([[277., 104.],
[337., 102.],
[338., 118.],
[278., 118.]], dtype=float32), array([[446., 102.],
[504., 104.],
[503., 118.],
[445., 118.]], dtype=float32)], 'rec_text': ['Dres', '连续工作3', '取出来放在网上,没想', '江、整江等八大', 'Abstr', 'rSrivi', '$709.', 'cludingGiv', '2.72', 'Ingcubic', '$744.78'], 'rec_score': [0.9934158325195312, 0.9990204572677612, 0.9967061877250671, 0.9375461935997009, 0.9947397112846375, 0.9972746968269348, 0.9904290437698364, 0.973427414894104, 0.9983080625534058, 0.993423342704773, 0.9964120984077454], 'input_path': 'table_recognition.jpg'}, 'table_result': [{'input_path': 'table_recognition.jpg', 'layout_bbox': [0, 21, 551, 118], 'bbox': array([[ 4.395736 , 25.238262 , 113.31014 , 25.316246 , 115.454315 ,
71.8867 , 3.7177477, 71.7937 ],
[110.727455 , 25.94007 , 210.07187 , 26.028755 , 209.66394 ,
65.96484 , 109.59861 , 66.09809 ],
[214.45381 , 26.027939 , 407.95276 , 26.112846 , 409.6684 ,
66.91336 , 215.27292 , 67.002014 ],
[402.81863 , 26.123789 , 549.03656 , 26.231564 , 549.19995 ,
66.88339 , 404.48068 , 66.74034 ],
[ 2.4458022, 64.68588 , 102.7665 , 65.10228 , 105.79447 ,
96.051254 , 2.5367072, 95.35514 ],
[108.85877 , 65.80549 , 211.70216 , 66.02091 , 210.79245 ,
94.75581 , 107.59308 , 94.42664 ],
[217.05621 , 64.98496 , 407.76328 , 65.133484 , 406.8436 ,
96.00133 , 214.67896 , 95.87226 ],
[401.73572 , 64.60494 , 547.9967 , 64.73921 , 548.19135 ,
96.09901 , 402.26733 , 95.95529 ],
[ 2.4882016, 93.589554 , 107.01325 , 93.67592 , 107.8446 ,
120.13259 , 2.508764 , 119.85027 ],
[110.773125 , 93.98633 , 213.354 , 94.08046 , 212.46033 ,
120.80207 , 109.29008 , 120.613045 ],
[216.08781 , 94.19984 , 405.843 , 94.28341 , 405.9974 ,
121.33152 , 215.10301 , 121.299034 ],
[403.92212 , 94.44883 , 548.30963 , 94.54982 , 548.4949 ,
122.610176 , 404.53433 , 122.49881 ]], dtype=float32), 'img_idx': 0, 'html': '<html><body><table><tr><td>Dres</td><td>连续工作3</td><td>取出来放在网上,没想</td><td>江、整江等八大</td></tr><tr><td>Abstr</td><td></td><td>rSrivi</td><td>$709.</td></tr><tr><td>cludingGiv</td><td>2.72</td><td>Ingcubic</td><td>$744.78</td></tr></table></body></html>'}]}
 可视化图片默认不进行保存,您可以通过 `--save_path` 自定义保存路径,随后所有结果将被保存在指定路径下。
### 2.2 Python脚本方式集成
几行代码即可完成产线的快速推理,以通用表格识别产线为例:
```python
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="table_recognition")
output = pipeline.predict("table_recognition.jpg")
for res in output:
res.print() ## 打印预测的结构化输出
res.save_to_img("./output/") ## 保存img格式结果
res.save_to_xlsx("./output/") ## 保存表格格式结果
res.save_to_html("./output/") ## 保存html结果
```
得到的结果与命令行方式相同。
在上述 Python 脚本中,执行了如下几个步骤:
(1)实例化 `create_pipeline` 实例化产线对象:具体参数说明如下:
可视化图片默认不进行保存,您可以通过 `--save_path` 自定义保存路径,随后所有结果将被保存在指定路径下。
### 2.2 Python脚本方式集成
几行代码即可完成产线的快速推理,以通用表格识别产线为例:
```python
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="table_recognition")
output = pipeline.predict("table_recognition.jpg")
for res in output:
res.print() ## 打印预测的结构化输出
res.save_to_img("./output/") ## 保存img格式结果
res.save_to_xlsx("./output/") ## 保存表格格式结果
res.save_to_html("./output/") ## 保存html结果
```
得到的结果与命令行方式相同。
在上述 Python 脚本中,执行了如下几个步骤:
(1)实例化 `create_pipeline` 实例化产线对象:具体参数说明如下:
| 参数 | 参数说明 | 参数类型 | 默认值 |
|---|---|---|---|
pipeline |
产线名称或是产线配置文件路径。如为产线名称,则必须为 PaddleX 所支持的产线。 | str |
无 |
device |
产线模型推理设备。支持:“gpu”,“cpu”。 | str |
gpu |
use_hpip |
是否启用高性能推理,仅当该产线支持高性能推理时可用。 | bool |
False |
| 参数类型 | 参数说明 |
|---|---|
| Python Var | 支持直接传入Python变量,如numpy.ndarray表示的图像数据。 |
| str | 支持传入待预测数据文件路径,如图像文件的本地路径:/root/data/img.jpg。 |
| str | 支持传入待预测数据文件URL,如图像文件的网络URL:示例。 |
| str | 支持传入本地目录,该目录下需包含待预测数据文件,如本地路径:/root/data/。 |
| dict | 支持传入字典类型,字典的key需与具体任务对应,如图像分类任务对应\"img\",字典的val支持上述类型数据,例如:{\"img\": \"/root/data1\"}。 |
| list | 支持传入列表,列表元素需为上述类型数据,如[numpy.ndarray, numpy.ndarray],[\"/root/data/img1.jpg\", \"/root/data/img2.jpg\"],[\"/root/data1\", \"/root/data2\"],[{\"img\": \"/root/data1\"}, {\"img\": \"/root/data2/img.jpg\"}]。 |
| 方法 | 说明 | 方法参数 |
|---|---|---|
| save_to_img | 将结果保存为img格式的文件 | - save_path:str类型,保存的文件路径,当为目录时,保存文件命名与输入文件类型命名一致; |
| save_to_html | 将结果保存为html格式的文件 | - save_path:str类型,保存的文件路径,当为目录时,保存文件命名与输入文件类型命名一致; |
| save_to_xlsx | 将结果保存为表格格式的文件 | - save_path:str类型,保存的文件路径,当为目录时,保存文件命名与输入文件类型命名一致; |
对于服务提供的主要操作:
200,响应体的属性如下:| 名称 | 类型 | 含义 |
|---|---|---|
logId |
string |
请求的UUID。 |
errorCode |
integer |
错误码。固定为0。 |
errorMsg |
string |
错误说明。固定为"Success"。 |
result |
object |
操作结果。 |
| 名称 | 类型 | 含义 |
|---|---|---|
logId |
string |
请求的UUID。 |
errorCode |
integer |
错误码。与响应状态码相同。 |
errorMsg |
string |
错误说明。 |
服务提供的主要操作如下:
infer定位并识别图中的表格。
POST /table-recognition
| 名称 | 类型 | 含义 | 是否必填 |
|---|---|---|---|
file |
string |
服务器可访问的图像文件或PDF文件的URL,或上述类型文件内容的Base64编码结果。对于超过10页的PDF文件,只有前10页的内容会被使用。 | 是 |
fileType |
integer |
文件类型。0表示PDF文件,1表示图像文件。若请求体无此属性,则将根据URL推断文件类型。 |
否 |
result具有如下属性:| 名称 | 类型 | 含义 |
|---|---|---|
tableRecResults |
object |
表格识别结果。数组长度为1(对于图像输入)或文档页数与10中的较小者(对于PDF输入)。对于PDF输入,数组中的每个元素依次表示PDF文件中每一页的处理结果。 |
dataInfo |
object |
输入数据信息。 |
tableRecResults中的每个元素为一个object,具有如下属性:
| 名称 | 类型 | 含义 |
|---|---|---|
tables |
array |
表格位置和内容。 |
layoutImage |
string |
版面区域检测结果图。图像为JPEG格式,使用Base64编码。 |
ocrImage |
string |
OCR结果图。图像为JPEG格式,使用Base64编码。 |
tables中的每个元素为一个object,具有如下属性:
| 名称 | 类型 | 含义 |
|---|---|---|
bbox |
array |
表格位置。数组中元素依次为边界框左上角x坐标、左上角y坐标、右下角x坐标以及右下角y坐标。 |
html |
string |
HTML格式的表格识别结果。 |
import base64
import requests
API_URL = "http://localhost:8080/table-recognition"
file_path = "./demo.jpg"
with open(file_path, "rb") as file:
file_bytes = file.read()
file_data = base64.b64encode(file_bytes).decode("ascii")
payload = {"file": file_data, "fileType": 1}
response = requests.post(API_URL, json=payload)
assert response.status_code == 200
result = response.json()["result"]
for i, res in enumerate(result["tableRecResults"]):
print("Detected tables:")
print(res["tables"])
layout_img_path = f"layout_{i}.jpg"
with open(layout_img_path, "wb") as f:
f.write(base64.b64decode(res["layoutImage"]))
ocr_img_path = f"ocr_{i}.jpg"
with open(ocr_img_path, "wb") as f:
f.write(base64.b64decode(res["ocrImage"]))
print(f"Output images saved at {layout_img_path} and {ocr_img_path}")
{kind=link}