| 处理器架构 | 操作系统 | 设备类型 | Python 版本 | 安装指令 |
|---|---|---|---|---|
| x86-64 | Linux | CPU | ||
| 3.8 | curl -s https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/deploy/paddlex_hpi/install_script/{paddlex 版本号}/install_paddlex_hpi.py | python3.8 - --arch x86_64 --os linux --device cpu --py 38 | |||
| 3.9 | curl -s https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/deploy/paddlex_hpi/install_script/{paddlex 版本号}/install_paddlex_hpi.py | python3.9 - --arch x86_64 --os linux --device cpu --py 39 | |||
| 3.10 | curl -s https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/deploy/paddlex_hpi/install_script/{paddlex 版本号}/install_paddlex_hpi.py | python3.10 - --arch x86_64 --os linux --device cpu --py 310 | |||
| GPU (CUDA 11.8 + cuDNN 8.6) | 3.8 | curl -s https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/deploy/paddlex_hpi/install_script/{paddlex 版本号}/install_paddlex_hpi.py | python3.8 - --arch x86_64 --os linux --device gpu_cuda118_cudnn86 --py 38 | ||
| 3.9 | curl -s https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/deploy/paddlex_hpi/install_script/{paddlex 版本号}/install_paddlex_hpi.py | python3.9 - --arch x86_64 --os linux --device gpu_cuda118_cudnn86 --py 39 | |||
| 3.10 | curl -s https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/deploy/paddlex_hpi/install_script/{paddlex 版本号}/install_paddlex_hpi.py | python3.10 - --arch x86_64 --os linux --device gpu_cuda118_cudnn86 --py 310 |
 选择需要部署的产线,并点击“获取”。之后,可以在页面下方的“开源产线部署SDK序列号管理”部分找到获取到的序列号:
选择需要部署的产线,并点击“获取”。之后,可以在页面下方的“开源产线部署SDK序列号管理”部分找到获取到的序列号:
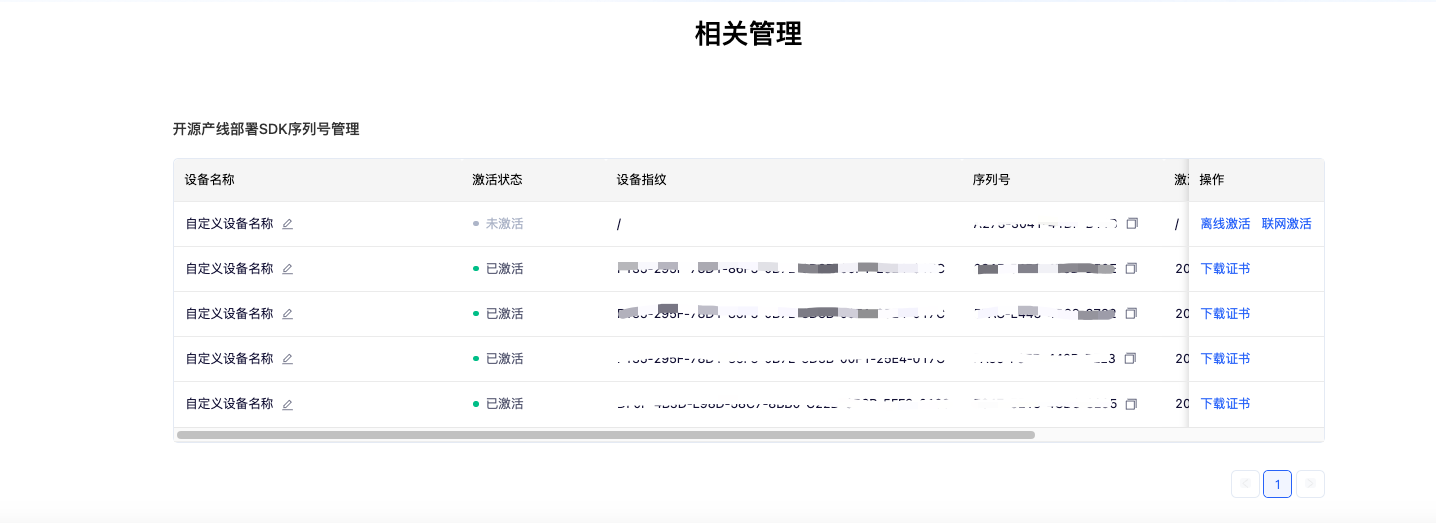 使用序列号完成激活后,即可使用高性能推理插件。PaddleX 提供离线激活和在线激活两种方式(均只支持 Linux 系统):
* 联网激活:在使用推理 API 或 CLI 时,通过参数指定序列号及联网激活,使程序自动完成激活。
* 离线激活:按照序列号管理界面中的指引(点击“操作”中的“离线激活”),获取机器的设备指纹,并将序列号与设备指纹绑定以获取证书,完成激活。使用这种激活方式,需要手动将证书存放在机器的 `${HOME}/.baidu/paddlex/licenses` 目录中(如果目录不存在,需要创建目录),并在使用推理 API 或 CLI 时指定序列号。
请注意:每个序列号只能绑定到唯一的设备指纹,且只能绑定一次。这意味着用户如果使用不同的机器部署模型,则必须为每台机器准备单独的序列号。
### 1.3 启用高性能推理插件
对于 Linux 系统,如果在 Docker 容器中使用高性能推理插件,请为容器挂载宿主机的 `/dev/disk/by-uuid` 与 `${HOME}/.baidu/paddlex/licenses` 目录。
对于 PaddleX CLI,指定 `--use_hpip`,并设置序列号,即可启用高性能推理插件。如果希望进行联网激活,在第一次使用序列号时,需指定 `--update_license`,以通用图像分类产线为例:
```bash
paddlex \
--pipeline image_classification \
--input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_image_classification_001.jpg \
--device gpu:0 \
--use_hpip \
--serial_number {序列号}
# 如果希望进行联网激活
paddlex \
--pipeline image_classification \
--input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_image_classification_001.jpg \
--device gpu:0 \
--use_hpip \
--serial_number {序列号}
--update_license
```
对于 PaddleX Python API,启用高性能推理插件的方法类似。仍以通用图像分类产线为例:
```python
from paddlex import create_pipeline
pipeline = create_pipeline(
pipeline="image_classification",
use_hpip=True,
hpi_params={"serial_number": "{序列号}"},
)
output = pipeline.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_image_classification_001.jpg")
```
启用高性能推理插件得到的推理结果与未启用插件时一致。对于部分模型,在首次启用高性能推理插件时,可能需要花费较长时间完成推理引擎的构建。PaddleX 将在推理引擎的第一次构建完成后将相关信息缓存在模型目录,并在后续复用缓存中的内容以提升初始化速度。
### 1.4 修改高性能推理配置
PaddleX 结合模型信息与运行环境信息为每个模型提供默认的高性能推理配置。这些默认配置经过精心准备,以便在数个常见场景中可用,且能够取得较优的性能。因此,通常用户可能并不用关心如何这些配置的具体细节。然而,由于实际部署环境与需求的多样性,使用默认配置可能无法在特定场景获取理想的性能,甚至可能出现推理失败的情况。对于默认配置无法满足要求的情形,用户可以通过修改模型目录中 `inference.yml` 文件中 `Hpi` 字段(如果该字段不存在,需要新增)的方式,手动调整配置。以下列举两种常见的情形:
- 更换推理后端:
当默认的推理后端不可用时,需要手动更换推理后端。用户需要修改 `selected_backends` 字段(如果不存在,需要新增)。
```yaml
Hpi:
...
selected_backends:
cpu: paddle_infer
gpu: onnx_runtime
...
```
其中每一项均按照 `{设备类型}: {推理后端名称}` 的格式填写。
目前所有可选的推理后端如下:
* `paddle_infer`:Paddle Inference 推理引擎。支持 CPU 和 GPU。相比 PaddleX 快速推理,高性能推理插件支持以集成 TensorRT 子图的方式提升模型的 GPU 推理性能。
* `openvino`:[OpenVINO](https://github.com/openvinotoolkit/openvino),Intel 提供的深度学习推理工具,优化了多种 Intel 硬件上的模型推理性能。仅支持 CPU。高性能推理插件自动将模型转换为 ONNX 格式后用该引擎推理。
* `onnx_runtime`:[ONNX Runtime](https://onnxruntime.ai/),跨平台、高性能的推理引擎。支持 CPU 和 GPU。高性能推理插件自动将模型转换为 ONNX 格式后用该引擎推理。
* `tensorrt`:[TensorRT](https://developer.nvidia.com/tensorrt),NVIDIA 提供的高性能深度学习推理库,针对 NVIDIA GPU 进行优化以提升速度。仅支持 GPU。高性能推理插件自动将模型转换为 ONNX 格式后用该引擎推理。
- 修改 Paddle Inference 或 TensorRT 的动态形状配置:
动态形状是 TensorRT 延迟指定部分或全部张量维度直到运行时的能力。当默认的动态形状配置无法满足需求(例如,模型可能需要范围外的输入形状),用户需要修改状推理后端配置中的 `trt_dynamic_shapes` 或 `dynamic_shapes` 字段:
```yaml
Hpi:
...
backend_configs:
# Paddle Inference 后端配置
paddle_infer:
...
trt_dynamic_shapes:
x:
- [1, 3, 300, 300]
- [4, 3, 300, 300]
- [32, 3, 1200, 1200]
...
# TensorRT 后端配置
tensorrt:
...
dynamic_shapes:
x:
- [1, 3, 300, 300]
- [4, 3, 300, 300]
- [32, 3, 1200, 1200]
...
```
在 `trt_dynamic_shapes` 或 `dynamic_shapes` 中,需要为每一个输入张量指定动态形状,格式为:`{输入张量名称}: [{最小形状}, [{最优形状}], [{最大形状}]]`。有关最小形状、最优形状以及最大形状的相关介绍及更多细节,请参考 TensorRT 官方文档。
在完成修改后,请删除模型目录中的缓存文件(`shape_range_info.pbtxt` 与 `trt_serialized` 开头的文件)。
## 2、支持使用高性能推理插件的产线与模型
使用序列号完成激活后,即可使用高性能推理插件。PaddleX 提供离线激活和在线激活两种方式(均只支持 Linux 系统):
* 联网激活:在使用推理 API 或 CLI 时,通过参数指定序列号及联网激活,使程序自动完成激活。
* 离线激活:按照序列号管理界面中的指引(点击“操作”中的“离线激活”),获取机器的设备指纹,并将序列号与设备指纹绑定以获取证书,完成激活。使用这种激活方式,需要手动将证书存放在机器的 `${HOME}/.baidu/paddlex/licenses` 目录中(如果目录不存在,需要创建目录),并在使用推理 API 或 CLI 时指定序列号。
请注意:每个序列号只能绑定到唯一的设备指纹,且只能绑定一次。这意味着用户如果使用不同的机器部署模型,则必须为每台机器准备单独的序列号。
### 1.3 启用高性能推理插件
对于 Linux 系统,如果在 Docker 容器中使用高性能推理插件,请为容器挂载宿主机的 `/dev/disk/by-uuid` 与 `${HOME}/.baidu/paddlex/licenses` 目录。
对于 PaddleX CLI,指定 `--use_hpip`,并设置序列号,即可启用高性能推理插件。如果希望进行联网激活,在第一次使用序列号时,需指定 `--update_license`,以通用图像分类产线为例:
```bash
paddlex \
--pipeline image_classification \
--input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_image_classification_001.jpg \
--device gpu:0 \
--use_hpip \
--serial_number {序列号}
# 如果希望进行联网激活
paddlex \
--pipeline image_classification \
--input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_image_classification_001.jpg \
--device gpu:0 \
--use_hpip \
--serial_number {序列号}
--update_license
```
对于 PaddleX Python API,启用高性能推理插件的方法类似。仍以通用图像分类产线为例:
```python
from paddlex import create_pipeline
pipeline = create_pipeline(
pipeline="image_classification",
use_hpip=True,
hpi_params={"serial_number": "{序列号}"},
)
output = pipeline.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_image_classification_001.jpg")
```
启用高性能推理插件得到的推理结果与未启用插件时一致。对于部分模型,在首次启用高性能推理插件时,可能需要花费较长时间完成推理引擎的构建。PaddleX 将在推理引擎的第一次构建完成后将相关信息缓存在模型目录,并在后续复用缓存中的内容以提升初始化速度。
### 1.4 修改高性能推理配置
PaddleX 结合模型信息与运行环境信息为每个模型提供默认的高性能推理配置。这些默认配置经过精心准备,以便在数个常见场景中可用,且能够取得较优的性能。因此,通常用户可能并不用关心如何这些配置的具体细节。然而,由于实际部署环境与需求的多样性,使用默认配置可能无法在特定场景获取理想的性能,甚至可能出现推理失败的情况。对于默认配置无法满足要求的情形,用户可以通过修改模型目录中 `inference.yml` 文件中 `Hpi` 字段(如果该字段不存在,需要新增)的方式,手动调整配置。以下列举两种常见的情形:
- 更换推理后端:
当默认的推理后端不可用时,需要手动更换推理后端。用户需要修改 `selected_backends` 字段(如果不存在,需要新增)。
```yaml
Hpi:
...
selected_backends:
cpu: paddle_infer
gpu: onnx_runtime
...
```
其中每一项均按照 `{设备类型}: {推理后端名称}` 的格式填写。
目前所有可选的推理后端如下:
* `paddle_infer`:Paddle Inference 推理引擎。支持 CPU 和 GPU。相比 PaddleX 快速推理,高性能推理插件支持以集成 TensorRT 子图的方式提升模型的 GPU 推理性能。
* `openvino`:[OpenVINO](https://github.com/openvinotoolkit/openvino),Intel 提供的深度学习推理工具,优化了多种 Intel 硬件上的模型推理性能。仅支持 CPU。高性能推理插件自动将模型转换为 ONNX 格式后用该引擎推理。
* `onnx_runtime`:[ONNX Runtime](https://onnxruntime.ai/),跨平台、高性能的推理引擎。支持 CPU 和 GPU。高性能推理插件自动将模型转换为 ONNX 格式后用该引擎推理。
* `tensorrt`:[TensorRT](https://developer.nvidia.com/tensorrt),NVIDIA 提供的高性能深度学习推理库,针对 NVIDIA GPU 进行优化以提升速度。仅支持 GPU。高性能推理插件自动将模型转换为 ONNX 格式后用该引擎推理。
- 修改 Paddle Inference 或 TensorRT 的动态形状配置:
动态形状是 TensorRT 延迟指定部分或全部张量维度直到运行时的能力。当默认的动态形状配置无法满足需求(例如,模型可能需要范围外的输入形状),用户需要修改状推理后端配置中的 `trt_dynamic_shapes` 或 `dynamic_shapes` 字段:
```yaml
Hpi:
...
backend_configs:
# Paddle Inference 后端配置
paddle_infer:
...
trt_dynamic_shapes:
x:
- [1, 3, 300, 300]
- [4, 3, 300, 300]
- [32, 3, 1200, 1200]
...
# TensorRT 后端配置
tensorrt:
...
dynamic_shapes:
x:
- [1, 3, 300, 300]
- [4, 3, 300, 300]
- [32, 3, 1200, 1200]
...
```
在 `trt_dynamic_shapes` 或 `dynamic_shapes` 中,需要为每一个输入张量指定动态形状,格式为:`{输入张量名称}: [{最小形状}, [{最优形状}], [{最大形状}]]`。有关最小形状、最优形状以及最大形状的相关介绍及更多细节,请参考 TensorRT 官方文档。
在完成修改后,请删除模型目录中的缓存文件(`shape_range_info.pbtxt` 与 `trt_serialized` 开头的文件)。
## 2、支持使用高性能推理插件的产线与模型
| 模型产线 | 产线模块 | 模型支持情况 |
|---|---|---|
| 通用OCR | 文本检测 | ✅ |
| 文本识别 | ✅ | |
| 文档场景信息抽取v3 | 表格识别 | ✅ |
| 版面区域检测 | ✅ | |
| 文本检测 | ✅ | |
| 文本识别 | ✅ | |
| 印章文本检测 | ✅ | |
| 文本图像矫正 | ✅ | |
| 文档图像方向分类 | ✅ | |
| 通用表格识别 | 版面区域检测 | ✅ |
| 表格识别 | ✅ | |
| 文本检测 | ✅ | |
| 文本识别 | ✅ | |
| 通用目标检测 | 目标检测 | FasterRCNN-Swin-Tiny-FPN ❌CenterNet-DLA-34 ❌ CenterNet-ResNet50 ❌ |
| 通用实例分割 | 实例分割 | Mask-RT-DETR-S ❌ |
| 通用图像分类 | 图像分类 | ✅ |
| 通用语义分割 | 语义分割 | ✅ |
| 时序预测 | 时序预测 | ❌ |
| 时序异常检测 | 时序异常预测 | ❌ |
| 时序分类 | 时序分类 | ❌ |
| 小目标检测 | 小目标检测 | ✅ |
| 图像多标签分类 | 图像多标签分类 | ✅ |
| 图像异常检测 | 无监督异常检测 | ✅ |
| 通用版面解析 | 表格结构识别 | ✅ |
| 版面区域分析 | ✅ | |
| 文本检测 | ✅ | |
| 文本识别 | ✅ | |
| 公式识别 | ✅ | |
| 印章文本检测 | ✅ | |
| 文本图像矫正 | ✅ | |
| 文档图像方向分类 | ✅ | |
| 公式识别 | 版面区域检测 | ✅ |
| 公式识别 | ✅ | |
| 印章文本识别 | 版面区域分析 | ✅ |
| 印章文本检测 | ✅ | |
| 文本识别 | ✅ | |
| 通用图像识别 | 主体检测 | ✅ |
| 图像特征 | ✅ | |
| 行人属性识别 | 行人检测 | ❌ |
| 行人属性识别 | ❌ | |
| 车辆属性识别 | 车辆检测 | ❌ |
| 车辆属性识别 | ❌ | |
| 人脸识别 | 人脸检测 | ✅ |
| 人脸特征 | ✅ |