 选择需要部署的产线,并点击“获取”。之后,可以在页面下方的“开源产线部署SDK序列号管理”部分找到获取到的序列号:
选择需要部署的产线,并点击“获取”。之后,可以在页面下方的“开源产线部署SDK序列号管理”部分找到获取到的序列号:
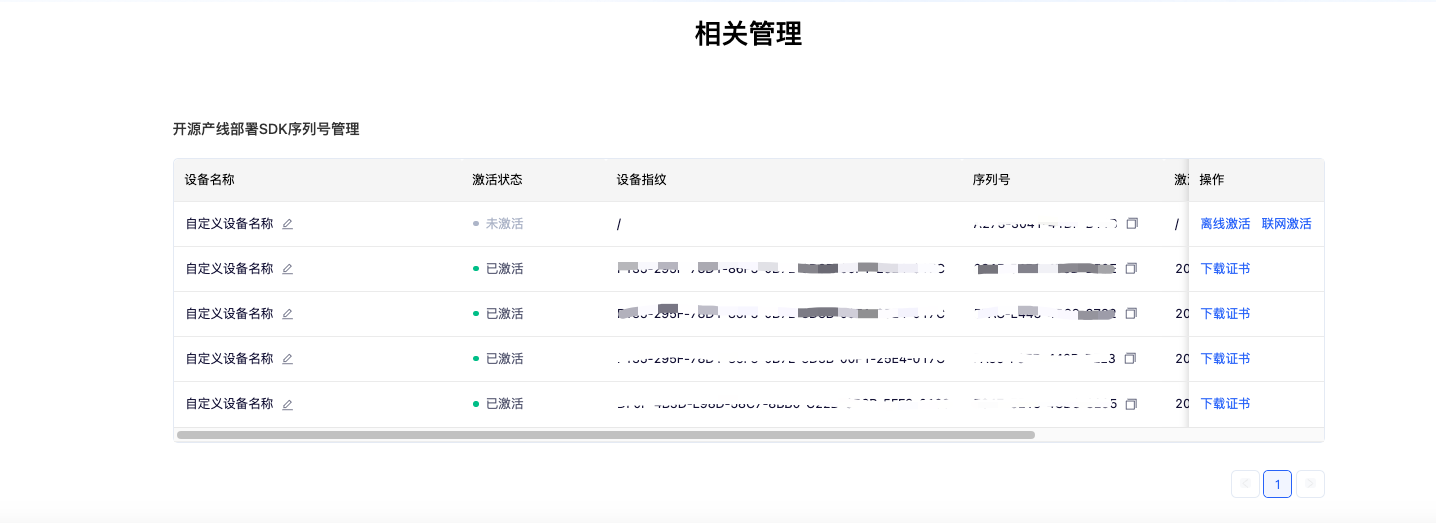 使用序列号完成激活后,即可使用高性能推理插件。PaddleX 提供离线激活和在线激活两种方式(均只支持 Linux 系统):
* 联网激活:在使用推理 API 或 CLI 时,通过参数指定序列号及联网激活,使程序自动完成激活。
* 离线激活:按照序列号管理界面中的指引(点击“操作”中的“离线激活”),获取机器的设备指纹,并将序列号与设备指纹绑定以获取证书,完成激活。使用这种激活方式,需要手动将证书存放在机器的 `${HOME}/.baidu/paddlex/licenses` 目录中(如果目录不存在,需要创建目录),并在使用推理 API 或 CLI 时指定序列号。
请注意:每个序列号只能绑定到唯一的设备指纹,且只能绑定一次。这意味着用户如果使用不同的机器部署模型,则必须为每台机器准备单独的序列号。
### 1.2 安装高性能推理插件
在下表中根据处理器架构、操作系统、设备类型、Python 版本等信息,找到对应的安装指令并在部署环境中执行:
使用序列号完成激活后,即可使用高性能推理插件。PaddleX 提供离线激活和在线激活两种方式(均只支持 Linux 系统):
* 联网激活:在使用推理 API 或 CLI 时,通过参数指定序列号及联网激活,使程序自动完成激活。
* 离线激活:按照序列号管理界面中的指引(点击“操作”中的“离线激活”),获取机器的设备指纹,并将序列号与设备指纹绑定以获取证书,完成激活。使用这种激活方式,需要手动将证书存放在机器的 `${HOME}/.baidu/paddlex/licenses` 目录中(如果目录不存在,需要创建目录),并在使用推理 API 或 CLI 时指定序列号。
请注意:每个序列号只能绑定到唯一的设备指纹,且只能绑定一次。这意味着用户如果使用不同的机器部署模型,则必须为每台机器准备单独的序列号。
### 1.2 安装高性能推理插件
在下表中根据处理器架构、操作系统、设备类型、Python 版本等信息,找到对应的安装指令并在部署环境中执行:
| 处理器架构 | 操作系统 | 设备类型 | Python 版本 | 安装指令 |
|---|---|---|---|---|
| x86-64 | Linux | CPU | ||
| 3.8 | curl -s https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/deploy/paddlex_hpi/install_script/latest/install_paddlex_hpi.py | python3.8 - --arch x86_64 --os linux --device cpu --py 38 | |||
| 3.9 | curl -s https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/deploy/paddlex_hpi/install_script/latest/install_paddlex_hpi.py | python3.9 - --arch x86_64 --os linux --device cpu --py 39 | |||
| 3.10 | curl -s https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/deploy/paddlex_hpi/install_script/latest/install_paddlex_hpi.py | python3.10 - --arch x86_64 --os linux --device cpu --py 310 | |||
| GPU (CUDA 11.8 + cuDNN 8.6) | 3.8 | curl -s https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/deploy/paddlex_hpi/install_script/latest/install_paddlex_hpi.py | python3.8 - --arch x86_64 --os linux --device gpu_cuda118_cudnn86 --py 38 | ||
| 3.9 | curl -s https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/deploy/paddlex_hpi/install_script/latest/install_paddlex_hpi.py | python3.9 - --arch x86_64 --os linux --device gpu_cuda118_cudnn86 --py 39 | |||
| 3.10 | curl -s https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/deploy/paddlex_hpi/install_script/latest/install_paddlex_hpi.py | python3.10 - --arch x86_64 --os linux --device gpu_cuda118_cudnn86 --py 310 |

 ### 1.5 更换产线或模型
- 更换产线:
若想更换其他产线使用高性能推理插件,则替换 `--pipeline` 传入的值即可,以下以通用目标检测产线为例:
```bash
paddlex --pipeline object_detection --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_object_detection_002.png --device gpu:0 --use_hpip --serial_number {序列号} --update_license True --save_path ./output
```
- 更换模型:
OCR 产线默认使用 PP-OCRv4_mobile_det、PP-OCRv4_mobile_rec 模型,若想更换其他模型,如 PP-OCRv4_server_det、PP-OCRv4_server_rec 模型,可参考 [通用OCR产线使用教程](../pipeline_usage/tutorials/ocr_pipelines/OCR.md),具体操作如下:
```bash
# 1. 获取 OCR 产线配置文件并保存到 ./OCR.yaml
paddlex --get_pipeline_config OCR --save_path ./OCR.yaml
# 2. 修改 ./OCR.yaml 配置文件
# 将 Pipeline.text_det_model 的值改为 PP-OCRv4_server_det 模型所在路径
# 将 Pipeline.text_rec_model 的值改为 PP-OCRv4_server_rec 模型所在路径
# 3. 执行推理时使用修改后的配置文件
paddlex --pipeline ./OCR.yaml --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png --device gpu:0 --use_hpip --serial_number {序列号} --update_license True --save_path ./output
```
通用目标检测产线默认使用 PicoDet-S 模型,若想更换其他模型,如 RT-DETR 模型,可参考 [通用目标检测产线使用教程](../pipeline_usage/tutorials/cv_pipelines/object_detection.md),具体操作如下:
```bash
# 1. 获取 OCR 产线配置文件并保存到 ./object_detection.yaml
paddlex --get_pipeline_config object_detection --save_path ./object_detection.yaml
# 2. 修改 ./object_detection.yaml 配置文件
# 将 Pipeline.model 的值改为 RT-DETR 模型所在路径
# 3. 执行推理时使用修改后的配置文件
paddlex --pipeline ./object_detection.yaml --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png --device gpu:0 --use_hpip --serial_number {序列号} --update_license True --save_path ./output
```
其他产线的操作与上述两条产线的操作类似,更多细节可参考产线使用教程。
## 2 服务化部署示例
### 2.1 安装服务化部署插件
执行如下指令,安装服务化部署插件:
```
paddlex --install serving
```
### 2.2 启动服务
通过 PaddleX CLI 启动服务,指令格式为:
```shell
paddlex --serve --pipeline {产线名称或产线配置文件路径} [{其他命令行选项}]
```
以通用OCR产线为例:
```shell
paddlex --serve --pipeline OCR
```
服务启动成功后,可以看到类似如下展示的信息:
```
INFO: Started server process [63108]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
```
`--pipeline` 可指定为官方产线名称或本地产线配置文件路径。PaddleX 以此构建产线并部署为服务。如需调整配置(如模型路径、batch_size、部署设备等),请参考[通用OCR产线使用教程](../pipeline_usage/tutorials/ocr_pipelines/OCR.md)中的 “模型应用” 部分。
与服务化部署相关的命令行选项如下:
### 1.5 更换产线或模型
- 更换产线:
若想更换其他产线使用高性能推理插件,则替换 `--pipeline` 传入的值即可,以下以通用目标检测产线为例:
```bash
paddlex --pipeline object_detection --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_object_detection_002.png --device gpu:0 --use_hpip --serial_number {序列号} --update_license True --save_path ./output
```
- 更换模型:
OCR 产线默认使用 PP-OCRv4_mobile_det、PP-OCRv4_mobile_rec 模型,若想更换其他模型,如 PP-OCRv4_server_det、PP-OCRv4_server_rec 模型,可参考 [通用OCR产线使用教程](../pipeline_usage/tutorials/ocr_pipelines/OCR.md),具体操作如下:
```bash
# 1. 获取 OCR 产线配置文件并保存到 ./OCR.yaml
paddlex --get_pipeline_config OCR --save_path ./OCR.yaml
# 2. 修改 ./OCR.yaml 配置文件
# 将 Pipeline.text_det_model 的值改为 PP-OCRv4_server_det 模型所在路径
# 将 Pipeline.text_rec_model 的值改为 PP-OCRv4_server_rec 模型所在路径
# 3. 执行推理时使用修改后的配置文件
paddlex --pipeline ./OCR.yaml --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png --device gpu:0 --use_hpip --serial_number {序列号} --update_license True --save_path ./output
```
通用目标检测产线默认使用 PicoDet-S 模型,若想更换其他模型,如 RT-DETR 模型,可参考 [通用目标检测产线使用教程](../pipeline_usage/tutorials/cv_pipelines/object_detection.md),具体操作如下:
```bash
# 1. 获取 OCR 产线配置文件并保存到 ./object_detection.yaml
paddlex --get_pipeline_config object_detection --save_path ./object_detection.yaml
# 2. 修改 ./object_detection.yaml 配置文件
# 将 Pipeline.model 的值改为 RT-DETR 模型所在路径
# 3. 执行推理时使用修改后的配置文件
paddlex --pipeline ./object_detection.yaml --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png --device gpu:0 --use_hpip --serial_number {序列号} --update_license True --save_path ./output
```
其他产线的操作与上述两条产线的操作类似,更多细节可参考产线使用教程。
## 2 服务化部署示例
### 2.1 安装服务化部署插件
执行如下指令,安装服务化部署插件:
```
paddlex --install serving
```
### 2.2 启动服务
通过 PaddleX CLI 启动服务,指令格式为:
```shell
paddlex --serve --pipeline {产线名称或产线配置文件路径} [{其他命令行选项}]
```
以通用OCR产线为例:
```shell
paddlex --serve --pipeline OCR
```
服务启动成功后,可以看到类似如下展示的信息:
```
INFO: Started server process [63108]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
```
`--pipeline` 可指定为官方产线名称或本地产线配置文件路径。PaddleX 以此构建产线并部署为服务。如需调整配置(如模型路径、batch_size、部署设备等),请参考[通用OCR产线使用教程](../pipeline_usage/tutorials/ocr_pipelines/OCR.md)中的 “模型应用” 部分。
与服务化部署相关的命令行选项如下:
| 名称 | 说明 |
|---|---|
--pipeline |
产线名称或产线配置文件路径。 |
--device |
产线部署设备。默认为 cpu(如 GPU 不可用)或 gpu(如 GPU 可用)。 |
--host |
服务器绑定的主机名或 IP 地址。默认为0.0.0.0。 |
--port |
服务器监听的端口号。默认为8080。 |
--use_hpip |
如果指定,则启用高性能推理插件。 |
--serial_number |
高性能推理插件使用的序列号。只在启用高性能推理插件时生效。 请注意,并非所有产线、模型都支持使用高性能推理插件,详细的支持情况请参考PaddleX 高性能推理指南。 |
--update_license |
如果指定,则进行联网激活。只在启用高性能推理插件时生效。 |
 ### 2.5 更换产线或模型
- 更换产线:
若想更换其他产线进行服务化部署,则替换 `--pipeline` 传入的值即可,以下以通用目标检测产线为例:
```bash
paddlex --serve --pipeline object_detection
```
- 更换模型:
OCR 产线默认使用 PP-OCRv4_mobile_det、PP-OCRv4_mobile_rec 模型,若想更换其他模型,如 PP-OCRv4_server_det、PP-OCRv4_server_rec 模型,可参考 [通用OCR产线使用教程](../pipeline_usage/tutorials/ocr_pipelines/OCR.md),具体操作如下:
```bash
# 1. 获取 OCR 产线配置文件并保存到 ./OCR.yaml
paddlex --get_pipeline_config OCR --save_path ./OCR.yaml
# 2. 修改 ./OCR.yaml 配置文件
# 将 Pipeline.text_det_model 的值改为 PP-OCRv4_server_det 模型所在路径
# 将 Pipeline.text_rec_model 的值改为 PP-OCRv4_server_rec 模型所在路径
# 3. 启动服务时使用修改后的配置文件
paddlex --serve --pipeline ./OCR.yaml
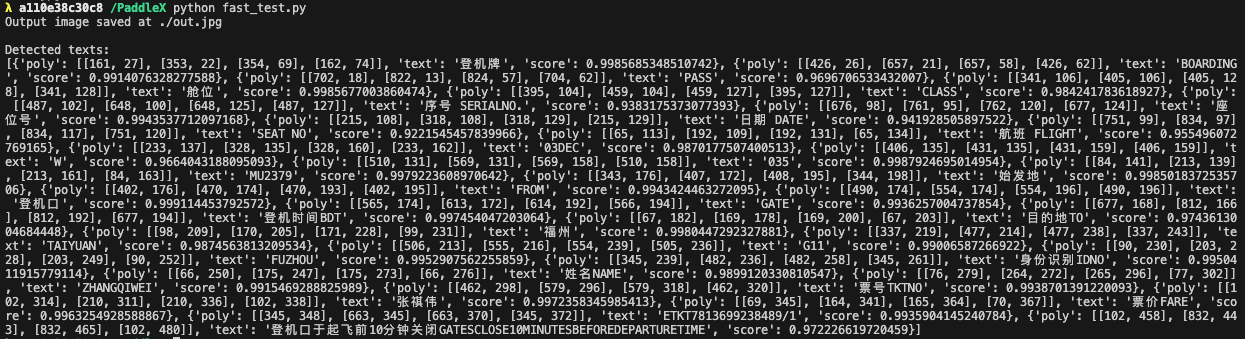
# 4. 调用服务
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png -O demo.jpg
python fast_test.py
```
通用目标检测产线默认使用 PicoDet-S 模型,若想更换其他模型,如 RT-DETR 模型,可参考 [通用目标检测产线使用教程](../pipeline_usage/tutorials/cv_pipelines/object_detection.md),具体操作如下:
```bash
# 1. 获取 OCR 产线配置文件并保存到 ./object_detection.yaml
paddlex --get_pipeline_config object_detection --save_path ./object_detection.yaml
# 2. 修改 ./object_detection.yaml 配置文件
# 将 Pipeline.model 的值改为 RT-DETR 模型所在路径
# 3. 启动服务时使用修改后的配置文件
paddlex --serve --pipeline ./object_detection.yaml
# 4. 调用服务 | fast_test.py 需要替换为通用目标检测产线使用教程中的 Python 调用示例
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png -O demo.jpg
python fast_test.py
```
其他产线的操作与上述两条产线的操作类似,更多细节可参考产线使用教程。
## 3 端侧部署示例
### 3.1 环境准备
1. 在本地环境安装好 CMake 编译工具,并在 [Android NDK 官网](https://developer.android.google.cn/ndk/downloads)下载当前系统符合要求的版本的 NDK 软件包。例如,在 Mac 上开发,需要在 Android NDK 官网下载 Mac 平台的 NDK 软件包。
环境要求
- `CMake >= 3.10`(最低版本未经验证,推荐 3.20 及以上)
- `Android NDK >= r17c`(最低版本未经验证,推荐 r20b 及以上)
本指南所使用的测试环境:
- `cmake == 3.20.0`
- `android-ndk == r20b`
2. 准备一部 Android 手机,并开启 USB 调试模式。开启方法: `手机设置 -> 查找开发者选项 -> 打开开发者选项和 USB 调试模式`。
3. 电脑上安装 ADB 工具,用于调试。ADB 安装方式如下:
3.1. Mac 电脑安装 ADB
```shell
brew cask install android-platform-tools
```
3.2. Linux 安装 ADB
```shell
# debian系linux发行版的安装方式
sudo apt update
sudo apt install -y wget adb
# redhat系linux发行版的安装方式
sudo yum install adb
```
3.3. Windows 安装 ADB
win 上安装需要去谷歌的安卓平台下载 ADB 软件包进行安装:[链接](https://developer.android.com/studio)
打开终端,手机连接电脑,在终端中输入
```shell
adb devices
```
如果有 device 输出,则表示安装成功。
```shell
List of devices attached
744be294 device
```
### 3.2 物料准备
1. 克隆 `Paddle-Lite-Demo` 仓库的 `feature/paddle-x` 分支到 `PaddleX-Lite-Deploy` 目录。
```shell
git clone -b feature/paddle-x https://github.com/PaddlePaddle/Paddle-Lite-Demo.git PaddleX-Lite-Deploy
```
2. 填写 [问卷](https://paddle.wjx.cn/vm/eaaBo0H.aspx#) 下载压缩包,将压缩包放到指定解压目录,切换到指定解压目录后执行解压命令。
```shell
# 1. 切换到指定解压目录
cd PaddleX-Lite-Deploy/ocr/android/shell/ppocr_demo
# 2. 执行解压命令
unzip ocr.zip
```
### 3.3 部署步骤
1. 将工作目录切换到 `PaddleX-Lite-Deploy/libs` 目录,运行 `download.sh` 脚本,下载需要的 Paddle Lite 预测库。此步骤只需执行一次,即可支持每个 demo 使用。
2. 将工作目录切换到 `PaddleX-Lite-Deploy/ocr/assets` 目录,运行 `download.sh` 脚本,下载 [paddle_lite_opt 工具](https://www.paddlepaddle.org.cn/lite/v2.10/user_guides/model_optimize_tool.html) 优化后的模型文件。
3. 将工作目录切换到 `PaddleX-Lite-Deploy/ocr/android/shell/cxx/ppocr_demo` 目录,运行 `build.sh` 脚本,完成可执行文件的编译。
4. 将工作目录切换到 `PaddleX-Lite-Deploy/ocr/android/shell/cxx/ppocr_demo`,运行 `run.sh` 脚本,完成在端侧的预测。
注意事项:
- 在运行 `build.sh` 脚本前,需要更改 `NDK_ROOT` 指定的路径为实际安装的 NDK 路径。
- 在 Windows 系统上可以使用 Git Bash 执行部署步骤。
- 若在 Windows 系统上编译,需要将 `CMakeLists.txt` 中的 `CMAKE_SYSTEM_NAME` 设置为 `windows`。
- 若在 Mac 系统上编译,需要将 `CMakeLists.txt` 中的 `CMAKE_SYSTEM_NAME` 设置为 `darwin`。
- 在运行 `run.sh` 脚本时需保持 ADB 连接。
- `download.sh` 和 `run.sh` 支持传入参数来指定模型,若不指定则默认使用 `PP-OCRv4_mobile` 模型。目前适配了 2 个模型:
- `PP-OCRv3_mobile`
- `PP-OCRv4_mobile`
以下为实际操作时的示例:
```shell
# 1. 下载需要的 Paddle Lite 预测库
cd PaddleX-Lite-Deploy/libs
sh download.sh
# 2. 下载 paddle_lite_opt 工具优化后的模型文件
cd ../ocr/assets
sh download.sh PP-OCRv4_mobile
# 3. 完成可执行文件的编译
cd ../android/shell/ppocr_demo
sh build.sh
# 4. 预测
sh run.sh PP-OCRv4_mobile
```
检测结果:
### 2.5 更换产线或模型
- 更换产线:
若想更换其他产线进行服务化部署,则替换 `--pipeline` 传入的值即可,以下以通用目标检测产线为例:
```bash
paddlex --serve --pipeline object_detection
```
- 更换模型:
OCR 产线默认使用 PP-OCRv4_mobile_det、PP-OCRv4_mobile_rec 模型,若想更换其他模型,如 PP-OCRv4_server_det、PP-OCRv4_server_rec 模型,可参考 [通用OCR产线使用教程](../pipeline_usage/tutorials/ocr_pipelines/OCR.md),具体操作如下:
```bash
# 1. 获取 OCR 产线配置文件并保存到 ./OCR.yaml
paddlex --get_pipeline_config OCR --save_path ./OCR.yaml
# 2. 修改 ./OCR.yaml 配置文件
# 将 Pipeline.text_det_model 的值改为 PP-OCRv4_server_det 模型所在路径
# 将 Pipeline.text_rec_model 的值改为 PP-OCRv4_server_rec 模型所在路径
# 3. 启动服务时使用修改后的配置文件
paddlex --serve --pipeline ./OCR.yaml
# 4. 调用服务
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png -O demo.jpg
python fast_test.py
```
通用目标检测产线默认使用 PicoDet-S 模型,若想更换其他模型,如 RT-DETR 模型,可参考 [通用目标检测产线使用教程](../pipeline_usage/tutorials/cv_pipelines/object_detection.md),具体操作如下:
```bash
# 1. 获取 OCR 产线配置文件并保存到 ./object_detection.yaml
paddlex --get_pipeline_config object_detection --save_path ./object_detection.yaml
# 2. 修改 ./object_detection.yaml 配置文件
# 将 Pipeline.model 的值改为 RT-DETR 模型所在路径
# 3. 启动服务时使用修改后的配置文件
paddlex --serve --pipeline ./object_detection.yaml
# 4. 调用服务 | fast_test.py 需要替换为通用目标检测产线使用教程中的 Python 调用示例
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png -O demo.jpg
python fast_test.py
```
其他产线的操作与上述两条产线的操作类似,更多细节可参考产线使用教程。
## 3 端侧部署示例
### 3.1 环境准备
1. 在本地环境安装好 CMake 编译工具,并在 [Android NDK 官网](https://developer.android.google.cn/ndk/downloads)下载当前系统符合要求的版本的 NDK 软件包。例如,在 Mac 上开发,需要在 Android NDK 官网下载 Mac 平台的 NDK 软件包。
环境要求
- `CMake >= 3.10`(最低版本未经验证,推荐 3.20 及以上)
- `Android NDK >= r17c`(最低版本未经验证,推荐 r20b 及以上)
本指南所使用的测试环境:
- `cmake == 3.20.0`
- `android-ndk == r20b`
2. 准备一部 Android 手机,并开启 USB 调试模式。开启方法: `手机设置 -> 查找开发者选项 -> 打开开发者选项和 USB 调试模式`。
3. 电脑上安装 ADB 工具,用于调试。ADB 安装方式如下:
3.1. Mac 电脑安装 ADB
```shell
brew cask install android-platform-tools
```
3.2. Linux 安装 ADB
```shell
# debian系linux发行版的安装方式
sudo apt update
sudo apt install -y wget adb
# redhat系linux发行版的安装方式
sudo yum install adb
```
3.3. Windows 安装 ADB
win 上安装需要去谷歌的安卓平台下载 ADB 软件包进行安装:[链接](https://developer.android.com/studio)
打开终端,手机连接电脑,在终端中输入
```shell
adb devices
```
如果有 device 输出,则表示安装成功。
```shell
List of devices attached
744be294 device
```
### 3.2 物料准备
1. 克隆 `Paddle-Lite-Demo` 仓库的 `feature/paddle-x` 分支到 `PaddleX-Lite-Deploy` 目录。
```shell
git clone -b feature/paddle-x https://github.com/PaddlePaddle/Paddle-Lite-Demo.git PaddleX-Lite-Deploy
```
2. 填写 [问卷](https://paddle.wjx.cn/vm/eaaBo0H.aspx#) 下载压缩包,将压缩包放到指定解压目录,切换到指定解压目录后执行解压命令。
```shell
# 1. 切换到指定解压目录
cd PaddleX-Lite-Deploy/ocr/android/shell/ppocr_demo
# 2. 执行解压命令
unzip ocr.zip
```
### 3.3 部署步骤
1. 将工作目录切换到 `PaddleX-Lite-Deploy/libs` 目录,运行 `download.sh` 脚本,下载需要的 Paddle Lite 预测库。此步骤只需执行一次,即可支持每个 demo 使用。
2. 将工作目录切换到 `PaddleX-Lite-Deploy/ocr/assets` 目录,运行 `download.sh` 脚本,下载 [paddle_lite_opt 工具](https://www.paddlepaddle.org.cn/lite/v2.10/user_guides/model_optimize_tool.html) 优化后的模型文件。
3. 将工作目录切换到 `PaddleX-Lite-Deploy/ocr/android/shell/cxx/ppocr_demo` 目录,运行 `build.sh` 脚本,完成可执行文件的编译。
4. 将工作目录切换到 `PaddleX-Lite-Deploy/ocr/android/shell/cxx/ppocr_demo`,运行 `run.sh` 脚本,完成在端侧的预测。
注意事项:
- 在运行 `build.sh` 脚本前,需要更改 `NDK_ROOT` 指定的路径为实际安装的 NDK 路径。
- 在 Windows 系统上可以使用 Git Bash 执行部署步骤。
- 若在 Windows 系统上编译,需要将 `CMakeLists.txt` 中的 `CMAKE_SYSTEM_NAME` 设置为 `windows`。
- 若在 Mac 系统上编译,需要将 `CMakeLists.txt` 中的 `CMAKE_SYSTEM_NAME` 设置为 `darwin`。
- 在运行 `run.sh` 脚本时需保持 ADB 连接。
- `download.sh` 和 `run.sh` 支持传入参数来指定模型,若不指定则默认使用 `PP-OCRv4_mobile` 模型。目前适配了 2 个模型:
- `PP-OCRv3_mobile`
- `PP-OCRv4_mobile`
以下为实际操作时的示例:
```shell
# 1. 下载需要的 Paddle Lite 预测库
cd PaddleX-Lite-Deploy/libs
sh download.sh
# 2. 下载 paddle_lite_opt 工具优化后的模型文件
cd ../ocr/assets
sh download.sh PP-OCRv4_mobile
# 3. 完成可执行文件的编译
cd ../android/shell/ppocr_demo
sh build.sh
# 4. 预测
sh run.sh PP-OCRv4_mobile
```
检测结果:
 识别结果:
```text
The detection visualized image saved in ./test_img_result.jpg
0 纯臻营养护发素 0.993706
1 产品信息/参数 0.991224
2 (45元/每公斤,100公斤起订) 0.938893
3 每瓶22元,1000瓶起订) 0.988353
4 【品牌】:代加工方式/OEMODM 0.97557
5 【品名】:纯臻营养护发素 0.986914
6 ODMOEM 0.929891
7 【产品编号】:YM-X-3011 0.964156
8 【净含量】:220ml 0.976404
9 【适用人群】:适合所有肤质 0.987942
10 【主要成分】:鲸蜡硬脂醇、燕麦β-葡聚 0.968315
11 糖、椰油酰胺丙基甜菜碱、泛醒 0.941537
12 (成品包材) 0.974796
13 【主要功能】:可紧致头发磷层,从而达到 0.988799
14 即时持久改善头发光泽的效果,给干燥的头 0.989547
15 发足够的滋养 0.998413
```
识别结果:
```text
The detection visualized image saved in ./test_img_result.jpg
0 纯臻营养护发素 0.993706
1 产品信息/参数 0.991224
2 (45元/每公斤,100公斤起订) 0.938893
3 每瓶22元,1000瓶起订) 0.988353
4 【品牌】:代加工方式/OEMODM 0.97557
5 【品名】:纯臻营养护发素 0.986914
6 ODMOEM 0.929891
7 【产品编号】:YM-X-3011 0.964156
8 【净含量】:220ml 0.976404
9 【适用人群】:适合所有肤质 0.987942
10 【主要成分】:鲸蜡硬脂醇、燕麦β-葡聚 0.968315
11 糖、椰油酰胺丙基甜菜碱、泛醒 0.941537
12 (成品包材) 0.974796
13 【主要功能】:可紧致头发磷层,从而达到 0.988799
14 即时持久改善头发光泽的效果,给干燥的头 0.989547
15 发足够的滋养 0.998413
```