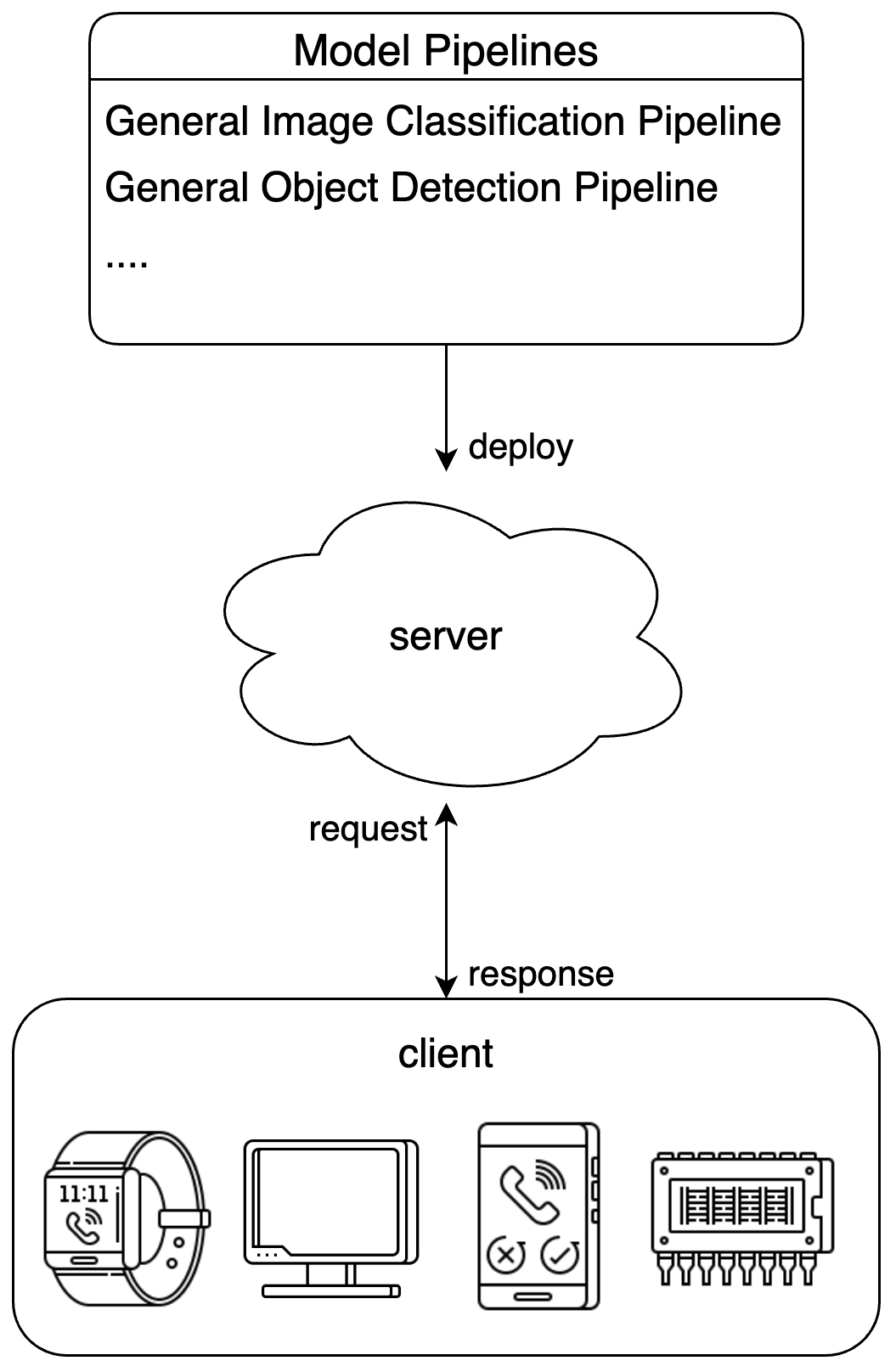
 ## 1. Basic Process
### 1.1 Install the Serving Deployment Plugin
Execute the following command to install the serving deployment plugin:
```shell
paddlex --install serving
```
### 1.2 Start the Service
Start the service through the PaddleX CLI with the following command format:
```shell
paddlex --serve --pipeline {pipeline_name_or_path} [{other_command_line_options}]
```
Taking the General Image Classification Pipeline as an example:
```shell
paddlex --serve --pipeline image_classification
```
After the service starts successfully, you will see information similar to the following:
```
INFO: Started server process [63108]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
```
`--pipeline` can be specified as an official pipeline name or the path to a local pipeline configuration file. PaddleX uses this to build the pipeline and deploy it as a service. To adjust configurations (such as model path, batch_size, deployment device), please refer to the "Model Application" section in the [General Image Classification Pipeline Tutorial](../pipeline_usage/tutorials/cv_pipelines/image_classification.en.md).
Command-line options related to serving deployment are as follows:
## 1. Basic Process
### 1.1 Install the Serving Deployment Plugin
Execute the following command to install the serving deployment plugin:
```shell
paddlex --install serving
```
### 1.2 Start the Service
Start the service through the PaddleX CLI with the following command format:
```shell
paddlex --serve --pipeline {pipeline_name_or_path} [{other_command_line_options}]
```
Taking the General Image Classification Pipeline as an example:
```shell
paddlex --serve --pipeline image_classification
```
After the service starts successfully, you will see information similar to the following:
```
INFO: Started server process [63108]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
```
`--pipeline` can be specified as an official pipeline name or the path to a local pipeline configuration file. PaddleX uses this to build the pipeline and deploy it as a service. To adjust configurations (such as model path, batch_size, deployment device), please refer to the "Model Application" section in the [General Image Classification Pipeline Tutorial](../pipeline_usage/tutorials/cv_pipelines/image_classification.en.md).
Command-line options related to serving deployment are as follows:
| Name | Description |
|---|---|
--pipeline |
Pipeline name or pipeline configuration file path. |
--device |
Deployment device for the pipeline. Defaults to cpu (If GPU is unavailable) or gpu (If GPU is available). |
--host |
Hostname or IP address bound to the server. Defaults to 0.0.0.0. |
--port |
Port number listened to by the server. Defaults to 8080. |
--use_hpip |
Enables the high-performance inference plugin if specified. |
--serial_number |
Serial number used by the high-performance inference plugin. Only valid when the high-performance inference plugin is enabled. Note that not all pipelines and models support the use of the high-performance inference plugin. For detailed support, please refer to the PaddleX High-Performance Inference Guide. |
--update_license |
Activates the license online if specified. Only valid when the high-performance inference plugin is enabled. |