---
comments: true
---
# 文本识别模块使用教程
## 一、概述
文本识别模块是OCR(光学字符识别)系统中的核心部分,负责从图像中的文本区域提取出文本信息。该模块的性能直接影响到整个OCR系统的准确性和效率。文本识别模块通常接收文本检测模块输出的文本区域的边界框(Bounding Boxes)作为输入,然后通过复杂的图像处理和深度学习算法,将图像中的文本转化为可编辑和可搜索的电子文本。文本识别结果的准确性,对于后续的信息提取和数据挖掘等应用至关重要。
## 二、支持模型列表
| 模型 | 模型下载链接 |
识别 Avg Accuracy(%) |
GPU推理耗时(ms) |
CPU推理耗时 (ms) |
模型存储大小(M) |
介绍 |
| PP-OCRv4_server_rec_doc | 推理模型/训练模型 |
81.53 |
|
|
74.7 M |
PP-OCRv4_server_rec_doc是在PP-OCRv4_server_rec的基础上,在更多中文文档数据和PP-OCR训练数据的混合数据训练而成,增加了部分繁体字、日文、特殊字符的识别能力,可支持识别的字符为1.5万+,除文档相关的文字识别能力提升外,也同时提升了通用文字的识别能力 |
| PP-OCRv4_mobile_rec | 推理模型/训练模型 |
78.74 |
7.95018 |
46.7868 |
10.6 M |
PP-OCRv4的轻量级识别模型,推理效率高,可以部署在包含端侧设备的多种硬件设备中 |
| PP-OCRv4_server_rec | 推理模型/训练模型 |
80.61 |
7.19439 |
140.179 |
71.2 M |
PP-OCRv4的服务器端模型,推理精度高,可以部署在多种不同的服务器上 |
| en_PP-OCRv4_mobile_rec | 推理模型/训练模型 |
70.39 |
|
|
6.8 M |
基于PP-OCRv4识别模型训练得到的超轻量英文识别模型,支持英文、数字识别 |
注:以上精度指标的评估集是 PaddleOCR 自建的中文数据集,覆盖街景、网图、文档、手写多个场景,其中文本识别包含 1.1w 张图片。所有模型 GPU 推理耗时基于 NVIDIA Tesla T4 机器,精度类型为 FP32, CPU 推理速度基于 Intel(R) Xeon(R) Gold 5117 CPU @ 2.00GHz,线程数为8,精度类型为 FP32。
> ❗ 以上列出的是文本识别模块重点支持的4个核心模型,该模块总共支持18个全量模型,包含多个多语言文本识别模型,完整的模型列表如下:
👉模型列表详情
* 中文识别模型
| 模型 | 模型下载链接 |
识别 Avg Accuracy(%) |
GPU推理耗时(ms) |
CPU推理耗时 (ms) |
模型存储大小(M) |
介绍 |
| PP-OCRv4_server_rec_doc | 推理模型/训练模型 |
81.53 |
|
|
74.7 M |
PP-OCRv4_server_rec_doc是在PP-OCRv4_server_rec的基础上,在更多中文文档数据和PP-OCR训练数据的混合数据训练而成,增加了部分繁体字、日文、特殊字符的识别能力,可支持识别的字符为1.5万+,除文档相关的文字识别能力提升外,也同时提升了通用文字的识别能力 |
| PP-OCRv4_mobile_rec | 推理模型/训练模型 |
78.74 |
7.95018 |
46.7868 |
10.6 M |
PP-OCRv4的轻量级识别模型,推理效率高,可以部署在包含端侧设备的多种硬件设备中 |
| PP-OCRv4_server_rec | 推理模型/训练模型 |
80.61 |
7.19439 |
140.179 |
71.2 M |
PP-OCRv4的服务器端模型,推理精度高,可以部署在多种不同的服务器上 |
| PP-OCRv3_mobile_rec | 推理模型/训练模型 |
72.96 |
|
|
9.2 M |
PP-OCRv3的轻量级识别模型,推理效率高,可以部署在包含端侧设备的多种硬件设备中 |
注:以上精度指标的评估集是 PaddleOCR 自建的中文数据集,覆盖街景、网图、文档、手写多个场景,其中文本识别包含 8367 张图片。所有模型 GPU 推理耗时基于 NVIDIA Tesla T4 机器,精度类型为 FP32, CPU 推理速度基于 Intel(R) Xeon(R) Gold 5117 CPU @ 2.00GHz,线程数为8,精度类型为 FP32。
| 模型 | 模型下载链接 |
识别 Avg Accuracy(%) |
GPU推理耗时(ms) |
CPU推理耗时 |
模型存储大小(M) |
介绍 |
| ch_SVTRv2_rec | 推理模型/训练模型 |
68.81 |
8.36801 |
165.706 |
73.9 M |
SVTRv2 是一种由复旦大学视觉与学习实验室(FVL)的OpenOCR团队研发的服务端文本识别模型,其在PaddleOCR算法模型挑战赛 - 赛题一:OCR端到端识别任务中荣获一等奖,A榜端到端识别精度相比PP-OCRv4提升6%。
|
注:以上精度指标的评估集是 PaddleOCR算法模型挑战赛 - 赛题一:OCR端到端识别任务A榜。 所有模型 GPU 推理耗时基于 NVIDIA Tesla T4 机器,精度类型为 FP32, CPU 推理速度基于 Intel(R) Xeon(R) Gold 5117 CPU @ 2.00GHz,线程数为8,精度类型为 FP32。
| 模型 | 模型下载链接 |
识别 Avg Accuracy(%) |
GPU推理耗时(ms) |
CPU推理耗时 |
模型存储大小(M) |
介绍 |
| ch_RepSVTR_rec | 推理模型/训练模型 |
65.07 |
10.5047 |
51.5647 |
22.1 M |
RepSVTR 文本识别模型是一种基于SVTRv2 的移动端文本识别模型,其在PaddleOCR算法模型挑战赛 - 赛题一:OCR端到端识别任务中荣获一等奖,B榜端到端识别精度相比PP-OCRv4提升2.5%,推理速度持平。 |
注:以上精度指标的评估集是 PaddleOCR算法模型挑战赛 - 赛题一:OCR端到端识别任务B榜。 所有模型 GPU 推理耗时基于 NVIDIA Tesla T4 机器,精度类型为 FP32, CPU 推理速度基于 Intel(R) Xeon(R) Gold 5117 CPU @ 2.00GHz,线程数为8,精度类型为 FP32。
* 英文识别模型
| 模型 | 模型下载链接 |
识别 Avg Accuracy(%) |
GPU推理耗时(ms) |
CPU推理耗时 |
模型存储大小(M) |
介绍 |
| en_PP-OCRv4_mobile_rec | 推理模型/训练模型 |
70.39 |
|
|
6.8 M |
基于PP-OCRv4识别模型训练得到的超轻量英文识别模型,支持英文、数字识别 |
| en_PP-OCRv3_mobile_rec | 推理模型/训练模型 |
70.69 |
|
|
7.8 M |
基于PP-OCRv3识别模型训练得到的超轻量英文识别模型,支持英文、数字识别 |
* 多语言识别模型
| 模型 | 模型下载链接 |
识别 Avg Accuracy(%) |
GPU推理耗时(ms) |
CPU推理耗时 |
模型存储大小(M) |
介绍 |
| korean_PP-OCRv3_mobile_rec | 推理模型/训练模型 |
60.21 |
|
|
8.6 M |
基于PP-OCRv3识别模型训练得到的超轻量韩文识别模型,支持韩文、数字识别 |
| japan_PP-OCRv3_mobile_rec | 推理模型/训练模型 |
45.69 |
|
|
8.8 M |
基于PP-OCRv3识别模型训练得到的超轻量日文识别模型,支持日文、数字识别 |
| chinese_cht_PP-OCRv3_mobile_rec | 推理模型/训练模型 |
82.06 |
|
|
9.7 M |
基于PP-OCRv3识别模型训练得到的超轻量繁体中文识别模型,支持繁体中文、数字识别 |
| te_PP-OCRv3_mobile_rec | 推理模型/训练模型 |
95.88 |
|
|
7.8 M |
基于PP-OCRv3识别模型训练得到的超轻量泰卢固文识别模型,支持泰卢固文、数字识别 |
| ka_PP-OCRv3_mobile_rec | 推理模型/训练模型 |
96.96 |
|
|
8.0 M |
基于PP-OCRv3识别模型训练得到的超轻量卡纳达文识别模型,支持卡纳达文、数字识别 |
| ta_PP-OCRv3_mobile_rec | 推理模型/训练模型 |
76.83 |
|
|
8.0 M |
基于PP-OCRv3识别模型训练得到的超轻量泰米尔文识别模型,支持泰米尔文、数字识别 |
| latin_PP-OCRv3_mobile_rec | 推理模型/训练模型 |
76.93 |
|
|
7.8 M |
基于PP-OCRv3识别模型训练得到的超轻量拉丁文识别模型,支持拉丁文、数字识别 |
| arabic_PP-OCRv3_mobile_rec | 推理模型/训练模型 |
73.55 |
|
|
7.8 M |
基于PP-OCRv3识别模型训练得到的超轻量阿拉伯字母识别模型,支持阿拉伯字母、数字识别 |
| cyrillic_PP-OCRv3_mobile_rec | 推理模型/训练模型 |
94.28 |
|
|
7.9 M |
基于PP-OCRv3识别模型训练得到的超轻量斯拉夫字母识别模型,支持斯拉夫字母、数字识别 |
| devanagari_PP-OCRv3_mobile_rec | 推理模型/训练模型 |
96.44 |
|
|
7.9 M |
基于PP-OCRv3识别模型训练得到的超轻量梵文字母识别模型,支持梵文字母、数字识别 |
注:以上精度指标的评估集是 PaddleX 自建的多语种数据集。 所有模型 GPU 推理耗时基于 NVIDIA Tesla T4 机器,精度类型为 FP32, CPU 推理速度基于 Intel(R) Xeon(R) Gold 5117 CPU @ 2.00GHz,线程数为8,精度类型为 FP32。
 相关方法、参数等说明如下:
* `create_model`实例化文本识别模型(此处以`PP-OCRv4_mobile_rec`为例),具体说明如下:
相关方法、参数等说明如下:
* `create_model`实例化文本识别模型(此处以`PP-OCRv4_mobile_rec`为例),具体说明如下:
| 参数 |
参数说明 |
参数类型 |
可选项 |
默认值 |
model_name |
模型名称 |
str |
所有PaddleX支持的模型名称 |
无 |
model_dir |
模型存储路径 |
str |
无 |
无 |
* 其中,`model_name` 必须指定,指定 `model_name` 后,默认使用 PaddleX 内置的模型参数,在此基础上,指定 `model_dir` 时,使用用户自定义的模型。
* 调用文本识别模型的 `predict()` 方法进行推理预测,`predict()` 方法参数有 `input` 和 `batch_size`,具体说明如下:
| 参数 |
参数说明 |
参数类型 |
可选项 |
默认值 |
input |
待预测数据,支持多种输入类型 |
Python Var/str/dict/list |
- Python变量,如
numpy.ndarray表示的图像数据
- 文件路径,如图像文件的本地路径:
/root/data/img.jpg
- URL链接,如图像文件的网络URL:示例
- 本地目录,该目录下需包含待预测数据文件,如本地路径:
/root/data/
- 字典,字典的
key需与具体任务对应,如图像分类任务对应\"img\",字典的val支持上述类型数据,例如:{\"img\": \"/root/data1\"}
- 列表,列表元素需为上述类型数据,如
[numpy.ndarray, numpy.ndarray],[\"/root/data/img1.jpg\", \"/root/data/img2.jpg\"],[\"/root/data1\", \"/root/data2\"],[{\"img\": \"/root/data1\"}, {\"img\": \"/root/data2/img.jpg\"}]
|
无 |
batch_size |
批大小 |
int |
任意整数 |
1 |
* 对预测结果进行处理,每个样本的预测结果均为`dict`类型,且支持打印、保存为图片、保存为`json`文件的操作:
| 方法 |
方法说明 |
参数 |
参数类型 |
参数说明 |
默认值 |
print() |
打印结果到终端 |
format_json |
bool |
是否对输出内容进行使用 JSON 缩进格式化 |
True |
indent |
int |
指定缩进级别,以美化输出的 JSON 数据,使其更具可读性,仅当 format_json 为 True 时有效 |
4 |
ensure_ascii |
bool |
控制是否将非 ASCII 字符转义为 Unicode。设置为 True 时,所有非 ASCII 字符将被转义;False 则保留原始字符,仅当format_json为True时有效 |
False |
save_to_json() |
将结果保存为json格式的文件 |
save_path |
str |
保存的文件路径,当为目录时,保存文件命名与输入文件类型命名一致 |
无 |
indent |
int |
指定缩进级别,以美化输出的 JSON 数据,使其更具可读性,仅当 format_json 为 True 时有效 |
4 |
ensure_ascii |
bool |
控制是否将非 ASCII 字符转义为 Unicode。设置为 True 时,所有非 ASCII 字符将被转义;False 则保留原始字符,仅当format_json为True时有效 |
False |
save_to_img() |
将结果保存为图像格式的文件 |
save_path |
str |
保存的文件路径,当为目录时,保存文件命名与输入文件类型命名一致 |
无 |
* 此外,也支持通过属性获取带结果的可视化图像和预测结果,具体如下:
| 属性 |
属性说明 |
json |
获取预测的json格式的结果 |
img |
获取格式为dict的可视化图像 |
关于更多 PaddleX 的单模型推理的 API 的使用方法,可以参考[PaddleX单模型Python脚本使用说明](../../instructions/model_python_API.md)。
## 四、二次开发
如果你追求更高精度的现有模型,可以使用 PaddleX 的二次开发能力,开发更好的文本识别模型。在使用 PaddleX 开发文本识别模型之前,请务必安装 PaddleX 的 OCR 相关模型训练插件,安装过程可以参考[PaddleX本地安装教程](../../../installation/installation.md)中的二次开发部分。
### 4.1 数据准备
在进行模型训练前,需要准备相应任务模块的数据集。PaddleX 针对每一个模块提供了数据校验功能,只有通过数据校验的数据才可以进行模型训练。此外,PaddleX 为每一个模块都提供了 Demo 数据集,您可以基于官方提供的 Demo 数据完成后续的开发。若您希望用私有数据集进行后续的模型训练,可以参考[PaddleX文本检测/文本识别任务模块数据标注教程](../../../data_annotations/ocr_modules/text_detection_recognition.md)。
#### 4.1.1 Demo 数据下载
您可以参考下面的命令将 Demo 数据集下载到指定文件夹:
```bash
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/ocr_rec_dataset_examples.tar -P ./dataset
tar -xf ./dataset/ocr_rec_dataset_examples.tar -C ./dataset/
```
#### 4.1.2 数据校验
一行命令即可完成数据校验:
```bash
python main.py -c paddlex/configs/text_recognition/PP-OCRv4_mobile_rec.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/ocr_rec_dataset_examples
```
执行上述命令后,PaddleX 会对数据集进行校验,并统计数据集的基本信息,命令运行成功后会在log中打印出`Check dataset passed !`信息。校验结果文件保存在`./output/check_dataset_result.json`,同时相关产出会保存在当前目录的`./output/check_dataset`目录下,产出目录中包括可视化的示例样本图片和样本分布直方图。
👉 校验结果详情(点击展开)
校验结果文件具体内容为:
{
"done_flag": true,
"check_pass": true,
"attributes": {
"train_samples": 4468,
"train_sample_paths": [
"../dataset/ocr_rec_dataset_examples/images/train_word_1.png",
"../dataset/ocr_rec_dataset_examples/images/train_word_10.png"
],
"val_samples": 2077,
"val_sample_paths": [
"../dataset/ocr_rec_dataset_examples/images/val_word_1.png",
"../dataset/ocr_rec_dataset_examples/images/val_word_10.png"
]
},
"analysis": {
"histogram": "check_dataset/histogram.png"
},
"dataset_path": "./dataset/ocr_rec_dataset_examples",
"show_type": "image",
"dataset_type": "MSTextRecDataset"
}
上述校验结果中,check_pass 为 true 表示数据集格式符合要求,其他部分指标的说明如下:
attributes.train_samples:该数据集训练集样本数量为 4468;attributes.val_samples:该数据集验证集样本数量为 2077;attributes.train_sample_paths:该数据集训练集样本可视化图片相对路径列表;attributes.val_sample_paths:该数据集验证集样本可视化图片相对路径列表;
另外,数据集校验还对数据集中所有字符长度占比的分布情况进行了分析,并绘制了分布直方图(histogram.png):
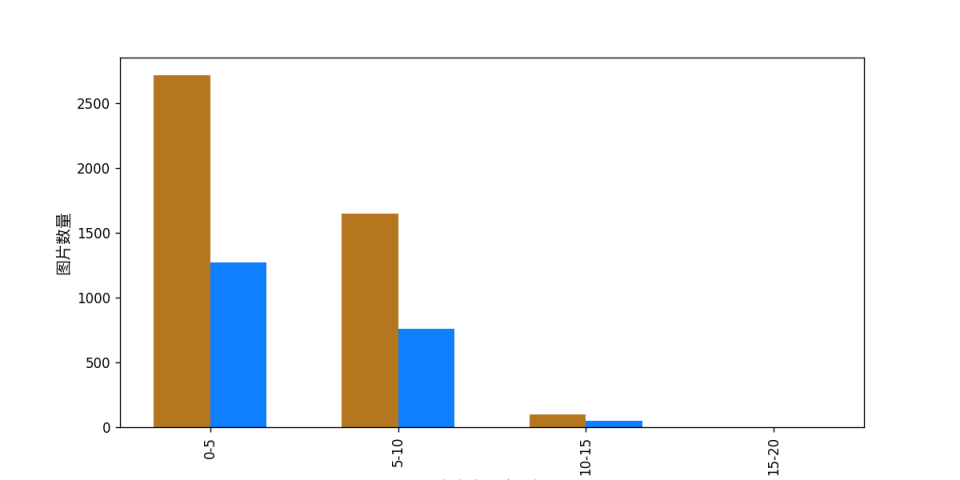
👉 格式转换/数据集划分详情(点击展开)
(1)数据集格式转换
文本识别暂不支持数据转换。
(2)数据集划分
数据集划分的参数可以通过修改配置文件中 CheckDataset 下的字段进行设置,配置文件中部分参数的示例说明如下:
CheckDataset:split:enable: 是否进行重新划分数据集,为 True 时进行数据集格式转换,默认为 False;train_percent: 如果重新划分数据集,则需要设置训练集的百分比,类型为0-100之间的任意整数,需要保证和 val_percent 值加和为100;
例如,您想重新划分数据集为 训练集占比90%、验证集占比10%,则需将配置文件修改为:
......
CheckDataset:
......
split:
enable: True
train_percent: 90
val_percent: 10
......
随后执行命令:
python main.py -c paddlex/configs/text_recognition/PP-OCRv4_mobile_rec.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/ocr_rec_dataset_examples
数据划分执行之后,原有标注文件会被在原路径下重命名为 xxx.bak。
以上参数同样支持通过追加命令行参数的方式进行设置:
python main.py -c paddlex/configs/text_recognition/PP-OCRv4_mobile_rec.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/ocr_rec_dataset_examples \
-o CheckDataset.split.enable=True \
-o CheckDataset.split.train_percent=90 \
-o CheckDataset.split.val_percent=10
👉 更多说明(点击展开)
👉 更多说明(点击展开)
在模型评估时,需要指定模型权重文件路径,每个配置文件中都内置了默认的权重保存路径,如需要改变,只需要通过追加命令行参数的形式进行设置即可,如-o Evaluate.weight_path=./output/best_accuracy/best_accuracy.pdparams。
在完成模型评估后,通常有以下产出:evaluate_result.json,其记录了评估的结果,具体来说,记录了评估任务是否正常完成,以及模型的评估指标,包含 acc、norm_edit_dis;
{kind=link}