 行人属性识别产线中包含了行人检测模块和行人属性识别模块,每个模块中包含了若干模型,具体使用哪些模型,您可以根据下边的 benchmark 数据来选择。如您更考虑模型精度,请选择精度较高的模型,如您更考虑模型推理速度,请选择推理速度较快的模型,如您更考虑模型存储大小,请选择存储大小较小的模型。
行人属性识别产线中包含了行人检测模块和行人属性识别模块,每个模块中包含了若干模型,具体使用哪些模型,您可以根据下边的 benchmark 数据来选择。如您更考虑模型精度,请选择精度较高的模型,如您更考虑模型推理速度,请选择推理速度较快的模型,如您更考虑模型存储大小,请选择存储大小较小的模型。
行人检测模块:
| 模型 | 模型下载链接 | mAP(0.5:0.95) | mAP(0.5) | GPU推理耗时(ms) [常规模式 / 高性能模式] |
CPU推理耗时(ms) [常规模式 / 高性能模式] |
模型存储大小(M) | 介绍 |
|---|---|---|---|---|---|---|---|
| PP-YOLOE-L_human | 推理模型/训练模型 | 48.0 | 81.9 | 33.27 / 9.19 | 173.72 / 173.72 | 196.02 | 基于PP-YOLOE的行人检测模型 |
| PP-YOLOE-S_human | 推理模型/训练模型 | 42.5 | 77.9 | 9.94 / 3.42 | 54.48 / 46.52 | 28.79 |
行人属性识别模块:
| 模型 | 模型下载链接 | mAP(%) | GPU推理耗时(ms) [常规模式 / 高性能模式] |
CPU推理耗时(ms) [常规模式 / 高性能模式] |
模型存储大小(M) | 介绍 |
|---|---|---|---|---|---|---|
| PP-LCNet_x1_0_pedestrian_attribute | 推理模型/训练模型 | 92.2 | 2.35 / 0.49 | 3.17 / 1.25 | 6.7 M | PP-LCNet_x1_0_pedestrian_attribute 是一种基于PP-LCNet的轻量级行人属性识别模型,包含26个类别 |
| 模式 | GPU配置 | CPU配置 | 加速技术组合 |
|---|---|---|---|
| 常规模式 | FP32精度 / 无TRT加速 | FP32精度 / 8线程 | PaddleInference |
| 高性能模式 | 选择先验精度类型和加速策略的最优组合 | FP32精度 / 8线程 | 选择先验最优后端(Paddle/OpenVINO/TRT等) |
 如果您对产线运行的效果满意,可以直接进行集成部署。您可以选择从云端下载部署包,也可以参考[2.2节本地体验](#22-本地体验)中的方法进行本地部署。如果对效果不满意,您可以利用私有数据对产线中的模型进行微调训练。如果您具备本地训练的硬件资源,可以直接在本地开展训练;如果没有,星河零代码平台提供了一键式训练服务,无需编写代码,只需上传数据后,即可一键启动训练任务。
### 2.2 本地体验
在本地使用行人属性识别产线前,请确保您已经按照[PaddleX本地安装教程](../../../installation/installation.md)完成了PaddleX的wheel包安装。如果您希望选择性安装依赖,请参考安装教程中的相关说明。该产线对应的依赖分组为 `cv`。
#### 2.2.1 命令行方式体验
一行命令即可快速体验行人属性识别产线效果,使用 [测试文件](https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/pedestrian_attribute_002.jpg),并将 `--input` 替换为本地路径,进行预测
```bash
paddlex --pipeline pedestrian_attribute_recognition --input pedestrian_attribute_002.jpg --device gpu:0 --save_path ./output/
```
相关的参数说明可以参考[2.2.2 Python脚本方式集成](#222-python脚本方式集成)中的参数说明。
运行后,会将结果打印到终端上,结果如下:
```bash
{'res': {'input_path': 'pedestrian_attribute_002.jpg', 'boxes': [{'labels': ['Trousers(长裤)', 'Age18-60(年龄在18-60岁之间)', 'LongCoat(长外套)', 'Side(侧面)'], 'cls_scores': array([0.99965, 0.99963, 0.98866, 0.9624 ]), 'det_score': 0.9795178771018982, 'coordinate': [87.24581, 322.5872, 546.2697, 1039.9852]}, {'labels': ['Trousers(长裤)', 'LongCoat(长外套)', 'Front(面朝前)', 'Age18-60(年龄在18-60岁之间)'], 'cls_scores': array([0.99996, 0.99872, 0.93379, 0.71614]), 'det_score': 0.967143177986145, 'coordinate': [737.91626, 306.287, 1150.5961, 1034.2979]}, {'labels': ['Trousers(长裤)', 'LongCoat(长外套)', 'Age18-60(年龄在18-60岁之间)', 'Side(侧面)'], 'cls_scores': array([0.99996, 0.99514, 0.98726, 0.96224]), 'det_score': 0.9645745754241943, 'coordinate': [399.45944, 281.9107, 869.5312, 1038.9962]}]}}
```
运行结果参数说明可以参考[2.2.2 Python脚本方式集成](#222-python脚本方式集成)中的结果解释。
可视化结果保存在`save_path`下,可视化结果如下:
如果您对产线运行的效果满意,可以直接进行集成部署。您可以选择从云端下载部署包,也可以参考[2.2节本地体验](#22-本地体验)中的方法进行本地部署。如果对效果不满意,您可以利用私有数据对产线中的模型进行微调训练。如果您具备本地训练的硬件资源,可以直接在本地开展训练;如果没有,星河零代码平台提供了一键式训练服务,无需编写代码,只需上传数据后,即可一键启动训练任务。
### 2.2 本地体验
在本地使用行人属性识别产线前,请确保您已经按照[PaddleX本地安装教程](../../../installation/installation.md)完成了PaddleX的wheel包安装。如果您希望选择性安装依赖,请参考安装教程中的相关说明。该产线对应的依赖分组为 `cv`。
#### 2.2.1 命令行方式体验
一行命令即可快速体验行人属性识别产线效果,使用 [测试文件](https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/pedestrian_attribute_002.jpg),并将 `--input` 替换为本地路径,进行预测
```bash
paddlex --pipeline pedestrian_attribute_recognition --input pedestrian_attribute_002.jpg --device gpu:0 --save_path ./output/
```
相关的参数说明可以参考[2.2.2 Python脚本方式集成](#222-python脚本方式集成)中的参数说明。
运行后,会将结果打印到终端上,结果如下:
```bash
{'res': {'input_path': 'pedestrian_attribute_002.jpg', 'boxes': [{'labels': ['Trousers(长裤)', 'Age18-60(年龄在18-60岁之间)', 'LongCoat(长外套)', 'Side(侧面)'], 'cls_scores': array([0.99965, 0.99963, 0.98866, 0.9624 ]), 'det_score': 0.9795178771018982, 'coordinate': [87.24581, 322.5872, 546.2697, 1039.9852]}, {'labels': ['Trousers(长裤)', 'LongCoat(长外套)', 'Front(面朝前)', 'Age18-60(年龄在18-60岁之间)'], 'cls_scores': array([0.99996, 0.99872, 0.93379, 0.71614]), 'det_score': 0.967143177986145, 'coordinate': [737.91626, 306.287, 1150.5961, 1034.2979]}, {'labels': ['Trousers(长裤)', 'LongCoat(长外套)', 'Age18-60(年龄在18-60岁之间)', 'Side(侧面)'], 'cls_scores': array([0.99996, 0.99514, 0.98726, 0.96224]), 'det_score': 0.9645745754241943, 'coordinate': [399.45944, 281.9107, 869.5312, 1038.9962]}]}}
```
运行结果参数说明可以参考[2.2.2 Python脚本方式集成](#222-python脚本方式集成)中的结果解释。
可视化结果保存在`save_path`下,可视化结果如下:
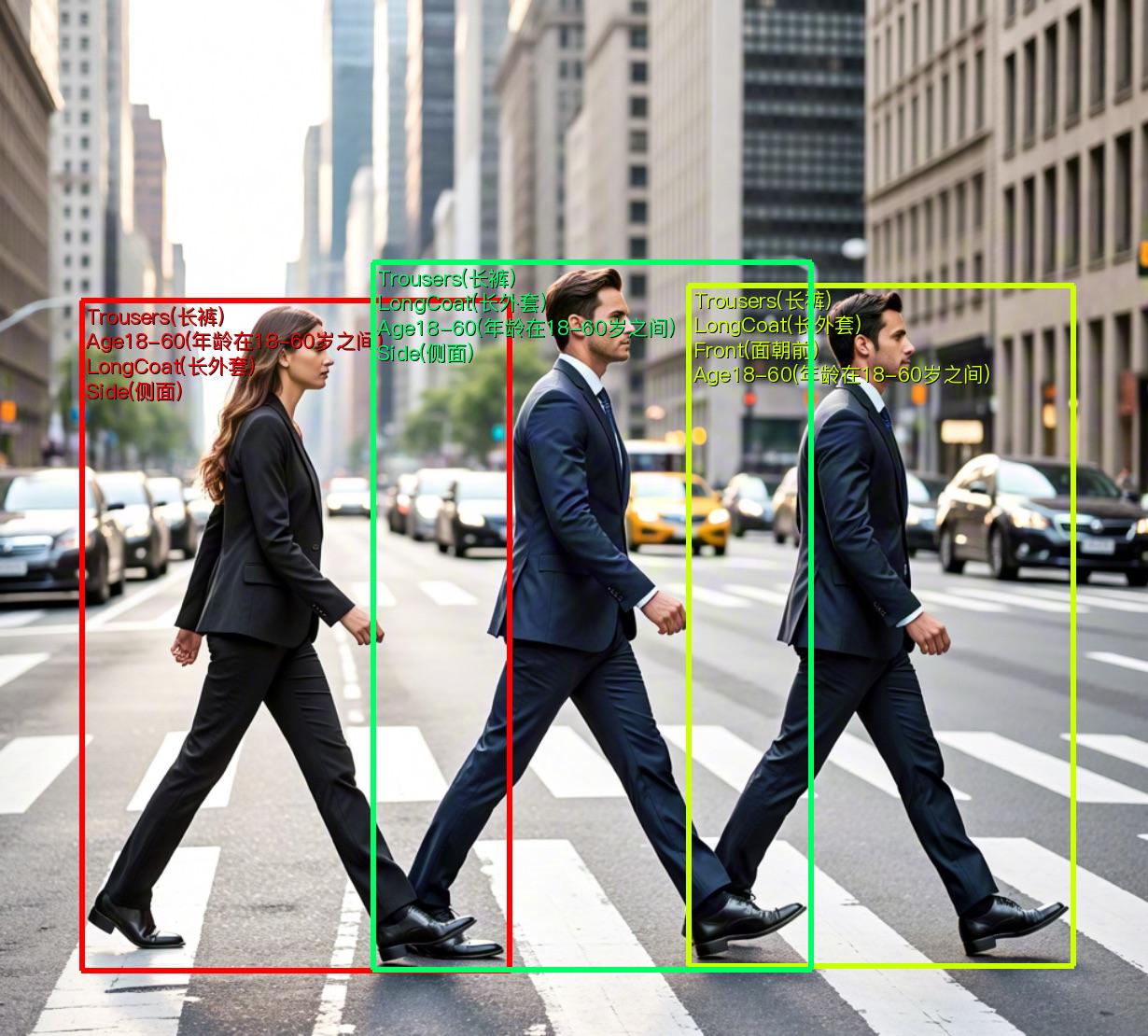 #### 2.2.2 Python脚本方式集成
* 上述命令行是为了快速体验查看效果,一般来说,在项目中,往往需要通过代码集成,您可以通过几行代码即可完成产线的快速推理,推理代码如下:
```python
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="pedestrian_attribute_recognition")
output = pipeline.predict("pedestrian_attribute_002.jpg")
for res in output:
res.print() ## 打印预测的结构化输出
res.save_to_img("./output/") ## 保存结果可视化图像
res.save_to_json("./output/") ## 保存预测的结构化输出
```
得到的结果与命令行方式相同。
在上述 Python 脚本中,执行了如下几个步骤:
(1)通过 `create_pipeline()` 实例化行人属性识别产线对象,具体参数说明如下:
#### 2.2.2 Python脚本方式集成
* 上述命令行是为了快速体验查看效果,一般来说,在项目中,往往需要通过代码集成,您可以通过几行代码即可完成产线的快速推理,推理代码如下:
```python
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="pedestrian_attribute_recognition")
output = pipeline.predict("pedestrian_attribute_002.jpg")
for res in output:
res.print() ## 打印预测的结构化输出
res.save_to_img("./output/") ## 保存结果可视化图像
res.save_to_json("./output/") ## 保存预测的结构化输出
```
得到的结果与命令行方式相同。
在上述 Python 脚本中,执行了如下几个步骤:
(1)通过 `create_pipeline()` 实例化行人属性识别产线对象,具体参数说明如下:
| 参数 | 参数说明 | 参数类型 | 默认值 | |
|---|---|---|---|---|
pipeline |
产线名称或是产线配置文件路径。如为产线名称,则必须为 PaddleX 所支持的产线。 | str |
None | |
config |
产线具体的配置信息(如果和pipeline同时设置,优先级高于pipeline,且要求产线名和pipeline一致)。 |
dict[str, Any] |
None |
|
device |
产线推理设备。支持指定GPU具体卡号,如“gpu:0”,其他硬件具体卡号,如“npu:0”,CPU如“cpu”。 | str |
gpu:0 |
|
use_hpip |
是否启用高性能推理插件。如果为 None,则使用配置文件或 config 中的配置。 |
bool | None |
无 | None |
hpi_config |
高性能推理配置 | dict | None |
无 | None |
| 参数 | 参数说明 | 参数类型 | 可选项 | 默认值 |
|---|---|---|---|---|
input |
待预测数据,支持多种输入类型,必填 | Python Var|str|list |
|
None |
device |
产线推理设备 | str|None |
|
None |
det_threshold |
行人检测可视化阈值 | float | None |
|
0.5 |
cls_threshold |
行人属性预测阈值 | float | dict | list| None |
|
0.7 |
| 方法 | 方法说明 | 参数 | 参数类型 | 参数说明 | 默认值 |
|---|---|---|---|---|---|
print() |
打印结果到终端 | format_json |
bool |
是否对输出内容进行使用 JSON 缩进格式化 |
True |
indent |
int |
指定缩进级别,以美化输出的 JSON 数据,使其更具可读性,仅当 format_json 为 True 时有效 |
4 | ||
ensure_ascii |
bool |
控制是否将非 ASCII 字符转义为 Unicode。设置为 True 时,所有非 ASCII 字符将被转义;False 则保留原始字符,仅当format_json为True时有效 |
False |
||
save_to_json() |
将结果保存为json格式的文件 | save_path |
str |
保存的文件路径,当为目录时,保存文件命名与输入文件类型命名一致 | 无 |
indent |
int |
指定缩进级别,以美化输出的 JSON 数据,使其更具可读性,仅当 format_json 为 True 时有效 |
4 | ||
ensure_ascii |
bool |
控制是否将非 ASCII 字符转义为 Unicode。设置为 True 时,所有非 ASCII 字符将被转义;False 则保留原始字符,仅当format_json为True时有效 |
False |
||
save_to_img() |
将结果保存为图像格式的文件 | save_path |
str |
保存的文件路径,支持目录或文件路径 | 无 |
| 属性 | 属性说明 |
|---|---|
json |
获取预测的 json 格式的结果 |
img |
获取格式为 dict 的可视化图像 |
对于服务提供的主要操作:
200,响应体的属性如下:| 名称 | 类型 | 含义 |
|---|---|---|
logId |
string |
请求的UUID。 |
errorCode |
integer |
错误码。固定为0。 |
errorMsg |
string |
错误说明。固定为"Success"。 |
result |
object |
操作结果。 |
| 名称 | 类型 | 含义 |
|---|---|---|
logId |
string |
请求的UUID。 |
errorCode |
integer |
错误码。与响应状态码相同。 |
errorMsg |
string |
错误说明。 |
服务提供的主要操作如下:
infer获取行人属性识别结果。
POST /pedestrian-attribute-recognition
| 名称 | 类型 | 含义 | 是否必填 |
|---|---|---|---|
image |
string |
服务器可访问的图像文件的URL或图像文件内容的Base64编码结果。 | 是 |
detThreshold |
number | null |
请参阅产线对象中 predict 方法的 det_threshold 参数相关说明。 |
否 |
clsThreshold |
number | array | object | null |
请参阅产线对象中 predict 方法的 cls_threshold 参数相关说明。 |
否 |
result具有如下属性:| 名称 | 类型 | 含义 |
|---|---|---|
pedestrians |
array |
行人的位置及属性等信息。 |
image |
string | null |
行人属性识别结果图。图像为JPEG格式,使用Base64编码。 |
pedestrians中的每个元素为一个object,具有如下属性:
| 名称 | 类型 | 含义 |
|---|---|---|
bbox |
array |
行人位置。数组中元素依次为边界框左上角x坐标、左上角y坐标、右下角x坐标以及右下角y坐标。 |
attributes |
array |
行人属性。 |
score |
number |
检测得分。 |
attributes中的每个元素为一个object,具有如下属性:
| 名称 | 类型 | 含义 |
|---|---|---|
label |
string |
属性标签。 |
score |
number |
分类得分。 |
import base64
import requests
API_URL = "http://localhost:8080/pedestrian-attribute-recognition" # 服务URL
image_path = "./demo.jpg"
output_image_path = "./out.jpg"
# 对本地图像进行Base64编码
with open(image_path, "rb") as file:
image_bytes = file.read()
image_data = base64.b64encode(image_bytes).decode("ascii")
payload = {"image": image_data} # Base64编码的文件内容或者图像URL
# 调用API
response = requests.post(API_URL, json=payload)
# 处理接口返回数据
assert response.status_code == 200
result = response.json()["result"]
with open(output_image_path, "wb") as file:
file.write(base64.b64decode(result["image"]))
print(f"Output image saved at {output_image_path}")
print("\nDetected pedestrians:")
print(result["pedestrians"])
| 情形 | 微调模块 | 微调参考链接 |
|---|---|---|
| 行人检测不准 | 行人检测模块 | 链接 |
| 属性识别不准 | 行人属性识别模块 | 链接 |
{kind=link}