| Processor Architecture | Operating System | Device Type | Python Version | Installation Command |
|---|---|---|---|---|
| x86-64 | Linux | CPU | ||
| 3.8 | curl -s https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/deploy/paddlex_hpi/install_script/latest/install_paddlex_hpi.py | python3.8 - --arch x86_64 --os linux --device cpu --py 38 | |||
| 3.9 | curl -s https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/deploy/paddlex_hpi/install_script/latest/install_paddlex_hpi.py | python3.9 - --arch x86_64 --os linux --device cpu --py 39 | |||
| 3.10 | curl -s https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/deploy/paddlex_hpi/install_script/latest/install_paddlex_hpi.py | python3.10 - --arch x86_64 --os linux --device cpu --py 310 | |||
| GPU (CUDA 11.8 + cuDNN 8.6) | 3.8 | curl -s https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/deploy/paddlex_hpi/install_script/latest/install_paddlex_hpi.py | python3.8 - --arch x86_64 --os linux --device gpu_cuda118_cudnn86 --py 38 | ||
| 3.9 | curl -s https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/deploy/paddlex_hpi/install_script/latest/install_paddlex_hpi.py | python3.9 - --arch x86_64 --os linux --device gpu_cuda118_cudnn86 --py 39 | |||
| 3.10 | curl -s https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/deploy/paddlex_hpi/install_script/latest/install_paddlex_hpi.py | python3.10 - --arch x86_64 --os linux --device gpu_cuda118_cudnn86 --py 310 |
 Select the pipeline you wish to deploy and click "Acquire". Afterwards, you can find the acquired serial number in the "Open-source Pipeline Deployment SDK Serial Number Management" section at the bottom of the page:
Select the pipeline you wish to deploy and click "Acquire". Afterwards, you can find the acquired serial number in the "Open-source Pipeline Deployment SDK Serial Number Management" section at the bottom of the page:
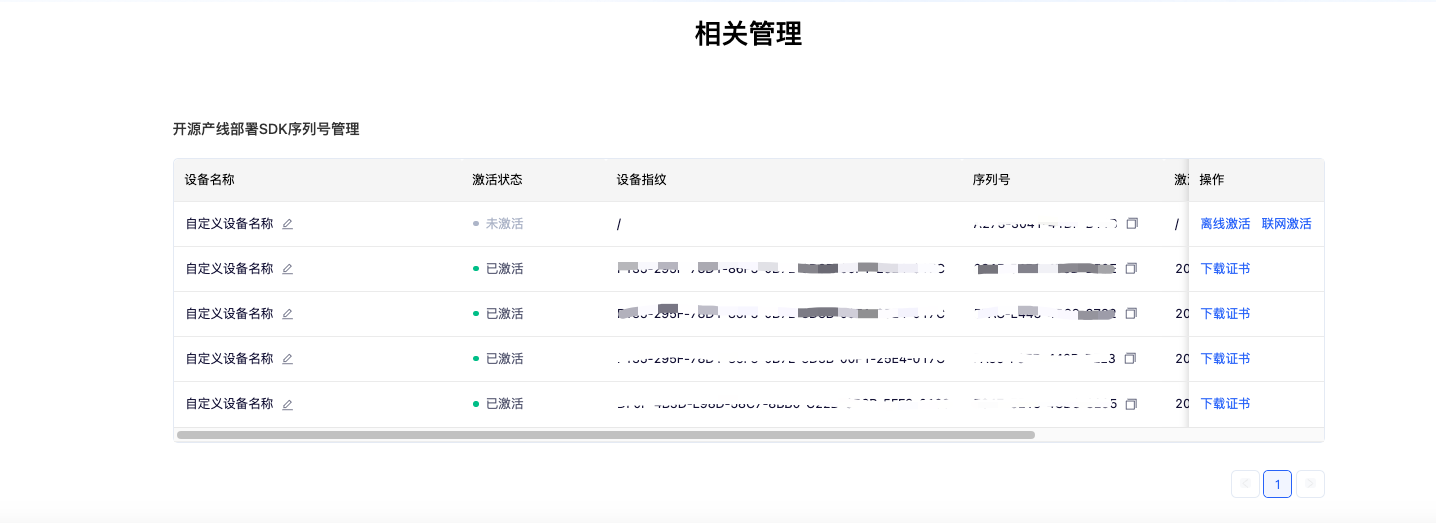 After using the serial number to complete activation, you can utilize high-performance inference plugins. PaddleX provides both online and offline activation methods (both only support Linux systems):
* Online Activation: When using the inference API or CLI, specify the serial number and enable online activation to automatically complete the process.
* Offline Activation: Follow the instructions in the serial number management interface (click "Offline Activation" under "Operations") to obtain the device fingerprint of your machine. Bind the serial number with the device fingerprint to obtain a certificate and complete the activation. For this activation method, you need to manually store the certificate in the `${HOME}/.baidu/paddlex/licenses` directory on the machine (create the directory if it does not exist) and specify the serial number when using the inference API or CLI.
Please note: Each serial number can only be bound to a unique device fingerprint and can only be bound once. This means that if users deploy models on different machines, they must prepare separate serial numbers for each machine.
### 1.3 Enabling High-Performance Inference Plugins
Before enabling high-performance plugins, please ensure that the `LD_LIBRARY_PATH` of the current environment does not specify the TensorRT directory, as the plugins already integrate TensorRT to avoid conflicts caused by different TensorRT versions that may prevent the plugins from functioning properly.
For PaddleX CLI, specify `--use_hpip` and set the serial number to enable the high-performance inference plugin. If you wish to activate the license online, specify `--update_license` when using the serial number for the first time. Taking the general image classification pipeline as an example:
```diff
paddlex \
--pipeline image_classification \
--input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_image_classification_001.jpg \
--device gpu:0 \
+ --use_hpip \
+ --serial_number {serial_number}
# If you wish to activate the license online
paddlex \
--pipeline image_classification \
--input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_image_classification_001.jpg \
--device gpu:0 \
+ --use_hpip \
+ --serial_number {serial_number} \
+ --update_license
```
For PaddleX Python API, enabling the high-performance inference plugin is similar. Still taking the general image classification pipeline as an example:
```diff
from paddlex import create_pipeline
pipeline = create_pipeline(
pipeline="image_classification",
+ use_hpip=True,
+ serial_number="{serial_number}",
)
output = pipeline.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_image_classification_001.jpg")
```
The inference results obtained with the high-performance inference plugin enabled are consistent with those without the plugin enabled. For some models, enabling the high-performance inference plugin for the first time may take a longer time to complete the construction of the inference engine. PaddleX will cache the relevant information in the model directory after the first construction of the inference engine and reuse the cached content in subsequent runs to improve initialization speed.
### 1.4 Modifying High-Performance Inference Configurations
PaddleX provides default high-performance inference configurations for each model and stores them in the model's configuration file. Due to the diversity of actual deployment environments, using the default configurations may not achieve ideal performance in specific environments or may even result in inference failures. For situations where the default configurations cannot meet requirements, you can try changing the model's inference backend as follows:
1. Locate the `inference.yml` file in the model directory and find the `Hpi` field.
2. Modify the value of `selected_backends`. Specifically, `selected_backends` may be set as follows:
```yaml
selected_backends:
cpu: paddle_infer
gpu: onnx_runtime
```
Each entry is formatted as `{device_type}: {inference_backend_name}`. The default selects the backend with the shortest inference time in the official test environment. `supported_backends` lists the inference backends supported by the model in the official test environment for reference.
The currently available inference backends are:
* `paddle_infer`: The standard Paddle Inference engine. Supports CPU and GPU.
* `paddle_tensorrt`: [Paddle-TensorRT](https://www.paddlepaddle.org.cn/lite/v2.10/optimize/paddle_trt.html), a high-performance deep learning inference library produced by Paddle, which integrates TensorRT in the form of subgraphs for further optimization and acceleration. Supports GPU only.
* `openvino`: [OpenVINO](https://github.com/openvinotoolkit/openvino), a deep learning inference tool provided by Intel, optimized for model inference performance on various Intel hardware. Supports CPU only.
* `onnx_runtime`: [ONNX Runtime](https://onnxruntime.ai/), a cross-platform, high-performance inference engine. Supports CPU and GPU.
* `tensorrt`: [TensorRT](https://developer.nvidia.com/tensorrt), a high-performance deep learning inference library provided by NVIDIA, optimized for NVIDIA GPUs to improve speed. Supports GPU only.
Here are some key details of the current official test environment:
* CPU: Intel Xeon Gold 5117
* GPU: NVIDIA Tesla T4
* CUDA Version: 11.8
* cuDNN Version: 8.6
* Docker:registry.baidubce.com/paddlepaddle/paddle:latest-dev-cuda11.8-cudnn8.6-trt8.5-gcc82
## 2. Pipelines and Models Supporting High-Performance Inference Plugins
After using the serial number to complete activation, you can utilize high-performance inference plugins. PaddleX provides both online and offline activation methods (both only support Linux systems):
* Online Activation: When using the inference API or CLI, specify the serial number and enable online activation to automatically complete the process.
* Offline Activation: Follow the instructions in the serial number management interface (click "Offline Activation" under "Operations") to obtain the device fingerprint of your machine. Bind the serial number with the device fingerprint to obtain a certificate and complete the activation. For this activation method, you need to manually store the certificate in the `${HOME}/.baidu/paddlex/licenses` directory on the machine (create the directory if it does not exist) and specify the serial number when using the inference API or CLI.
Please note: Each serial number can only be bound to a unique device fingerprint and can only be bound once. This means that if users deploy models on different machines, they must prepare separate serial numbers for each machine.
### 1.3 Enabling High-Performance Inference Plugins
Before enabling high-performance plugins, please ensure that the `LD_LIBRARY_PATH` of the current environment does not specify the TensorRT directory, as the plugins already integrate TensorRT to avoid conflicts caused by different TensorRT versions that may prevent the plugins from functioning properly.
For PaddleX CLI, specify `--use_hpip` and set the serial number to enable the high-performance inference plugin. If you wish to activate the license online, specify `--update_license` when using the serial number for the first time. Taking the general image classification pipeline as an example:
```diff
paddlex \
--pipeline image_classification \
--input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_image_classification_001.jpg \
--device gpu:0 \
+ --use_hpip \
+ --serial_number {serial_number}
# If you wish to activate the license online
paddlex \
--pipeline image_classification \
--input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_image_classification_001.jpg \
--device gpu:0 \
+ --use_hpip \
+ --serial_number {serial_number} \
+ --update_license
```
For PaddleX Python API, enabling the high-performance inference plugin is similar. Still taking the general image classification pipeline as an example:
```diff
from paddlex import create_pipeline
pipeline = create_pipeline(
pipeline="image_classification",
+ use_hpip=True,
+ serial_number="{serial_number}",
)
output = pipeline.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_image_classification_001.jpg")
```
The inference results obtained with the high-performance inference plugin enabled are consistent with those without the plugin enabled. For some models, enabling the high-performance inference plugin for the first time may take a longer time to complete the construction of the inference engine. PaddleX will cache the relevant information in the model directory after the first construction of the inference engine and reuse the cached content in subsequent runs to improve initialization speed.
### 1.4 Modifying High-Performance Inference Configurations
PaddleX provides default high-performance inference configurations for each model and stores them in the model's configuration file. Due to the diversity of actual deployment environments, using the default configurations may not achieve ideal performance in specific environments or may even result in inference failures. For situations where the default configurations cannot meet requirements, you can try changing the model's inference backend as follows:
1. Locate the `inference.yml` file in the model directory and find the `Hpi` field.
2. Modify the value of `selected_backends`. Specifically, `selected_backends` may be set as follows:
```yaml
selected_backends:
cpu: paddle_infer
gpu: onnx_runtime
```
Each entry is formatted as `{device_type}: {inference_backend_name}`. The default selects the backend with the shortest inference time in the official test environment. `supported_backends` lists the inference backends supported by the model in the official test environment for reference.
The currently available inference backends are:
* `paddle_infer`: The standard Paddle Inference engine. Supports CPU and GPU.
* `paddle_tensorrt`: [Paddle-TensorRT](https://www.paddlepaddle.org.cn/lite/v2.10/optimize/paddle_trt.html), a high-performance deep learning inference library produced by Paddle, which integrates TensorRT in the form of subgraphs for further optimization and acceleration. Supports GPU only.
* `openvino`: [OpenVINO](https://github.com/openvinotoolkit/openvino), a deep learning inference tool provided by Intel, optimized for model inference performance on various Intel hardware. Supports CPU only.
* `onnx_runtime`: [ONNX Runtime](https://onnxruntime.ai/), a cross-platform, high-performance inference engine. Supports CPU and GPU.
* `tensorrt`: [TensorRT](https://developer.nvidia.com/tensorrt), a high-performance deep learning inference library provided by NVIDIA, optimized for NVIDIA GPUs to improve speed. Supports GPU only.
Here are some key details of the current official test environment:
* CPU: Intel Xeon Gold 5117
* GPU: NVIDIA Tesla T4
* CUDA Version: 11.8
* cuDNN Version: 8.6
* Docker:registry.baidubce.com/paddlepaddle/paddle:latest-dev-cuda11.8-cudnn8.6-trt8.5-gcc82
## 2. Pipelines and Models Supporting High-Performance Inference Plugins
| Pipeline | Pipeline Module | Specific Models |
|---|---|---|
| General Image Classification | Image Classification | ResNet18 ResNet34 moreResNet50ResNet101ResNet152ResNet18_vdResNet34_vdResNet50_vdResNet101_vdResNet152_vdResNet200_vdPP-LCNet_x0_25PP-LCNet_x0_35PP-LCNet_x0_5PP-LCNet_x0_75PP-LCNet_x1_0PP-LCNet_x1_5PP-LCNet_x2_0PP-LCNet_x2_5PP-LCNetV2_smallPP-LCNetV2_basePP-LCNetV2_largeMobileNetV3_large_x0_35MobileNetV3_large_x0_5MobileNetV3_large_x0_75MobileNetV3_large_x1_0MobileNetV3_large_x1_25MobileNetV3_small_x0_35MobileNetV3_small_x0_5MobileNetV3_small_x0_75MobileNetV3_small_x1_0MobileNetV3_small_x1_25ConvNeXt_tinyConvNeXt_smallConvNeXt_base_224ConvNeXt_base_384ConvNeXt_large_224ConvNeXt_large_384MobileNetV1_x0_25MobileNetV1_x0_5MobileNetV1_x0_75MobileNetV1_x1_0MobileNetV2_x0_25MobileNetV2_x0_5MobileNetV2_x1_0MobileNetV2_x1_5MobileNetV2_x2_0SwinTransformer_tiny_patch4_window7_224SwinTransformer_small_patch4_window7_224SwinTransformer_base_patch4_window7_224SwinTransformer_base_patch4_window12_384SwinTransformer_large_patch4_window7_224SwinTransformer_large_patch4_window12_384PP-HGNet_smallPP-HGNet_tinyPP-HGNet_basePP-HGNetV2-B0PP-HGNetV2-B1PP-HGNetV2-B2PP-HGNetV2-B3PP-HGNetV2-B4PP-HGNetV2-B5PP-HGNetV2-B6CLIP_vit_base_patch16_224CLIP_vit_large_patch14_224 |
| General Object Detection | Object Detection | PP-YOLOE_plus-S PP-YOLOE_plus-M morePP-YOLOE_plus-LPP-YOLOE_plus-XYOLOX-NYOLOX-TYOLOX-SYOLOX-MYOLOX-LYOLOX-XYOLOv3-DarkNet53YOLOv3-ResNet50_vd_DCNYOLOv3-MobileNetV3RT-DETR-R18RT-DETR-R50RT-DETR-LRT-DETR-HRT-DETR-XPicoDet-SPicoDet-L |
| General Semantic Segmentation | Semantic Segmentation | Deeplabv3-R50 Deeplabv3-R101 moreDeeplabv3_Plus-R50Deeplabv3_Plus-R101PP-LiteSeg-TOCRNet_HRNet-W48OCRNet_HRNet-W18SeaFormer_tinySeaFormer_smallSeaFormer_baseSeaFormer_largeSegFormer-B0SegFormer-B1SegFormer-B2SegFormer-B3SegFormer-B4SegFormer-B5 |
| General Instance Segmentation | Instance Segmentation | Mask-RT-DETR-L Mask-RT-DETR-H |
| Seal Text Recognition | Layout Analysis | PicoDet-S_layout_3cls PicoDet-S_layout_17cls morePicoDet-L_layout_3clsPicoDet-L_layout_17clsRT-DETR-H_layout_3clsRT-DETR-H_layout_17cls |
| Seal Text Detection | PP-OCRv4_server_seal_det PP-OCRv4_mobile_seal_det |
|
| Text Recognition | PP-OCRv4_mobile_rec PP-OCRv4_server_rec |
|
| General OCR | Text Detection | PP-OCRv4_server_det PP-OCRv4_mobile_det |
| Text Recognition | PP-OCRv4_server_rec PP-OCRv4_mobile_rec ch_RepSVTR_rec ch_SVTRv2_rec |
|
| General Table Recognition | Layout Detection | PicoDet_layout_1x |
| Table Recognition | SLANet | |
| SLANet_plus | ||
| Text Detection | PP-OCRv4_server_det PP-OCRv4_mobile_det |
|
| Text Recognition | PP-OCRv4_server_rec PP-OCRv4_mobile_rec ch_RepSVTR_rec ch_SVTRv2_rec |
|
| Document Scene Information Extraction v3 | Table Recognition | SLANet |
| SLANet_plus | ||
| Layout Detection | PicoDet_layout_1x | |
| Text Detection | PP-OCRv4_server_det | |
| PP-OCRv4_mobile_det | ||
| Text Recognition | PP-OCRv4_server_rec | |
| PP-OCRv4_mobile_rec | ||
| ch_RepSVTR_rec | ||
| ch_SVTRv2_rec | ||
| Seal Text Detection | PP-OCRv4_server_seal_det | |
| PP-OCRv4_mobile_seal_det | ||
| Text Image Rectification | UVDoc | |
| Document Image Orientation Classification | PP-LCNet_x1_0_doc_ori |