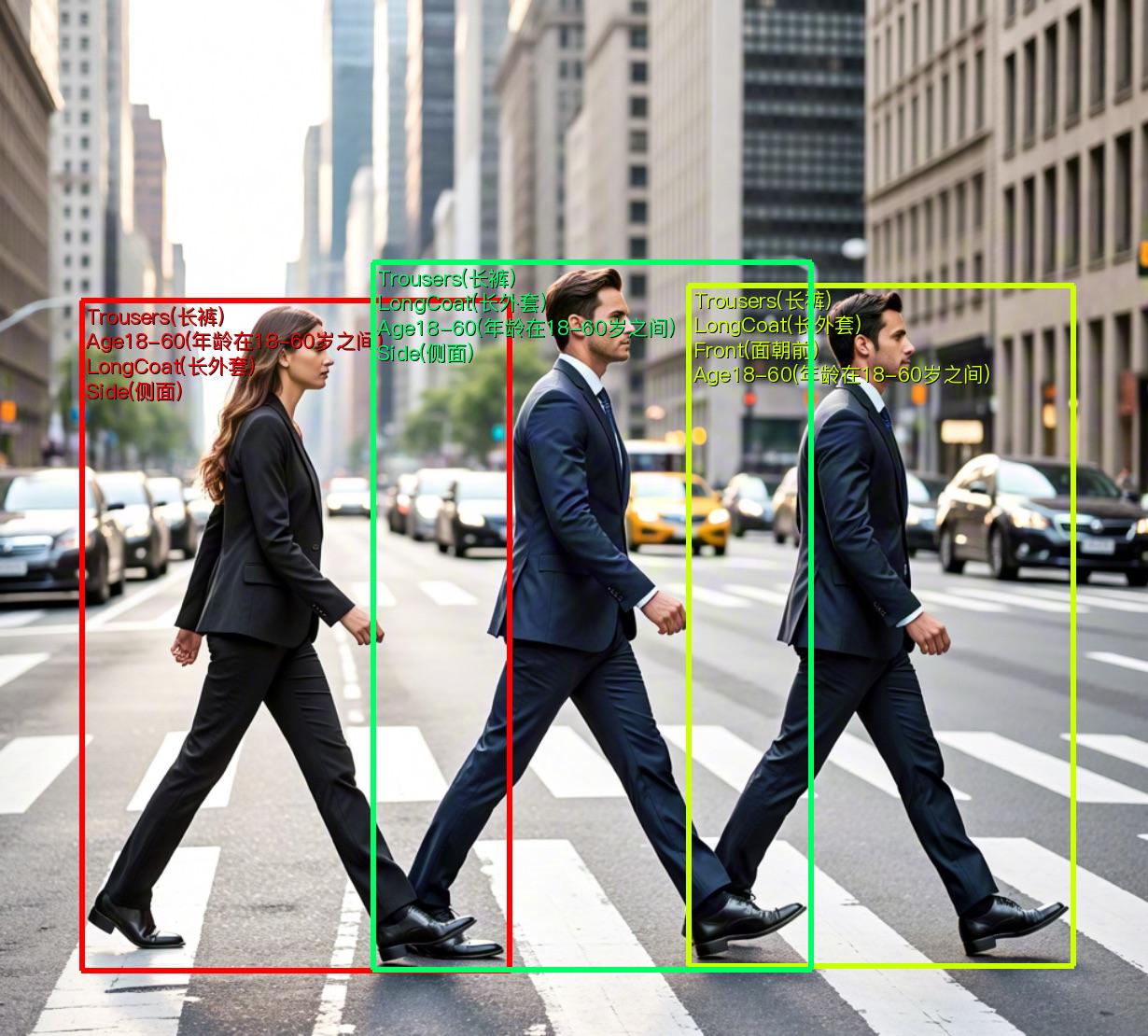
 The pedestrian attribute recognition pipeline includes a pedestrian detection module and a pedestrian attribute recognition module, with several models in each module. Which models to use specifically can be selected based on the benchmark data below. If you prioritize model accuracy, choose models with higher accuracy; if you prioritize inference speed, choose models with faster inference; if you prioritize model storage size, choose models with smaller storage.
The pedestrian attribute recognition pipeline includes a pedestrian detection module and a pedestrian attribute recognition module, with several models in each module. Which models to use specifically can be selected based on the benchmark data below. If you prioritize model accuracy, choose models with higher accuracy; if you prioritize inference speed, choose models with faster inference; if you prioritize model storage size, choose models with smaller storage.
Pedestrian Detection Module:
| Model | mAP(0.5:0.95) | mAP(0.5) | GPU Inference Time (ms) | CPU Inference Time (ms) | Model Size (M) | Description |
|---|---|---|---|---|---|---|
| PP-YOLOE-L_human | 48.0 | 81.9 | 32.8 | 777.7 | 196.02 | Pedestrian detection model based on PP-YOLOE |
| PP-YOLOE-S_human | 42.5 | 77.9 | 15.0 | 179.3 | 28.79 |
Note: The above accuracy metrics are mAP(0.5:0.95) on the CrowdHuman dataset. All model GPU inference times are based on an NVIDIA Tesla T4 machine with FP32 precision. CPU inference speeds are based on an Intel(R) Xeon(R) Gold 5117 CPU @ 2.00GHz with 8 threads and FP32 precision.
Pedestrian Attribute Recognition Module:
| Model | mA (%) | GPU Inference Time (ms) | CPU Inference Time (ms) | Model Size (M) | Description |
|---|---|---|---|---|---|
| PP-LCNet_x1_0_pedestrian_attribute | 92.2 | 3.84845 | 9.23735 | 6.7 M | PP-LCNet_x1_0_pedestrian_attribute is a lightweight pedestrian attribute recognition model based on PP-LCNet, covering 26 categories. |
Note: The above accuracy metrics are mA on PaddleX's internally built dataset. GPU inference times are based on an NVIDIA Tesla T4 machine with FP32 precision. CPU inference speeds are based on an Intel(R) Xeon(R) Gold 5117 CPU @ 2.00GHz with 8 threads and FP32 precision.
paddlex --get_pipeline_config pedestrian_attribute_recognition
After execution, the pedestrian attribute recognition pipeline configuration file will be saved in the current path. If you wish to specify a custom save location, you can run the following command (assuming the custom save location is ./my_path):
paddlex --get_pipeline_config pedestrian_attribute_recognition --save_path ./my_path
After obtaining the pipeline configuration file, you can replace --pipeline with the saved path of the configuration file to make it effective. For example, if the configuration file is saved at ./pedestrian_attribute_recognition.yaml, simply execute:
paddlex --pipeline ./pedestrian_attribute_recognition.yaml --input pedestrian_attribute_002.jpg --device gpu:0
Among them, parameters such as --model and --device do not need to be specified, and the parameters in the configuration file will be used. If parameters are still specified, the specified parameters will take precedence.
| Parameter | Description | Parameter Type | Default Value |
|---|---|---|---|
pipeline |
The name of the pipeline or the path to the pipeline configuration file. If it is the name of the pipeline, it must be a pipeline supported by PaddleX. | str |
None |
device |
The device for pipeline model inference. Supports: "gpu", "cpu". | str |
"gpu" |
use_hpip |
Whether to enable high-performance inference, only available when the pipeline supports high-performance inference. | bool |
False |
| Parameter Type | Description |
|---|---|
| Python Var | Supports directly passing in Python variables, such as image data represented by numpy.ndarray. |
str |
Supports passing in the file path of the data to be predicted, such as the local path of an image file: /root/data/img.jpg. |
str |
Supports passing in the URL of the data file to be predicted, such as the network URL of an image file: Example. |
str |
Supports passing in a local directory, which should contain the data files to be predicted, such as the local path: /root/data/. |
dict |
Supports passing in a dictionary type, where the key needs to correspond to the specific task, such as "img" for the pedestrian attribute recognition task, and the value of the dictionary supports the above data types, for example: {"img": "/root/data1"}. |
list |
Supports passing in a list, where the elements of the list need to be the above data types, such as [numpy.ndarray, numpy.ndarray], ["/root/data/img1.jpg", "/root/data/img2.jpg"], ["/root/data1", "/root/data2"], [{"img": "/root/data1"}, {"img": "/root/data2/img.jpg"}]. |
| Method | Description | Method Parameters |
|---|---|---|
print |
Print the results to the terminal | - format_json: bool, whether to format the output content with json indentation, default is True;- indent: int, json formatting setting, only effective when format_json is True, default is 4;- ensure_ascii: bool, json formatting setting, only effective when format_json is True, default is False; |
save_to_json |
Save the results as a json-formatted file | - save_path: str, the path to save the file, when it is a directory, the saved file name is consistent with the input file name;- indent: int, json formatting setting, default is 4;- ensure_ascii: bool, json formatting setting, default is False; |
save_to_img |
Save the results as an image file |
For all operations provided by the service:
200, and the attributes of the response body are as follows:| Name | Type | Meaning |
|---|---|---|
errorCode |
integer |
Error code. Fixed to 0. |
errorMsg |
string |
Error description. Fixed to "Success". |
The response body may also have a result attribute of type object, which stores the operation result information.
| Name | Type | Meaning |
|---|---|---|
errorCode |
integer |
Error code. Same as the response status code. |
errorMsg |
string |
Error description. |
The operations provided by the service are as follows:
inferObtain OCR results for an image.
POST /ocr
| Name | Type | Meaning | Required |
|---|---|---|---|
image |
string |
The URL of an accessible image file or the Base64 encoded result of the image file content. | Yes |
inferenceParams |
object |
Inference parameters. | No |
The attributes of```markdown
import base64
import requests
API_URL = "http://localhost:8080/ocr" # Service URL
image_path = "./demo.jpg"
output_image_path = "./out.jpg"
# Encode the local image to Base64
with open(image_path, "rb") as file:
image_bytes = file.read()
image_data = base64.b64encode(image_bytes).decode("ascii")
payload = {"image": image_data} # Base64 encoded file content or image URL
# Call the API
response = requests.post(API_URL, json=payload)
# Process the response data
assert response.status_code == 200
result = response.json()["result"]
with open(output_image_path, "wb") as file:
file.write(base64.b64decode(result["image"]))
print(f"Output image saved at {output_image_path}")
print("\nDetected texts:")
print(result["texts"])
#include <iostream>
#include "cpp-httplib/httplib.h" // https://github.com/Huiyicc/cpp-httplib
#include "nlohmann/json.hpp" // https://github.com/nlohmann/json
#include "base64.hpp" // https://github.com/tobiaslocker/base64
int main() {
httplib::Client client("localhost:8080");
const std::string imagePath = "./demo.jpg";
const std::string outputImagePath = "./out.jpg";
httplib::Headers headers = {
{"Content-Type", "application/json"}
};
// Encode the local image to Base64
std::ifstream file(imagePath, std::ios::binary | std::ios::ate);
std::streamsize size = file.tellg();
file.seekg(0, std::ios::beg);
std::vector<char> buffer(size);
if (!file.read(buffer.data(), size)) {
std::cerr << "Error reading file." << std::endl;
return 1;
}
std::string bufferStr(reinterpret_cast<const char*>(buffer.data()), buffer.size());
std::string encodedImage = base64::to_base64(bufferStr);
nlohmann::json jsonObj;
jsonObj["image"] = encodedImage;
std::string body = jsonObj.dump();
// Call the API
auto response = client.Post("/ocr", headers, body, "application/json");
// Process the response data
if (response && response->status == 200) {
nlohmann::json jsonResponse = nlohmann::json::parse(response->body);
auto result = jsonResponse["result"];
encodedImage = result["image"];
std::string decodedString = base64::from_base64(encodedImage);
std::vector<unsigned char> decodedImage(decodedString.begin(), decodedString.end());
std::ofstream outputImage(outputImagePath, std::ios::binary | std::ios::out);
if (outputImage.is_open()) {
outputImage.write(reinterpret_cast<char*>(decodedImage.data()), decodedImage.size());
outputImage.close();
std::cout << "Output image saved at " << outputImagePath << std::endl;
} else {
std::cerr << "Unable to open file for writing: " << outputImagePath << std::endl;
}
auto texts = result["texts"];
std::cout << "\nDetected texts:" << std::endl;
for (const auto& text : texts) {
std::cout << text << std::endl;
}
} else {
std::cout << "Failed to send HTTP request." << std::endl;
return 1;
}
return 0;
}
import okhttp3.*;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.node.ObjectNode;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Base64;
public class Main {
public static void main(String[] args) throws IOException {
String API_URL = "http://localhost:8080/ocr"; // Service URL
String imagePath = "./demo.jpg"; // Local image path
String outputImagePath = "./out.jpg"; // Output image path
// Encode the local image to Base64
File file = new File(imagePath);
byte[] fileContent = java.nio.file.Files.readAllBytes(file.toPath());
String imageData = Base64.getEncoder().encodeToString(fileContent);
ObjectMapper objectMapper = new ObjectMapper();
ObjectNode params = objectMapper.createObjectNode();
params.put("image", imageData); // Base64-encoded file content or image URL
// Create an OkHttpClient instance
OkHttpClient client = new OkHttpClient();
MediaType JSON = MediaType.get("application/json; charset=utf-8");
RequestBody body = RequestBody.create(params.toString(), JSON);
Request request = new Request.Builder()
.url(API_URL)
.post(body)
.build();
// Call the API and process the response
try (Response response = client.newCall(request).execute()) {
if (response.isSuccessful()) {
String responseBody = response.body().string();
JsonNode resultNode = objectMapper.readTree(responseBody);
JsonNode result = resultNode.get("result");
String base64Image = result.get("image").asText();
JsonNode texts = result.get("texts");
byte[] imageBytes = Base64.getDecoder().decode(base64Image);
try (FileOutputStream fos = new FileOutputStream(outputImagePath)) {
fos.write(imageBytes);
}
System.out.println("Output image saved at " + outputImagePath);
System.out.println("\nDetected texts: " + texts.toString());
} else {
System.err.println("Request failed with code: " + response.code());
}
}
}
}
package main
import (
"bytes"
"encoding/base64"
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
)
func main() {
API_URL := "http://localhost:8080/ocr"
imagePath := "./demo.jpg"
outputImagePath := "./out.jpg"
// Encode the local image to Base64
imageBytes, err := ioutil.ReadFile(imagePath)
if err != nil {
fmt.Println("Error reading image file:", err)
return
}
imageData := base64.StdEncoding.EncodeToString(imageBytes)
payload := map[string]string{"image": imageData} // Base64-encoded file content or image URL
payloadBytes, err := json.Marshal(payload)
if err != nil {
fmt.Println("Error marshaling payload:", err)
return
}
// Call the API
client := &http.Client{}
req, err := http.NewRequest("POST", API_URL, bytes.NewBuffer(payloadBytes))
if err != nil {
fmt.Println("Error creating request:", err)
return
}
res, err := client.Do(req)
if err != nil {
fmt.Println("Error sending request:", err)
return
}
defer res.Body.Close()
// Process the response
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println("Error reading response body:", err)
return
}```markdown
# An English Tutorial on Artificial Intelligence and Computer Vision
This tutorial document is intended for numerous developers and covers content related to artificial intelligence and computer vision.
<details>
<summary>C#</summary>
```csharp
using System;
using System.IO;
using System.Net.Http;
using System.Net.Http.Headers;
using System.Text;
using System.Threading.Tasks;
using Newtonsoft.Json.Linq;
class Program
{
static readonly string API_URL = "http://localhost:8080/ocr";
static readonly string imagePath = "./demo.jpg";
static readonly string outputImagePath = "./out.jpg";
static async Task Main(string[] args)
{
var httpClient = new HttpClient();
// Encode the local image to Base64
byte[] imageBytes = File.ReadAllBytes(imagePath);
string image_data = Convert.ToBase64String(imageBytes);
var payload = new JObject{ { "image", image_data } }; // Base64 encoded file content or image URL
var content = new StringContent(payload.ToString(), Encoding.UTF8, "application/json");
// Call the API
HttpResponseMessage response = await httpClient.PostAsync(API_URL, content);
response.EnsureSuccessStatusCode();
// Process the API response
string responseBody = await response.Content.ReadAsStringAsync();
JObject jsonResponse = JObject.Parse(responseBody);
string base64Image = jsonResponse["result"]["image"].ToString();
byte[] outputImageBytes = Convert.FromBase64String(base64Image);
File.WriteAllBytes(outputImagePath, outputImageBytes);
Console.WriteLine($"Output image saved at {outputImagePath}");
Console.WriteLine("\nDetected texts:");
Console.WriteLine(jsonResponse["result"]["texts"].ToString());
}
}
const axios = require('axios');
const fs = require('fs');
const API_URL = 'http://localhost:8080/ocr';
const imagePath = './demo.jpg';
const outputImagePath = "./out.jpg";
let config = {
method: 'POST',
maxBodyLength: Infinity,
url: API_URL,
data: JSON.stringify({
'image': encodeImageToBase64(imagePath) // Base64 encoded file content or image URL
})
};
// Encode the local image to Base64
function encodeImageToBase64(filePath) {
const bitmap = fs.readFileSync(filePath);
return Buffer.from(bitmap).toString('base64');
}
// Call the API
axios.request(config)
.then((response) => {
// Process the API response
const result = response.data["result"];
const imageBuffer = Buffer.from(result["image"], 'base64');
fs.writeFile(outputImagePath, imageBuffer, (err) => {
if (err) throw err;
console.log(`Output image saved at ${outputImagePath}`);
});
console.log("\nDetected texts:");
console.log(result["texts"]);
})
.catch((error) => {
console.log(error);
});
{kind=link}