---
comments: true
---
# Text Recognition Module Development Tutorial
## I. Overview
The text recognition module is the core component of an OCR (Optical Character Recognition) system, responsible for extracting text information from text regions within images. The performance of this module directly impacts the accuracy and efficiency of the entire OCR system. The text recognition module typically receives bounding boxes of text regions output by the text detection module as input. Through complex image processing and deep learning algorithms, it converts the text in images into editable and searchable electronic text. The accuracy of text recognition results is crucial for subsequent applications such as information extraction and data mining.
## II. Supported Model List
| Model | Model Download Link |
Recognition Avg Accuracy(%) |
GPU Inference Time (ms) |
CPU Inference Time (ms) |
Model Storage Size (M) |
Introduction |
| PP-OCRv4_server_rec_doc | Inference Model/Training Model |
|
|
|
|
PP-OCRv4_server_rec_doc is trained on a mixed dataset of more Chinese document data and PP-OCR training data based on PP-OCRv4_server_rec. It has added the ability to recognize some traditional Chinese characters, Japanese, and special characters, and can support the recognition of more than 15,000 characters. In addition to improving the text recognition capability related to documents, it also enhances the general text recognition capability. |
| PP-OCRv4_mobile_rec | Inference Model/Training Model |
78.20 |
7.95018 |
46.7868 |
10.6 M |
The PP-OCRv4 recognition model is further upgraded based on PP-OCRv3. Under comparable speed conditions, the effect in Chinese and English scenarios is further improved, and the average recognition accuracy of the 80-language multilingual model is increased by more than 8%. |
| PP-OCRv4_server_rec | Inference Model/Training Model |
79.20 |
7.19439 |
140.179 |
71.2 M |
A high-precision server-side text recognition model, featuring high accuracy, fast speed, and multilingual support. It is suitable for text recognition tasks in various scenarios. |
| en_PP-OCRv4_mobile_rec | Inference Model/Training Model |
|
|
|
|
The ultra-lightweight English text recognition model released by PaddleOCR in May 2023. It is small in size and fast in speed, and can achieve millisecond-level prediction on CPU. Compared with the PP-OCRv3 English model, the recognition accuracy is improved by 6%, and it is suitable for text recognition tasks in various scenarios. |
Note: The evaluation set for the above accuracy indicators is the Chinese dataset built by PaddleOCR, covering multiple scenarios such as street view, web images, documents, and handwriting, with 11,000 images included in text recognition. All models' GPU inference time is based on NVIDIA Tesla T4 machine, with precision type of FP32. CPU inference speed is based on Intel(R) Xeon(R) Gold 5117 CPU @ 2.00GHz, with 8 threads and precision type of FP32.
> ❗ The above list features the 4 core models that the text recognition module primarily supports. In total, this module supports 18 models. The complete list of models is as follows:
👉Model List Details
* Chinese Recognition Model
| Model | Model Download Link |
Recognition Avg Accuracy(%) |
GPU Inference Time (ms) |
CPU Inference Time (ms) |
Model Storage Size (M) |
Introduction |
| PP-OCRv4_server_rec_doc | Inference Model/Training Model |
|
|
|
|
PP-OCRv4_server_rec_doc is trained on a mixed dataset of more Chinese document data and PP-OCR training data based on PP-OCRv4_server_rec. It has added the recognition capabilities for some traditional Chinese characters, Japanese, and special characters. The number of recognizable characters is over 15,000. In addition to the improvement in document-related text recognition, it also enhances the general text recognition capability. |
| PP-OCRv4_mobile_rec | Inference Model/Training Model |
78.20 |
7.95018 |
46.7868 |
10.6 M |
The PP-OCRv4 recognition model is an upgrade from PP-OCRv3. Under comparable speed conditions, the effect in Chinese and English scenarios is further improved. The average recognition accuracy of the 80 multilingual models is increased by more than 8%. |
| PP-OCRv4_server_rec | Inference Model/Trained Model |
79.20 |
7.19439 |
140.179 |
71.2 M |
A high-precision server text recognition model, featuring high accuracy, fast speed, and multilingual support. It is suitable for text recognition tasks in various scenarios. |
| PP-OCRv3_mobile_rec | Inference Model/Training Model |
|
|
|
|
An ultra-lightweight OCR model suitable for mobile applications. It adopts an encoder-decoder structure based on Transformer and enhances recognition accuracy and efficiency through techniques such as data augmentation and mixed precision training. The model size is 10.6M, making it suitable for deployment on resource-constrained devices. It can be used in scenarios such as mobile photo translation and business card recognition. |
Note: The evaluation set for the above accuracy indicators is the Chinese dataset built by PaddleOCR, covering multiple scenarios such as street view, web images, documents, and handwriting. The text recognition includes 11,000 images. The GPU inference time for all models is based on NVIDIA Tesla T4 machines with FP32 precision type. The CPU inference speed is based on Intel(R) Xeon(R) Gold 5117 CPU @ 2.00GHz with 8 threads and FP32 precision type.
| Model | Model Download Link |
Recognition Avg Accuracy(%) |
GPU Inference Time (ms) |
CPU Inference Time |
Model Storage Size (M) |
Introduction |
| ch_SVTRv2_rec | Inference Model/Training Model |
68.81 |
8.36801 |
165.706 |
73.9 M |
SVTRv2 is a server text recognition model developed by the OpenOCR team of Fudan University's Visual and Learning Laboratory (FVL). It won the first prize in the PaddleOCR Algorithm Model Challenge - Task One: OCR End-to-End Recognition Task. The end-to-end recognition accuracy on the A list is 6% higher than that of PP-OCRv4.
|
Note: The evaluation set for the above accuracy indicators is the PaddleOCR Algorithm Model Challenge - Task One: OCR End-to-End Recognition Task A list. The GPU inference time for all models is based on NVIDIA Tesla T4 machines with FP32 precision type. The CPU inference speed is based on Intel(R) Xeon(R) Gold 5117 CPU @ 2.00GHz with 8 threads and FP32 precision type.
| Model | Model Download Link |
Recognition Avg Accuracy(%) |
GPU Inference Time (ms) |
CPU Inference Time |
Model Storage Size (M) |
Introduction |
| ch_RepSVTR_rec | Inference Model/Training Model |
65.07 |
10.5047 |
51.5647 |
22.1 M |
The RepSVTR text recognition model is a mobile text recognition model based on SVTRv2. It won the first prize in the PaddleOCR Algorithm Model Challenge - Task One: OCR End-to-End Recognition Task. The end-to-end recognition accuracy on the B list is 2.5% higher than that of PP-OCRv4, with the same inference speed. |
Note: The evaluation set for the above accuracy indicators is the PaddleOCR Algorithm Model Challenge - Task One: OCR End-to-End Recognition Task B list. The GPU inference time for all models is based on NVIDIA Tesla T4 machines with FP32 precision type. The CPU inference speed is based on Intel(R) Xeon(R) Gold 5117 CPU @ 2.00GHz with 8 threads and FP32 precision type.
* English Recognition Model
| Model | Model Download Link |
Recognition Avg Accuracy(%) |
GPU Inference Time (ms) |
CPU Inference Time |
Model Storage Size (M) |
Introduction |
| en_PP-OCRv4_mobile_rec | Inference Model/Training Model |
|
|
|
|
[Latest] Further upgraded based on PP-OCRv3, with improved accuracy under comparable speed conditions. |
| en_PP-OCRv3_mobile_rec | Inference Model/Training Model |
|
|
|
|
Ultra-lightweight model, supporting English and numeric recognition. |
* Multilingual Recognition Model
 In the above Python script, the following steps are executed:
* `create_model` instantiates the text recognition model (here, `PP-OCRv4_mobile_rec` is taken as an example)
* The `predict` method of the text recognition model is called for inference prediction. The parameter of the `predict` method is `x`, which is used to input the data to be predicted. It supports multiple input types, and the specific instructions are as follows:
In the above Python script, the following steps are executed:
* `create_model` instantiates the text recognition model (here, `PP-OCRv4_mobile_rec` is taken as an example)
* The `predict` method of the text recognition model is called for inference prediction. The parameter of the `predict` method is `x`, which is used to input the data to be predicted. It supports multiple input types, and the specific instructions are as follows:
| Parameter |
Parameter Description |
Parameter Type |
Options |
Default Value |
x |
Data to be predicted, supporting multiple input types |
Python Var/str/list |
- Python variable, such as image data represented by
numpy.ndarray
- File path, such as the local path of an image file:
/root/data/img.jpg
- URL link, such as the network URL of an image file: Example
- Local directory, this directory should contain the data files to be predicted, such as the local path:
/root/data/
- List, the elements of the list should be the above types of data, such as
[numpy.ndarray, numpy.ndarray], ["/root/data/img1.jpg", "/root/data/img2.jpg"], ["/root/data1", "/root/data2"], [{"img": "/root/data1"}, {"img": "/root/data2/img.jpg"}]
|
None |
module_name |
Name of the single-function module |
str |
None |
text_recognition |
model_name |
Name of the model |
str |
None |
PP-OCRv4_mobile_rec |
model_dir |
Path where the model is stored |
str |
None |
null |
batch_size |
Batch size |
int |
None |
1 |
score_thresh |
Score threshold |
int |
None |
0 |
* Process the prediction results. The prediction result for each sample is of `dict` type, and supports operations such as printing, saving as an image, and saving as a `json` file:
| Method |
Method Description |
Parameter |
Parameter Type |
Parameter Description |
Default Value |
print |
Print the result to the terminal |
format_json |
bool |
Whether to format the output content using json indentation |
True |
indent |
int |
JSON formatting setting, only effective when format_json is True |
4 |
ensure_ascii |
bool |
JSON formatting setting, only effective when format_json is True |
False |
save_to_json |
Save the result as a JSON file |
save_path |
str |
The path where the file is saved. If it is a directory, the saved file name is consistent with the input file name |
None |
indent |
int |
JSON formatting setting |
4 |
ensure_ascii |
bool |
JSON formatting setting |
False |
save_to_img |
Save the result as an image file |
save_path |
str |
The path where the file is saved. If it is a directory, the saved file name is consistent with the input file name |
None |
## IV. Custom Development
If you are seeking higher accuracy from existing models, you can use PaddleX's custom development capabilities to develop better text recognition models. Before using PaddleX to develop text recognition models, please ensure that you have installed the relevant model training plugins for OCR in PaddleX. The installation process can be found in the custom development section of the [PaddleX Local Installation Guide](../../../installation/installation.en.md).
### 4.1 Data Preparation
Before model training, it is necessary to prepare the corresponding dataset for each task module. PaddleX provides a data validation function for each module, and only data that passes the validation can be used for model training. Additionally, PaddleX offers Demo datasets for each module, allowing you to complete subsequent development based on the officially provided Demo data. If you wish to use a private dataset for subsequent model training, you can refer to the [PaddleX Text Detection/Text Recognition Task Module Data Annotation Tutorial](../../../data_annotations/ocr_modules/text_detection_recognition.en.md).
#### 4.1.1 Download Demo Data
You can use the following commands to download the Demo dataset to a specified folder:
```bash
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/ocr_rec_dataset_examples.tar -P ./dataset
tar -xf ./dataset/ocr_rec_dataset_examples.tar -C ./dataset/
```
#### 4.1.2 Data Validation
A single command can complete data validation:
```bash
python main.py -c paddlex/configs/modules/text_recognition/PP-OCRv4_mobile_rec.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/ocr_rec_dataset_examples
```
After executing the above command, PaddleX will validate the dataset and summarize its basic information. If the command runs successfully, it will print `Check dataset passed !` in the log. The validation results file is saved in `./output/check_dataset_result.json`, and related outputs are saved in the `./output/check_dataset` directory in the current directory, including visual examples of sample images and sample distribution histograms.
👉 Validation Result Details (Click to Expand)
The specific content of the validation result file is:
{
"done_flag": true,
"check_pass": true,
"attributes": {
"train_samples": 4468,
"train_sample_paths": [
"check_dataset\/demo_img\/train_word_1.png",
"check_dataset\/demo_img\/train_word_2.png",
"check_dataset\/demo_img\/train_word_3.png",
"check_dataset\/demo_img\/train_word_4.png",
"check_dataset\/demo_img\/train_word_5.png",
"check_dataset\/demo_img\/train_word_6.png",
"check_dataset\/demo_img\/train_word_7.png",
"check_dataset\/demo_img\/train_word_8.png",
"check_dataset\/demo_img\/train_word_9.png",
"check_dataset\/demo_img\/train_word_10.png"
],
"val_samples": 2077,
"val_sample_paths": [
"check_dataset\/demo_img\/val_word_1.png",
"check_dataset\/demo_img\/val_word_2.png",
"check_dataset\/demo_img\/val_word_3.png",
"check_dataset\/demo_img\/val_word_4.png",
"check_dataset\/demo_img\/val_word_5.png",
"check_dataset\/demo_img\/val_word_6.png",
"check_dataset\/demo_img\/val_word_7.png",
"check_dataset\/demo_img\/val_word_8.png",
"check_dataset\/demo_img\/val_word_9.png",
"check_dataset\/demo_img\/val_word_10.png"
]
},
"analysis": {
"histogram": "check_dataset\/histogram.png"
},
"dataset_path": "ocr_rec_dataset_examples",
"show_type": "image",
"dataset_type": "MSTextRecDataset"
}
In the above validation result, check_pass being true indicates that the dataset format meets the requirements. Explanations for other indicators are as follows:
attributes.train_samples: The number of training set samples in this dataset is 4468;attributes.val_samples: The number of validation set samples in this dataset is 2077;attributes.train_sample_paths: A list of relative paths to the visualized training set samples in this dataset;attributes.val_sample_paths: A list of relative paths to the visualized validation set samples in this dataset;
Additionally, the dataset validation also analyzes the distribution of character length ratios in the dataset and generates a distribution histogram (histogram.png):
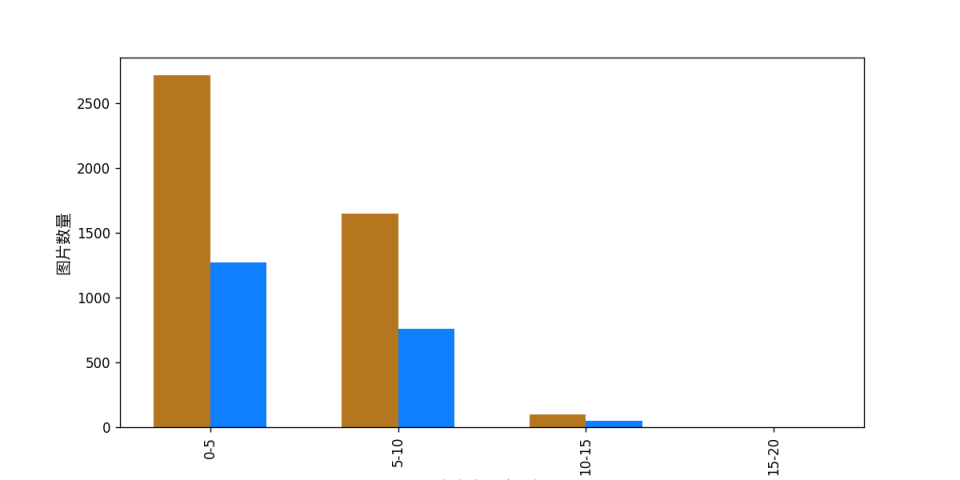
👉 Dataset Format Conversion/Dataset Splitting Details (Click to Expand)
(1) Dataset Format Conversion
Text recognition does not currently support data conversion.
(2) Dataset Splitting
The parameters for dataset splitting can be set by modifying the CheckDataset section in the configuration file. Examples of some parameters in the configuration file are as follows:
CheckDataset:split:enable: Whether to re-split the dataset. Set to True to enable dataset splitting, default is False;train_percent: If re-splitting the dataset, set the percentage of the training set. The type is any integer between 0-100, and it must sum up to 100 with val_percent;
For example, if you want to re-split the dataset with a 90% training set and a 10% validation set, modify the configuration file as follows:
......
CheckDataset:
......
split:
enable: True
train_percent: 90
val_percent: 10
......
Then execute the command:
python main.py -c paddlex/configs/modules/text_recognition/PP-OCRv4_mobile_rec.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/ocr_rec_dataset_examples
After data splitting, the original annotation files will be renamed to xxx.bak in the original path.
The above parameters also support setting through appending command line arguments:
python main.py -c paddlex/configs/modules/text_recognition/PP-OCRv4_mobile_rec.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/ocr_rec_dataset_examples \
-o CheckDataset.split.enable=True \
-o CheckDataset.split.train_percent=90 \
-o CheckDataset.split.val_percent=10
👉 More Information (Click to Expand)
- During model training, PaddleX automatically saves the model weight files, with the default being
output. If you need to specify a save path, you can set it through the -o Global.output field in the configuration file.
- PaddleX shields you from the concepts of dynamic graph weights and static graph weights. During model training, both dynamic and static graph weights are produced, and static graph weights are selected by default for model inference.
-
After completing the model training, all outputs are saved in the specified output directory (default is ./output/), typically including:
-
train_result.json: Training result record file, recording whether the training task was completed normally, as well as the output weight metrics, related file paths, etc.;
train.log: Training log file, recording changes in model metrics and loss during training;config.yaml: Training configuration file, recording the hyperparameter configuration for this training session;.pdparams, .pdema, .pdopt.pdstate, .pdiparams, .pdmodel: Model weight-related files, including network parameters, optimizer, EMA, static graph network parameters, static graph network structure, etc.;
👉 More Information (Click to Expand)
When evaluating the model, you need to specify the model weights file path. Each configuration file has a default weight save path. If you need to change it, simply append the command line parameter to set it, such as -o Evaluate.weight_path=./output/best_model/best_model.pdparams.
After completing the model evaluation, an evaluate_result.json file will be produced, which records the evaluation results, specifically, whether the evaluation task was completed successfully and the model's evaluation metrics, including acc、norm_edit_dis;
{kind=link}