---
comments: true
---
# 目标检测模块使用教程
## 一、概述
目标检测模块是计算机视觉系统中的关键组成部分,负责在图像或视频中定位和标记出包含特定目标的区域。该模块的性能直接影响到整个计算机视觉系统的准确性和效率。目标检测模块通常会输出目标区域的边界框(Bounding Boxes),这些边界框将作为输入传递给目标识别模块进行后续处理。
## 二、支持模型列表
| 模型 | 模型下载链接 |
mAP(%) |
GPU推理耗时(ms)
[常规模式 / 高性能模式] |
CPU推理耗时(ms)
[常规模式 / 高性能模式] |
模型存储大小 (M) |
介绍 |
| PicoDet-L | 推理模型/训练模型 |
42.6 |
14.68 / 5.81 |
47.32 / 47.32 |
20.9 M |
PP-PicoDet是一种全尺寸、棱视宽目标的轻量级目标检测算法,它考虑移动端设备运算量。与传统目标检测算法相比,PP-PicoDet具有更小的模型尺寸和更低的计算复杂度,并在保证检测精度的同时更高的速度和更低的延迟。 |
| PicoDet-S | 推理模型/训练模型 |
29.1 |
7.98 / 2.33 |
14.82 / 5.60 |
4.4 M |
| PP-YOLOE_plus-L | 推理模型/训练模型 |
52.9 |
33.55 / 10.46 |
189.05 / 189.05 |
185.3 M |
PP-YOLOE_plus 是一种是百度飞桨视觉团队自研的云边一体高精度模型PP-YOLOE迭代优化升级的版本,通过使用Objects365大规模数据集、优化预处理,大幅提升了模型端到端推理速度。 |
| PP-YOLOE_plus-S | 推理模型/训练模型 |
43.7 |
12.16 / 4.58 |
73.86 / 52.90 |
28.3 M |
| RT-DETR-H | 推理模型/训练模型 |
56.3 |
115.92 / 28.16 |
971.32 / 971.32 |
435.8 M |
RT-DETR是第一个实时端到端目标检测器。该模型设计了一个高效的混合编码器,满足模型效果与吞吐率的双需求,高效处理多尺度特征,并提出了加速和优化的查询选择机制,以优化解码器查询的动态化。RT-DETR支持通过使用不同的解码器来实现灵活端到端推理速度。 |
| RT-DETR-L | 推理模型/训练模型 |
53.0 |
35.00 / 10.45 |
495.51 / 495.51 |
113.7 M |
> ❗ 以上列出的是目标检测模块重点支持的6个核心模型,该模块总共支持37个模型,完整的模型列表如下:
👉模型列表详情
| 模型 | 模型下载链接 |
mAP(%) |
GPU推理耗时(ms)
[常规模式 / 高性能模式] |
CPU推理耗时(ms)
[常规模式 / 高性能模式] |
模型存储大小 (M) |
介绍 |
| Cascade-FasterRCNN-ResNet50-FPN | 推理模型/训练模型 |
41.1 |
135.92 / 135.92 |
- |
245.4 M |
Cascade-FasterRCNN 是一种改进的Faster R-CNN目标检测模型,通过耦联多个检测器,利用不同IoU阈值优化检测结果,解决训练和预测阶段的mismatch问题,提高目标检测的准确性。 |
| Cascade-FasterRCNN-ResNet50-vd-SSLDv2-FPN | 推理模型/训练模型 |
45.0 |
138.23 / 138.23 |
- |
246.2 M |
| CenterNet-DLA-34 | 推理模型/训练模型 |
37.6 |
- |
- |
75.4 M |
CenterNet是一种anchor-free目标检测模型,把待检测物体的关键点视为单一点-即其边界框的中心点,并通过关键点进行回归。 |
| CenterNet-ResNet50 | 推理模型/训练模型 |
38.9 |
- |
- |
319.7 M |
| DETR-R50 | 推理模型/训练模型 |
42.3 |
62.91 / 17.33 |
392.63 / 392.63 |
159.3 M |
DETR 是Facebook提出的一种transformer目标检测模型,该模型在不需要预定义的先验框anchor和NMS的后处理策略的情况下,就可以实现端到端的目标检测。 |
| FasterRCNN-ResNet34-FPN | 推理模型/训练模型 |
37.8 |
83.33 / 31.64 |
- |
137.5 M |
Faster R-CNN是典型的two-stage目标检测模型,即先生成区域建议(Region Proposal),然后在生成的Region Proposal上做分类和回归。相较于前代R-CNN和Fast R-CNN,Faster R-CNN的改进主要在于区域建议方面,使用区域建议网络(Region Proposal Network, RPN)提供区域建议,以取代传统选择性搜索。RPN是卷积神经网络,并与检测网络共享图像的卷积特征,减少了区域建议的计算开销。 |
| FasterRCNN-ResNet50-FPN | 推理模型/训练模型 |
38.4 |
107.08 / 35.40 |
- |
148.1 M |
| FasterRCNN-ResNet50-vd-FPN | 推理模型/训练模型 |
39.5 |
109.36 / 36.00 |
- |
148.1 M |
| FasterRCNN-ResNet50-vd-SSLDv2-FPN | 推理模型/训练模型 |
41.4 |
109.06 / 36.19 |
- |
148.1 M |
| FasterRCNN-ResNet50 | 推理模型/训练模型 |
36.7 |
496.33 / 109.12 |
- |
120.2 M |
| FasterRCNN-ResNet101-FPN | 推理模型/训练模型 |
41.4 |
148.21 / 42.21 |
- |
216.3 M |
| FasterRCNN-ResNet101 | 推理模型/训练模型 |
39.0 |
538.58 / 120.88 |
- |
188.1 M |
| FasterRCNN-ResNeXt101-vd-FPN | 推理模型/训练模型 |
43.4 |
258.01 / 58.25 |
- |
360.6 M |
| FasterRCNN-Swin-Tiny-FPN | 推理模型/训练模型 |
42.6 |
- |
- |
159.8 M |
| FCOS-ResNet50 | 推理模型/训练模型 |
39.6 |
106.13 / 28.32 |
721.79 / 721.79 |
124.2 M |
FCOS是一种密集预测的anchor-free目标检测模型,使用RetinaNet的骨架,直接在feature map上回归目标物体的长宽,并预测物体的类别以及centerness(feature map上像素点离物体中心的偏移程度),centerness最终会作为权重来调整物体得分。 |
| PicoDet-L | 推理模型/训练模型 |
42.6 |
14.68 / 5.81 |
47.32 / 47.32 |
20.9 M |
PP-PicoDet是一种全尺寸、棱视宽目标的轻量级目标检测算法,它考虑移动端设备运算量。与传统目标检测算法相比,PP-PicoDet具有更小的模型尺寸和更低的计算复杂度,并在保证检测精度的同时更高的速度和更低的延迟。 |
| PicoDet-M | 推理模型/训练模型 |
37.5 |
9.62 / 3.23 |
23.75 / 14.88 |
16.8 M |
| PicoDet-S | 推理模型/训练模型 |
29.1 |
7.98 / 2.33 |
14.82 / 5.60 |
4.4 M |
| PicoDet-XS | 推理模型/训练模型 |
26.2 |
9.66 / 2.75 |
19.15 / 7.24 |
5.7 M |
| PP-YOLOE_plus-L | 推理模型/训练模型 |
52.9 |
33.55 / 10.46 |
189.05 / 189.05 |
185.3 M |
PP-YOLOE_plus 是一种是百度飞桨视觉团队自研的云边一体高精度模型PP-YOLOE迭代优化升级的版本,通过使用Objects365大规模数据集、优化预处理,大幅提升了模型端到端推理速度。 |
| PP-YOLOE_plus-M | 推理模型/训练模型 |
49.8 |
19.52 / 7.46 |
113.36 / 113.36 |
82.3 M |
| PP-YOLOE_plus-S | 推理模型/训练模型 |
43.7 |
12.16 / 4.58 |
73.86 / 52.90 |
28.3 M |
| PP-YOLOE_plus-X | 推理模型/训练模型 |
54.7 |
58.87 / 15.84 |
292.93 / 292.93 |
349.4 M |
| RT-DETR-H | 推理模型/训练模型 |
56.3 |
115.92 / 28.16 |
971.32 / 971.32 |
435.8 M |
RT-DETR是第一个实时端到端目标检测器。该模型设计了一个高效的混合编码器,满足模型效果与吞吐率的双需求,高效处理多尺度特征,并提出了加速和优化的查询选择机制,以优化解码器查询的动态化。RT-DETR支持通过使用不同的解码器来实现灵活端到端推理速度。 |
| RT-DETR-L | 推理模型/训练模型 |
53.0 |
35.00 / 10.45 |
495.51 / 495.51 |
113.7 M |
| RT-DETR-R18 | 推理模型/训练模型 |
46.5 |
20.21 / 6.23 |
266.01 / 266.01 |
70.7 M |
| RT-DETR-R50 | 推理模型/训练模型 |
53.1 |
42.14 / 11.31 |
523.97 / 523.97 |
149.1 M |
| RT-DETR-X | 推理模型/训练模型 |
54.8 |
61.24 / 15.83 |
647.08 / 647.08 |
232.9 M |
| YOLOv3-DarkNet53 | 推理模型/训练模型 |
39.1 |
41.58 / 10.10 |
158.78 / 158.78 |
219.7 M |
YOLOv3是一种实时的端到端目标检测器。它使用一个独特的单个卷积神经网络,将目标检测问题分解为一个回归问题,从而实现实时的检测。该模型采用了多个尺度的检测,提高了不同尺度目标物体的检测性能。 |
| YOLOv3-MobileNetV3 | 推理模型/训练模型 |
31.4 |
16.53 / 5.70 |
60.44 / 60.44 |
83.8 M |
| YOLOv3-ResNet50_vd_DCN | 推理模型/训练模型 |
40.6 |
32.91 / 10.07 |
225.72 / 224.32 |
163.0 M |
| YOLOX-L | 推理模型/训练模型 |
50.1 |
121.19 / 13.55 |
295.38 / 274.15 |
192.5 M |
YOLOX模型以YOLOv3作为目标检测网络的框架,通过设计Decoupled Head、Data Aug、Anchor Free以及SimOTA组件,显著提升了模型在各种复杂场景下的检测性能。 |
| YOLOX-M | 推理模型/训练模型 |
46.9 |
87.19 / 10.09 |
183.95 / 172.67 |
90.0 M |
| YOLOX-N | 推理模型/训练模型 |
26.1 |
53.31 / 45.02 |
69.69 / 59.18 |
3.4 M |
| YOLOX-S | 推理模型/训练模型 |
40.4 |
129.52 / 13.19 |
181.39 / 179.01 |
32.0 M |
| YOLOX-T | 推理模型/训练模型 |
32.9 |
66.81 / 61.31 |
92.30 / 83.90 |
18.1 M |
| YOLOX-X | 推理模型/训练模型 |
51.8 |
156.40 / 20.17 |
480.14 / 454.35 |
351.5 M |
| Co-Deformable-DETR-R50 | 推理模型/训练模型 |
49.7 |
|
|
184 M |
Co-DETR是一种先进的端到端目标检测器。它基于DETR架构,通过引入协同混合分配训练策略,将目标检测任务中的传统一对多标签分配与一对一匹配相结合,从而显著提高了检测性能和训练效率 |
| Co-Deformable-DETR-Swin-T | 推理模型/训练模型 |
48.0 |
|
|
187 M |
注:以上精度指标为COCO2017验证集 mAP(0.5:0.95)。所有模型 GPU 推理耗时基于 NVIDIA Tesla T4 机器,精度类型为 FP32, CPU 推理速度基于 Intel(R) Xeon(R) Gold 5117 CPU @ 2.00GHz,线程数为8,精度类型为 FP32。
[xmin, ymin, xmax, ymax]
可视化图像如下:
 相关方法、参数等说明如下:
* `create_model`实例化目标检测模型(此处以`PicoDet-S`为例),具体说明如下:
相关方法、参数等说明如下:
* `create_model`实例化目标检测模型(此处以`PicoDet-S`为例),具体说明如下:
| 参数 |
参数说明 |
参数类型 |
可选项 |
默认值 |
model_name |
模型名称 |
str |
无 |
无 |
model_dir |
模型存储路径 |
str |
无 |
无 |
img_size |
输入图像大小;如果不指定,将默认使用PaddleX官方模型配置 |
int/list/None |
- int, 如 640 , 表示将输入图像resize到640x640大小
- 列表, 如 [512, 640] , 表示将输入图像resize到宽为640,高为512大小
|
None |
threshold |
用于过滤掉低置信度预测结果的阈值;如果不指定,将默认使用PaddleX官方模型配置 |
float/dict/None |
- float,如 0.2, 表示过滤掉所有阈值小于0.2的目标框
- 字典,字典的key为int类型,代表
cls_id,val为float类型阈值。如 {0: 0.45, 2: 0.48, 7: 0.4},表示对cls_id为0的类别应用阈值0.45、cls_id为1的类别应用阈值0.48、cls_id为7的类别应用阈值0.4
|
None |
use_hpip |
是否启用高性能推理 |
bool |
无 |
False |
* 其中,`model_name` 必须指定,指定 `model_name` 后,默认使用 PaddleX 内置的模型参数,在此基础上,指定 `model_dir` 时,使用用户自定义的模型。
* 调用目标检测模型的 `predict()` 方法进行推理预测,`predict()` 方法参数有 `input`、`batch_size`和`threshold`,具体说明如下:
| 参数 |
参数说明 |
参数类型 |
可选项 |
默认值 |
input |
待预测数据,支持多种输入类型,必填 |
Python Var|str|list |
- Python Var:如
numpy.ndarray 表示的图像数据
- str:如图像文件或者PDF文件的本地路径:
/root/data/img.jpg;如URL链接,如图像文件或PDF文件的网络URL:示例;如本地目录,该目录下需包含待预测图像,如本地路径:/root/data/(当前不支持目录中包含PDF文件的预测,PDF文件需要指定到具体文件路径)
- List:列表元素需为上述类型数据,如
[numpy.ndarray, numpy.ndarray],[\"/root/data/img1.jpg\", \"/root/data/img2.jpg\"],[\"/root/data1\", \"/root/data2\"]
|
无 |
batch_size |
批大小 |
int |
任意整数 |
1 |
threshold |
用于过滤掉低置信度预测结果的阈值;如果不指定,将默认使用 creat_model 指定的 threshold 参数,如果 creat_model 也没有指定,则默认使用PaddleX官方模型配置 |
float/dict/None |
- float,如 0.2, 表示过滤掉所有阈值小于0.2的目标框
- 字典,字典的key为int类型,代表
cls_id,val为float类型阈值。如 {0: 0.45, 2: 0.48, 7: 0.4},表示对cls_id为0的类别应用阈值0.45、cls_id为1的类别应用阈值0.48、cls_id为7的类别应用阈值0.4
|
None |
* 对预测结果进行处理,每个样本的预测结果均为对应的Result对象,且支持打印、保存为图片、保存为`json`文件的操作:
| 方法 |
方法说明 |
参数 |
参数类型 |
参数说明 |
默认值 |
print() |
打印结果到终端 |
format_json |
bool |
是否对输出内容进行使用 JSON 缩进格式化 |
True |
indent |
int |
指定缩进级别,以美化输出的 JSON 数据,使其更具可读性,仅当 format_json 为 True 时有效 |
4 |
ensure_ascii |
bool |
控制是否将非 ASCII 字符转义为 Unicode。设置为 True 时,所有非 ASCII 字符将被转义;False 则保留原始字符,仅当format_json为True时有效 |
False |
save_to_json() |
将结果保存为json格式的文件 |
save_path |
str |
保存的文件路径,当为目录时,保存文件命名与输入文件类型命名一致 |
无 |
indent |
int |
指定缩进级别,以美化输出的 JSON 数据,使其更具可读性,仅当 format_json 为 True 时有效 |
4 |
ensure_ascii |
bool |
控制是否将非 ASCII 字符转义为 Unicode。设置为 True 时,所有非 ASCII 字符将被转义;False 则保留原始字符,仅当format_json为True时有效 |
False |
save_to_img() |
将结果保存为图像格式的文件 |
save_path |
str |
保存的文件路径,当为目录时,保存文件命名与输入文件类型命名一致 |
无 |
* 此外,也支持通过属性获取带结果的可视化图像和预测结果,具体如下:
| 属性 |
属性说明 |
json |
获取预测的json格式的结果 |
img |
获取格式为dict的可视化图像 |
关于更多 PaddleX 的单模型推理的 API 的使用方法,可以参考[PaddleX单模型Python脚本使用说明](../../instructions/model_python_API.md)。
## 四、二次开发
如果你追求更高精度的现有模型,可以使用 PaddleX 的二次开发能力,开发更好的目标检测模型。在使用 PaddleX 开发目标检测模型之前,请务必安装 PaddleX的目标检测相关模型训练插件,安装过程可以参考 [PaddleX本地安装教程](../../../installation/installation.md)
### 4.1 数据准备
在进行模型训练前,需要准备相应任务模块的数据集。PaddleX 针对每一个模块提供了数据校验功能,只有通过数据校验的数据才可以进行模型训练。此外,PaddleX 为每一个模块都提供了 Demo 数据集,您可以基于官方提供的 Demo 数据完成后续的开发。若您希望用私有数据集进行后续的模型训练,可以参考[PaddleX目标检测任务模块数据标注教程](../../../data_annotations/cv_modules/object_detection.md)。
#### 4.1.1 Demo 数据下载
您可以参考下面的命令将 Demo 数据集下载到指定文件夹:
```bash
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/det_coco_examples.tar -P ./dataset
tar -xf ./dataset/det_coco_examples.tar -C ./dataset/
```
#### 4.1.2 数据校验
一行命令即可完成数据校验:
```bash
python main.py -c paddlex/configs/modules/object_detection/PicoDet-S.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/det_coco_examples
```
执行上述命令后,PaddleX 会对数据集进行校验,并统计数据集的基本信息,命令运行成功后会在log中打印出`Check dataset passed !`信息。校验结果文件保存在`./output/check_dataset_result.json`,同时相关产出会保存在当前目录的`./output/check_dataset`目录下,产出目录中包括可视化的示例样本图片和样本分布直方图。
👉 校验结果详情(点击展开)
校验结果文件具体内容为:
{
"done_flag": true,
"check_pass": true,
"attributes": {
"num_classes": 4,
"train_samples": 701,
"train_sample_paths": [
"check_dataset/demo_img/road839.png",
"check_dataset/demo_img/road363.png",
"check_dataset/demo_img/road148.png",
"check_dataset/demo_img/road237.png",
"check_dataset/demo_img/road733.png",
"check_dataset/demo_img/road861.png",
"check_dataset/demo_img/road762.png",
"check_dataset/demo_img/road515.png",
"check_dataset/demo_img/road754.png",
"check_dataset/demo_img/road173.png"
],
"val_samples": 176,
"val_sample_paths": [
"check_dataset/demo_img/road218.png",
"check_dataset/demo_img/road681.png",
"check_dataset/demo_img/road138.png",
"check_dataset/demo_img/road544.png",
"check_dataset/demo_img/road596.png",
"check_dataset/demo_img/road857.png",
"check_dataset/demo_img/road203.png",
"check_dataset/demo_img/road589.png",
"check_dataset/demo_img/road655.png",
"check_dataset/demo_img/road245.png"
]
},
"analysis": {
"histogram": "check_dataset/histogram.png"
},
"dataset_path": "det_coco_examples",
"show_type": "image",
"dataset_type": "COCODetDataset"
}
上述校验结果中,check_pass 为 true 表示数据集格式符合要求,其他部分指标的说明如下:
attributes.num_classes:该数据集类别数为 4;attributes.train_samples:该数据集训练集样本数量为 704;attributes.val_samples:该数据集验证集样本数量为 176;attributes.train_sample_paths:该数据集训练集样本可视化图片相对路径列表;attributes.val_sample_paths:该数据集验证集样本可视化图片相对路径列表;
另外,数据集校验还对数据集中所有类别的样本数量分布情况进行了分析,并绘制了分布直方图(histogram.png):
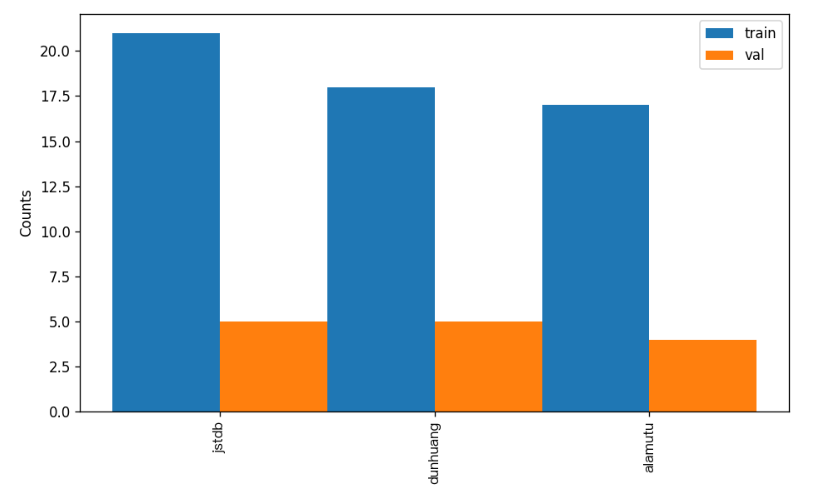
👉 格式转换/数据集划分详情(点击展开)
(1)数据集格式转换
目标检测支持 VOC、LabelMe 格式的数据集转换为 COCO 格式。
数据集校验相关的参数可以通过修改配置文件中 CheckDataset 下的字段进行设置,配置文件中部分参数的示例说明如下:
CheckDataset:convert:enable: 是否进行数据集格式转换,目标检测支持 VOC、LabelMe 格式的数据集转换为 COCO 格式,默认为 False;src_dataset_type: 如果进行数据集格式转换,则需设置源数据集格式,默认为 null,可选值为 VOC、LabelMe 和 VOCWithUnlabeled、LabelMeWithUnlabeled ;
例如,您想转换 LabelMe 格式的数据集为 COCO 格式,以下面的LabelMe 格式的数据集为例,则需要修改配置如下:
cd /path/to/paddlex
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/det_labelme_examples.tar -P ./dataset
tar -xf ./dataset/det_labelme_examples.tar -C ./dataset/
......
CheckDataset:
......
convert:
enable: True
src_dataset_type: LabelMe
......
随后执行命令:
python main.py -c paddlex/configs/modules/object_detection/PicoDet-S.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/det_labelme_examples
当然,以上参数同样支持通过追加命令行参数的方式进行设置,以 LabelMe 格式的数据集为例:
python main.py -c paddlex/configs/modules/object_detection/PicoDet-S.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/det_labelme_examples \
-o CheckDataset.convert.enable=True \
-o CheckDataset.convert.src_dataset_type=LabelMe
(2)数据集划分
数据集划分的参数可以通过修改配置文件中 CheckDataset 下的字段进行设置,配置文件中部分参数的示例说明如下:
CheckDataset:split:enable: 是否进行重新划分数据集,为 True 时进行数据集格式转换,默认为 False;train_percent: 如果重新划分数据集,则需要设置训练集的百分比,类型为0-100之间的任意整数,需要保证和 val_percent 值加和为100;val_percent: 如果重新划分数据集,则需要设置验证集的百分比,类型为0-100之间的任意整数,需要保证和 train_percent 值加和为100;
例如,您想重新划分数据集为 训练集占比90%、验证集占比10%,则需将配置文件修改为:
......
CheckDataset:
......
split:
enable: True
train_percent: 90
val_percent: 10
......
随后执行命令:
python main.py -c paddlex/configs/modules/object_detection/PicoDet-S.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/det_coco_examples
数据划分执行之后,原有标注文件会被在原路径下重命名为 xxx.bak。
以上参数同样支持通过追加命令行参数的方式进行设置:
python main.py -c paddlex/configs/modules/object_detection/PicoDet-S.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/det_coco_examples \
-o CheckDataset.split.enable=True \
-o CheckDataset.split.train_percent=90 \
-o CheckDataset.split.val_percent=10
👉 更多说明(点击展开)
👉 更多说明(点击展开)
在模型评估时,需要指定模型权重文件路径,每个配置文件中都内置了默认的权重保存路径,如需要改变,只需要通过追加命令行参数的形式进行设置即可,如-o Evaluate.weight_path=./output/best_model/best_model.pdparams。
在完成模型评估后,会产出evaluate_result.json,其记录了评估的结果,具体来说,记录了评估任务是否正常完成,以及模型的评估指标,包含 AP;
{kind=link}