| Parameter |
Parameter Description |
Parameter Type |
Options |
Default Value |
input |
Data to be predicted, supporting multiple input types |
Python Var/str/list |
- Python variable, such as image data represented by
numpy.ndarray
- File path, such as the local path of an image file:
/root/data/img.jpg
- URL link, such as the network URL of an image file: Example
- Local directory, the directory should contain data files to be predicted, such as the local path:
/root/data/
- List, elements of the list must be of the above types of data, such as
[numpy.ndarray, numpy.ndarray], ["/root/data/img1.jpg", "/root/data/img2.jpg"], ["/root/data1", "/root/data2"]
|
None |
batch_size |
Batch size |
int |
Any integer |
1 |
threshold |
Threshold for filtering low-confidence objects |
float/None |
- None, indicating the use of settings from the lower priority. The priority of parameter settings from highest to lowest is:
predict parameter > create_model initialization > yaml configuration file
- float, such as 0.5, indicating the use of
0.5 as the threshold for filtering low-confidence objects during inference
|
None |
* The prediction results are processed, and the prediction result for each sample is of type `dict`. It supports operations such as printing, saving as an image, and saving as a `json` file:
| Method |
Method Description |
Parameter |
Parameter Type |
Parameter Description |
Default Value |
print() |
Print the results to the terminal |
format_json |
bool |
Whether to format the output content using JSON indentation |
True |
indent |
int |
Specify the indentation level to beautify the output JSON data, making it more readable, only effective when format_json is True |
4 |
ensure_ascii |
bool |
Control whether to escape non-ASCII characters to Unicode. If set to True, all non-ASCII characters will be escaped; False retains the original characters, only effective when format_json is True |
False
|
save_to_json() |
Save the results as a JSON file |
save_path |
str |
The path to save the file. If it is a directory, the saved file name will be consistent with the input file name |
None |
indent |
int |
Specify the indentation level to beautify the output JSON data, making it more readable, only effective when format_json is True |
4 |
ensure_ascii |
bool |
Control whether to escape non-ASCII characters to Unicode. If set to True, all non-ASCII characters will be escaped; False retains the original characters, only effective when format_json is True |
False
|
save_to_img() |
Save the results as an image file |
save_path |
str |
The path to save the file. If it is a directory, the saved file name will be consistent with the input file name |
None
|
* Additionally, it supports obtaining the visualization image with results and the prediction results through attributes, as follows:
👉 Details of Validation Results (Click to Expand)
The specific content of the validation result file is:
{
"done_flag": true,
"check_pass": true,
"attributes": {
"num_classes": 2,
"train_samples": 79,
"train_sample_paths": [
"check_dataset/demo_img/pexels-photo-634007.jpeg",
"check_dataset/demo_img/pexels-photo-59576.png"
],
"val_samples": 19,
"val_sample_paths": [
"check_dataset/demo_img/peasant-farmer-farmer-romania-botiza-47862.jpeg",
"check_dataset/demo_img/pexels-photo-715546.png"
]
},
"analysis": {
"histogram": "check_dataset/histogram.png"
},
"dataset_path": "instance_seg_coco_examples",
"show_type": "image",
"dataset_type": "COCOInstSegDataset"
}
In the above verification results, check_pass being True indicates that the dataset format meets the requirements. Explanations for other indicators are as follows:
attributes.num_classes: The number of classes in this dataset is 2;attributes.train_samples: The number of training samples in this dataset is 79;attributes.val_samples: The number of validation samples in this dataset is 19;attributes.train_sample_paths: A list of relative paths to the visualized training samples in this dataset;attributes.val_sample_paths: A list of relative paths to the visualized validation samples in this dataset;
Additionally, the dataset verification also analyzes the distribution of sample numbers across all categories in the dataset and generates a distribution histogram (histogram.png):
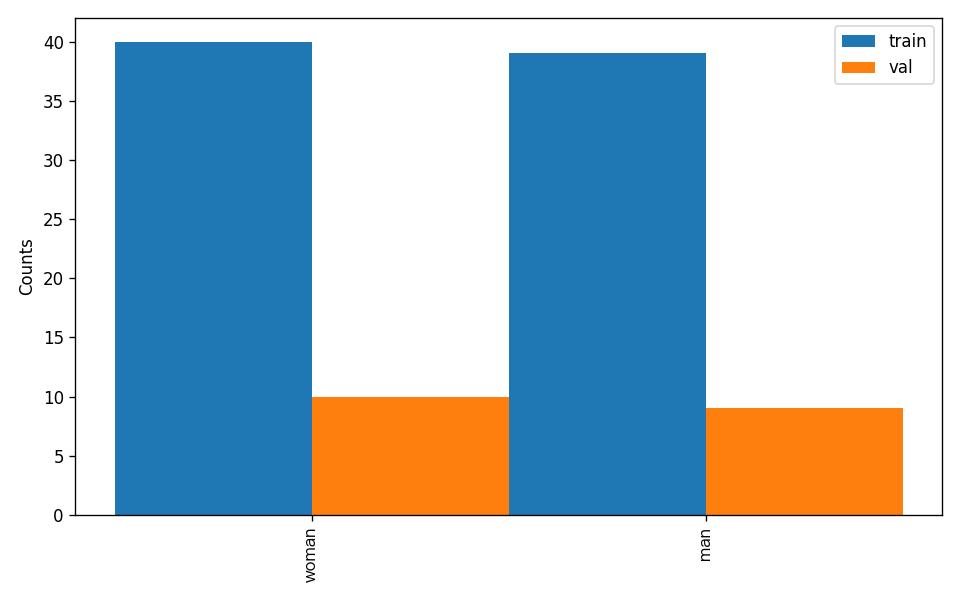
👉 Details of Format Conversion/Dataset Splitting (Click to Expand)
(1) Dataset Format Conversion
The instance segmentation task supports converting LabelMe format to COCO format. The parameters for dataset format conversion can be set by modifying the fields under CheckDataset in the configuration file. Below are some example explanations for some of the parameters in the configuration file:
CheckDataset:convert:enable: Whether to perform dataset format conversion. Set to True to enable dataset format conversion, default is False;src_dataset_type: If dataset format conversion is performed, the source dataset format needs to be set. The available source format is LabelMe;
For example, if you want to convert a LabelMe dataset to COCO format, you need to modify the configuration file as follows:
cd /path/to/paddlex
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/instance_seg_labelme_examples.tar -P ./dataset
tar -xf ./dataset/instance_seg_labelme_examples.tar -C ./dataset/
......
CheckDataset:
......
convert:
enable: True
src_dataset_type: LabelMe
......
Then execute the command:
python main.py -c paddlex/configs/modules/instance_segmentation/Mask-RT-DETR-L.yaml\
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/instance_seg_labelme_examples
After the data conversion is executed, the original annotation files will be renamed to xxx.bak in the original path.
The above parameters also support being set by appending command line arguments:
python main.py -c paddlex/configs/modules/instance_segmentation/Mask-RT-DETR-L.yaml\
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/instance_seg_labelme_examples \
-o CheckDataset.convert.enable=True \
-o CheckDataset.convert.src_dataset_type=LabelMe
(2) Dataset Splitting
The parameters for dataset splitting can be set by modifying the fields under CheckDataset in the configuration file. Some example explanations for the parameters in the configuration file are as follows:
CheckDataset:split:enable: Whether to re-split the dataset. When set to True, the dataset will be re-split. The default is False;train_percent: If the dataset is to be re-split, the percentage of the training set needs to be set. The type is any integer between 0-100, and the sum with val_percent must be 100;
For example, if you want to re-split the dataset with a 90% training set and a 10% validation set, you need to modify the configuration file as follows:
......
CheckDataset:
......
split:
enable: True
train_percent: 90
val_percent: 10
......
Then execute the command:
python main.py -c paddlex/configs/modules/instance_segmentation/Mask-RT-DETR-L.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/instance_seg_labelme_examples
After data splitting, the original annotation files will be renamed as xxx.bak in the original path.
The above parameters can also be set by appending command line arguments:
python main.py -c paddlex/configs/modules/instance_segmentation/Mask-RT-DETR-L.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/instance_seg_labelme_examples \
-o CheckDataset.split.enable=True \
-o CheckDataset.split.train_percent=90 \
-o CheckDataset.split.val_percent=10
👉 More Details (Click to Expand)
When evaluating the model, you need to specify the model weights file path. Each configuration file has a default weight save path built-in. If you need to change it, simply set it by appending a command line parameter, such as -o Evaluate.weight_path=./output/best_model/best_model.pdparams.
After completing the model evaluation, an evaluate_result.json file will be generated, which records the evaluation results, specifically whether the evaluation task was completed successfully and the model's evaluation metrics, including AP.
 **Note:** Due to network issues, the above URL may not be accessible. If you need to access this link, please check the validity of the URL and try again. If the problem persists, it may be related to the link itself or the network connection.
Related methods, parameters, and explanations are as follows:
* `create_model` instantiates a general instance segmentation model (here, `PP-YOLOE_seg-S` is used as an example), and the specific explanations are as follows:
**Note:** Due to network issues, the above URL may not be accessible. If you need to access this link, please check the validity of the URL and try again. If the problem persists, it may be related to the link itself or the network connection.
Related methods, parameters, and explanations are as follows:
* `create_model` instantiates a general instance segmentation model (here, `PP-YOLOE_seg-S` is used as an example), and the specific explanations are as follows:
{kind=link}