👉 校验结果详情(点击展开)
校验结果文件具体内容为:
{
"done_flag": true,
"check_pass": true,
"attributes": {
"train_sample_paths": [
"check_dataset/demo_img/P0005.jpg",
"check_dataset/demo_img/P0050.jpg"
],
"train_samples": 267,
"val_sample_paths": [
"check_dataset/demo_img/N0139.jpg",
"check_dataset/demo_img/P0137.jpg"
],
"val_samples": 76,
"num_classes": 2
},
"analysis": {
"histogram": "check_dataset/histogram.png"
},
"dataset_path": "seg_optic_examples",
"show_type": "image",
"dataset_type": "SegDataset"
}
上述校验结果中,check_pass 为 True 表示数据集格式符合要求,其他部分指标的说明如下:
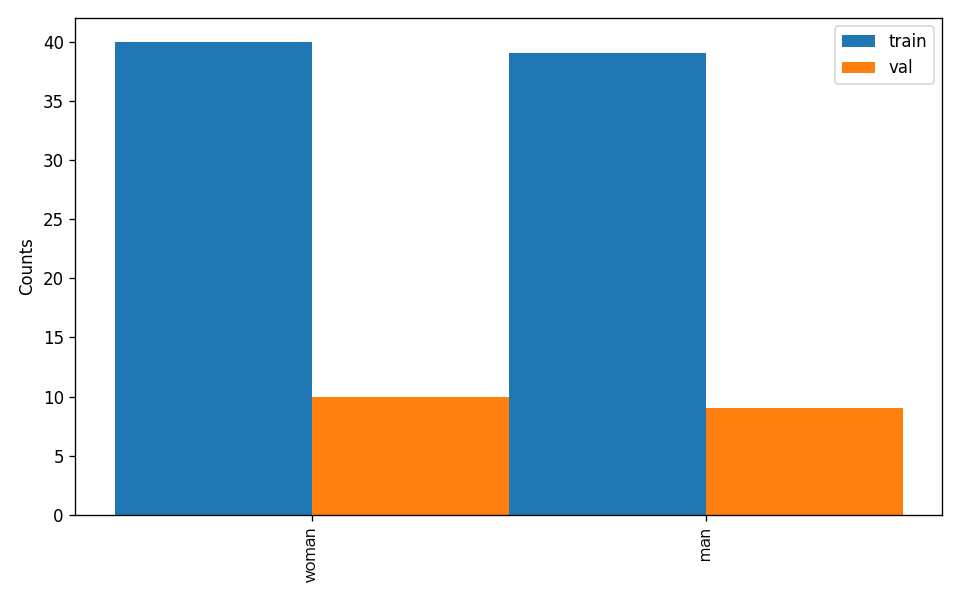
attributes.num_classes:该数据集类别数为 2;attributes.train_samples:该数据集训练集样本数量为 267;attributes.val_samples:该数据集验证集样本数量为 76;attributes.train_sample_paths:该数据集训练集样本可视化图片相对路径列表;attributes.val_sample_paths:该数据集验证集样本可视化图片相对路径列表;
数据集校验还对数据集中所有类别的样本数量分布情况进行了分析,并绘制了分布直方图(histogram.png):
👉 格式转换/数据集划分详情(点击展开)
在您完成数据校验之后,可以通过修改配置文件或是追加超参数的方式对数据集的格式进行转换,也可以对数据集的训练/验证比例进行重新划分。
(1)数据集格式转换
语义分割支持 LabelMe 格式的数据集转换为要求的格式。
数据集校验相关的参数可以通过修改配置文件中 CheckDataset 下的字段进行设置,配置文件中部分参数的示例说明如下:
CheckDataset:convert:enable: 是否进行数据集格式转换,支持LabelMe 格式的数据集转换,默认为 False;src_dataset_type: 如果进行数据集格式转换,则需设置源数据集格式,默认为 null,支持的源数据集格式是LabelMe;
例如,您想转换 LabelMe 格式的数据集,提供了一个LabelMe 格式的示例数据集,如下:
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/seg_dataset_to_convert.tar -P ./dataset
tar -xf ./dataset/seg_dataset_to_convert.tar -C ./dataset/
下载后,需要修改 paddlex/configs/modules/semantic_segmentation/PP-LiteSeg-T.yaml配置如下:
......
CheckDataset:
......
convert:
enable: True
src_dataset_type: LabelMe
......
随后执行命令:
python main.py -c paddlex/configs/modules/semantic_segmentation/PP-LiteSeg-T.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/seg_dataset_to_convert
当然,以上参数同样支持通过追加命令行参数的方式进行设置,以 LabelMe 格式的数据集为例:
python main.py -c paddlex/configs/modules/semantic_segmentation/PP-LiteSeg-T.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/seg_dataset_to_convert \
-o CheckDataset.convert.enable=True \
-o CheckDataset.convert.src_dataset_type=LabelMe
(2)数据集划分
数据集划分的参数可以通过修改配置文件中 CheckDataset 下的字段进行设置,配置文件中部分参数的示例说明如下:
- CheckDataset:
- split:
- enable: 是否进行重新划分数据集,为 True 时进行数据集格式转换,默认为 False;
- train_percent: 如果重新划分数据集,则需要设置训练集的百分比,类型为0-100之间的任意整数,需要保证与 val_percent 的值之和为100;
例如,您想重新划分数据集为 训练集占比90%、验证集占比10%,则需将配置文件修改为:
......
CheckDataset:
......
split:
enable: True
train_percent: 90
val_percent: 10
......
随后执行命令:
python main.py -c paddlex/configs/modules/semantic_segmentation/PP-LiteSeg-T.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/seg_optic_examples
数据划分执行之后,原有标注文件会被在原路径下重命名为 xxx.bak。
以上参数同样支持通过追加命令行参数的方式进行设置:
python main.py -c paddlex/configs/modules/semantic_segmentation/PP-LiteSeg-T.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/seg_optic_examples \
-o CheckDataset.split.enable=True \
-o CheckDataset.split.train_percent=90 \
-o CheckDataset.split.val_percent=10
 相关方法、参数等说明如下:
* `create_model`实例化通用语义分割模型(此处以`PP-LiteSeg-T`为例),具体说明如下:
相关方法、参数等说明如下:
* `create_model`实例化通用语义分割模型(此处以`PP-LiteSeg-T`为例),具体说明如下:
{kind=link}