
text_detection_recognition.md 8.0 KB
简体中文 | English
PaddleX文本检测/文本识别任务模块数据标注教程
1. 标注数据示例
2. PPOCRLabel标注
2.1 PPOCRLabel标注工具介绍
PPOCRLabel 是一款适用于OCR领域的半自动化图形标注工具,内置PP-OCR模型对数据自动标注和重新识别。使用Python3和PyQT5编写,支持矩形框标注、表格标注、不规则文本标注、关键信息标注模式。在OCR的标注任务中,标签存储为 txt 文件。
2.2 安装与运行PPOCRLabel
PPOCRLabel可通过whl包与Python脚本两种方式启动,whl包形式启动更加方便,这里只提供whl包说明:
windows 安装:
pip install PPOCRLabel # 安装 # 选择标签模式来启动 PPOCRLabel --lang ch # 启动【普通模式】,用于打【检测+识别】场景的标签
[!NOTE] 通过whl包安装PPOCRLabel会自动下载
paddleocrwhl包,其中shapely依赖可能会出现[winRrror 126] 找不到指定模块的问题。的错误,建议下载shapely安装包完成安装。
MacOS
pip3 install PPOCRLabel pip3 install opencv-contrib-python-headless==4.2.0.32 # 如果下载过慢请添加"-i https://mirror.baidu.com/pypi/simple" # 选择标签模式来启动 PPOCRLabel --lang ch # 启动【普通模式】,用于打【检测+识别】场景的标签
2.3 文本检测和文本识别的标注过程
- 安装与运行:使用上述命令安装与运行程序。
- 打开文件夹:在菜单栏点击 “文件” - "打开目录" 选择待标记图片的文件夹.
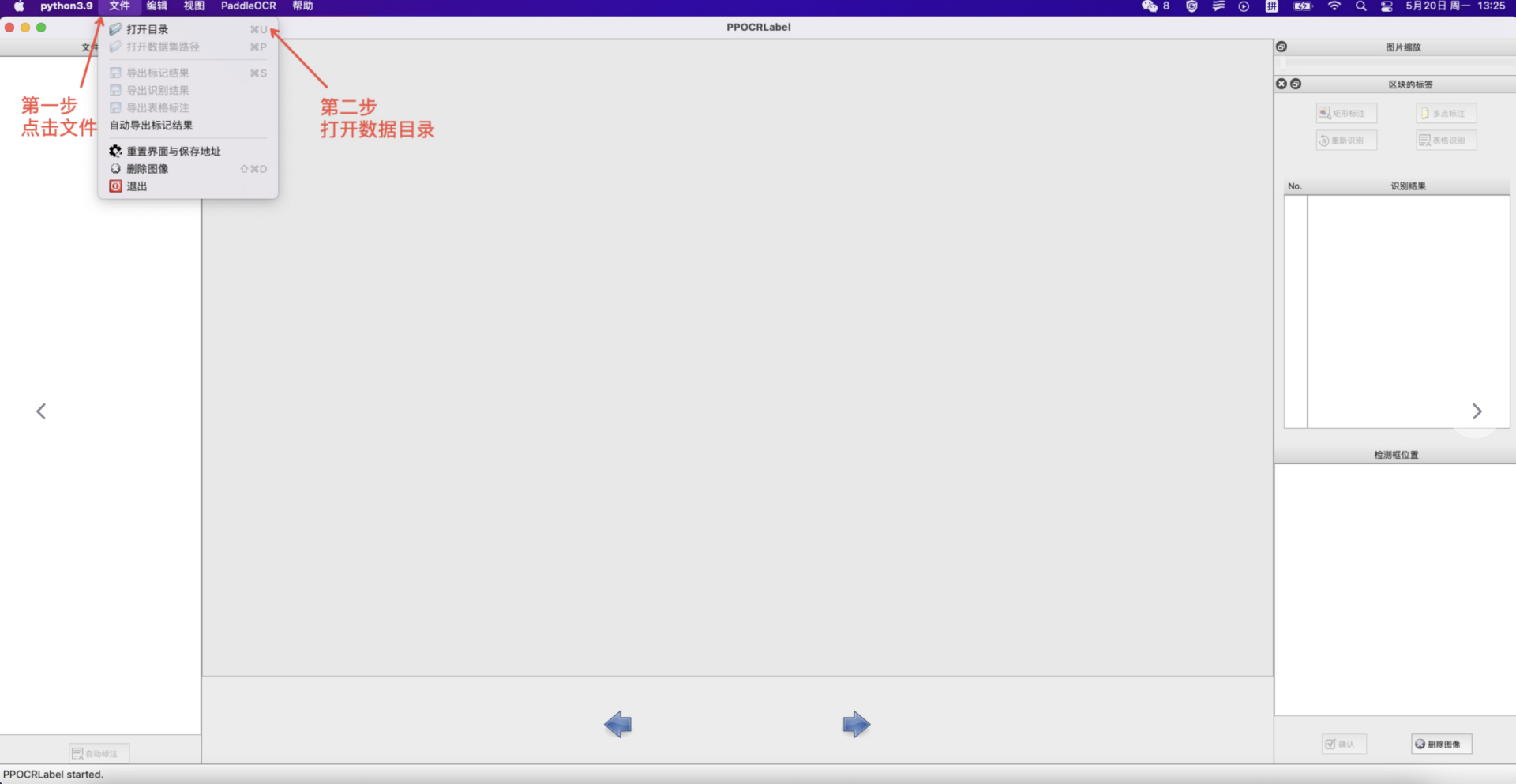
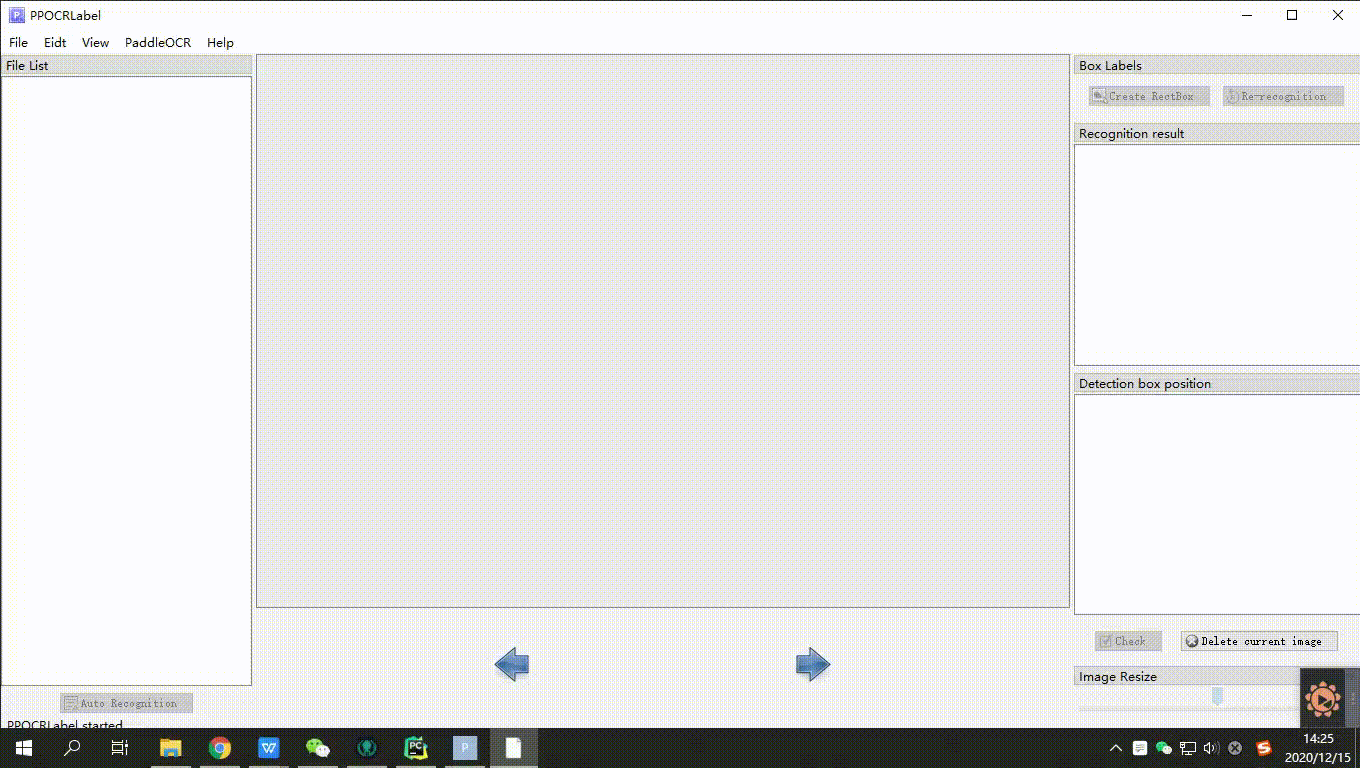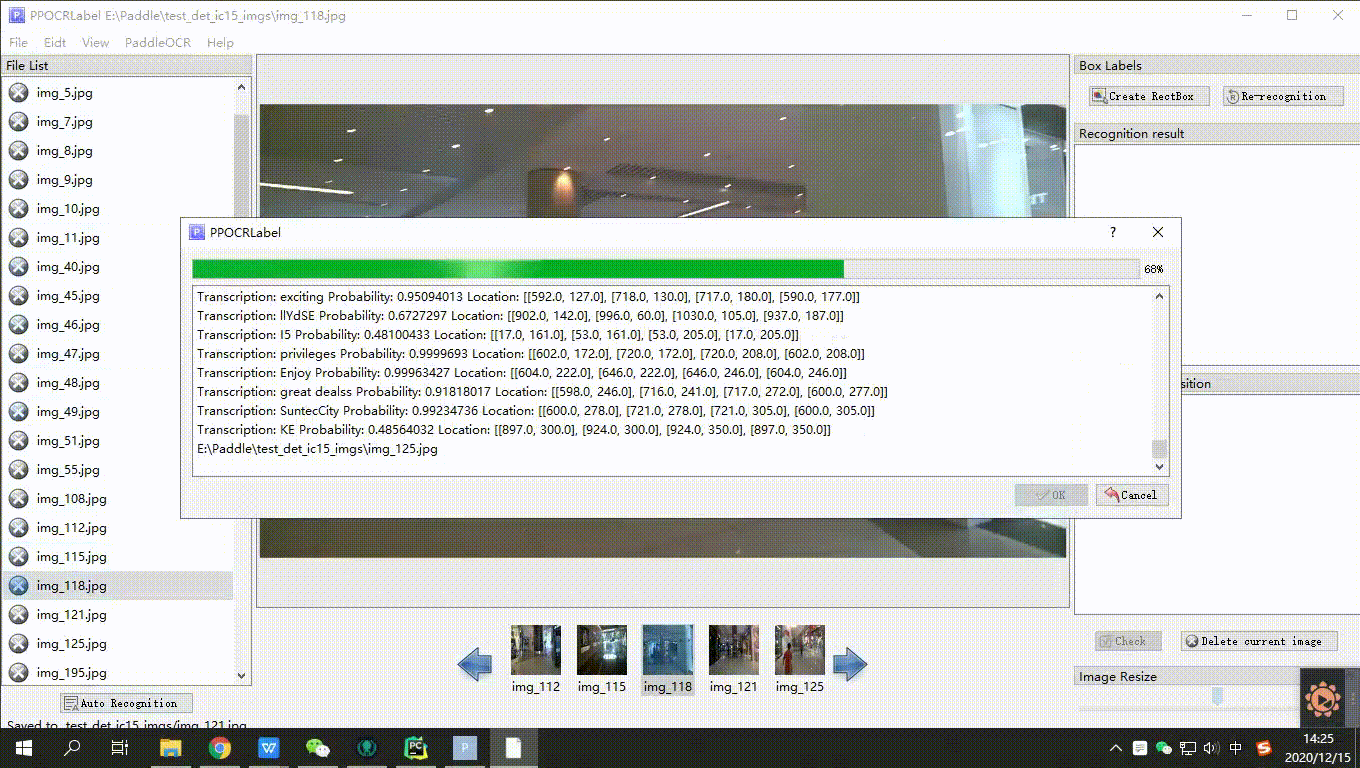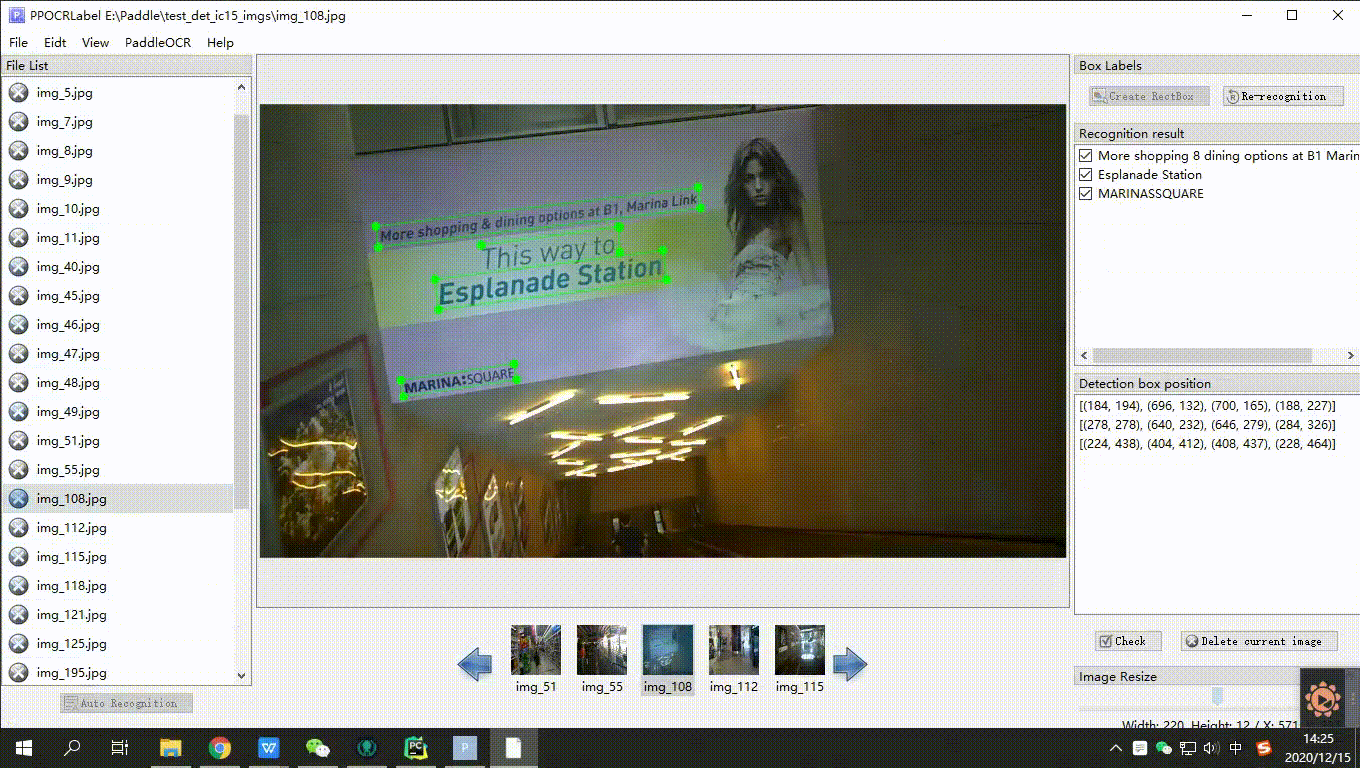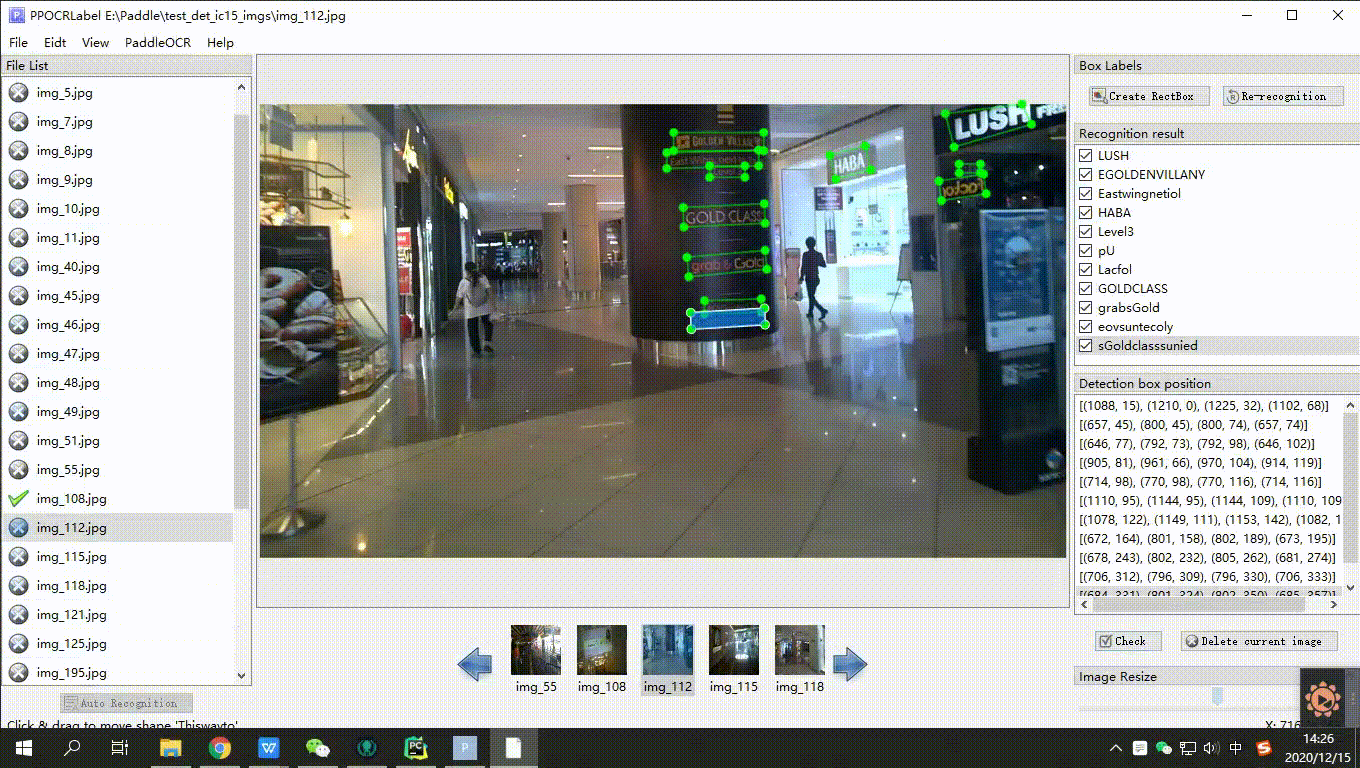
- 自动标注:点击 ”自动标注“,使用PP-OCR超轻量模型对图片文件名前图片状态为 “X” 的图片进行自动标注。
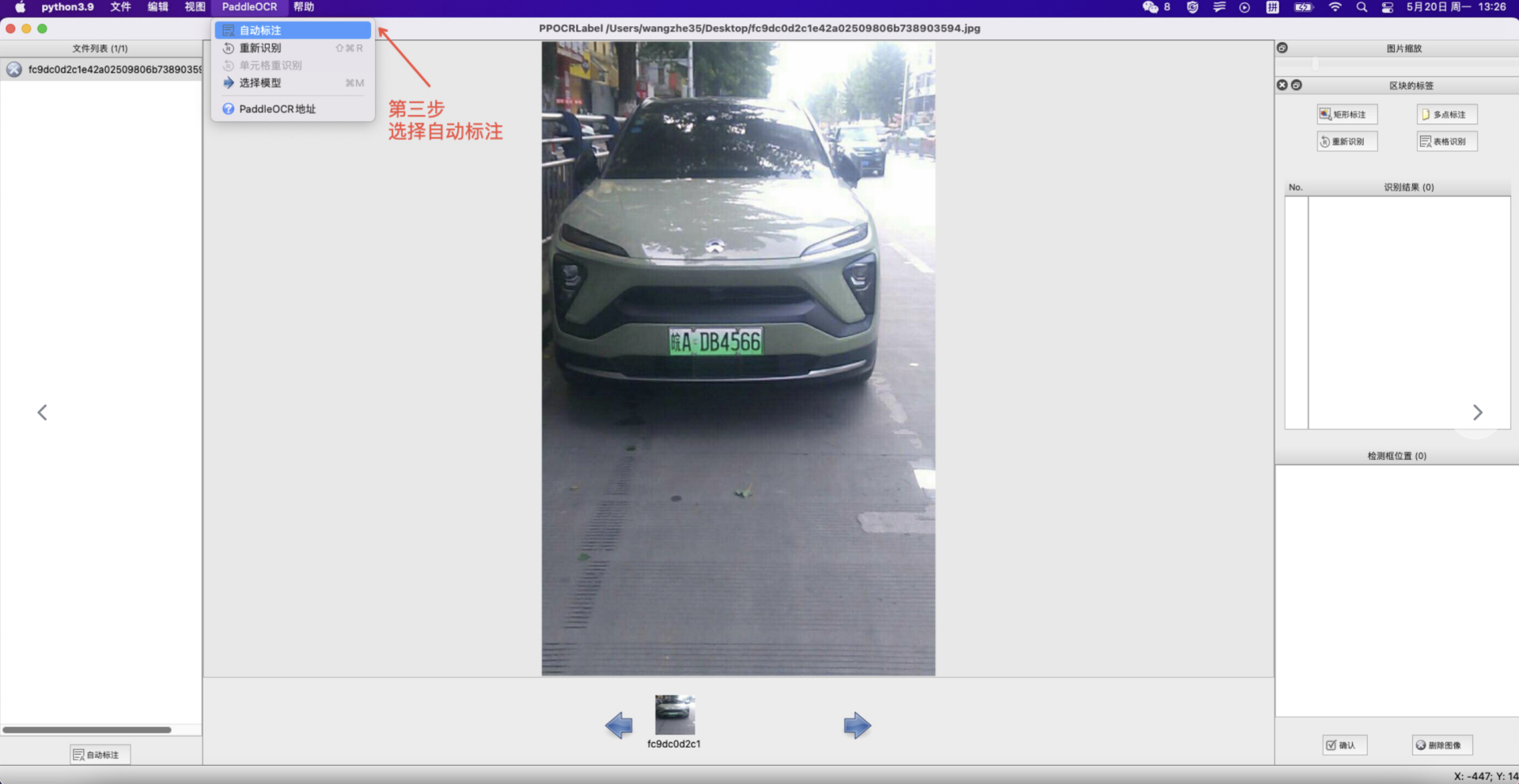
- 手动标注:点击 “矩形标注”(推荐直接在英文模式下点击键盘中的 “W”),用户可对当前图片中模型未检出的部分进行手动绘制标记框。点击键盘Q,则使用四点标注模式(或点击“编辑” - “四点标注”),用户依次点击4个点后,双击左键表示标注完成。
- 标记框绘制完成后,用户点击 “确认”,检测框会先被预分配一个 “待识别” 标签。
- 重新识别:将图片中的所有检测画绘制/调整完成后,点击 “重新识别”,PP-OCR模型会对当前图片中的所有检测框重新识别[3]。
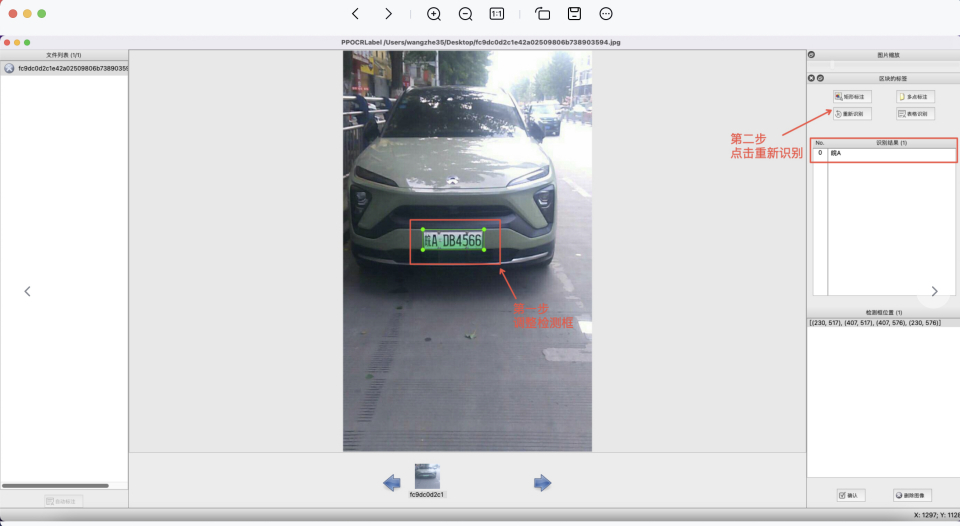
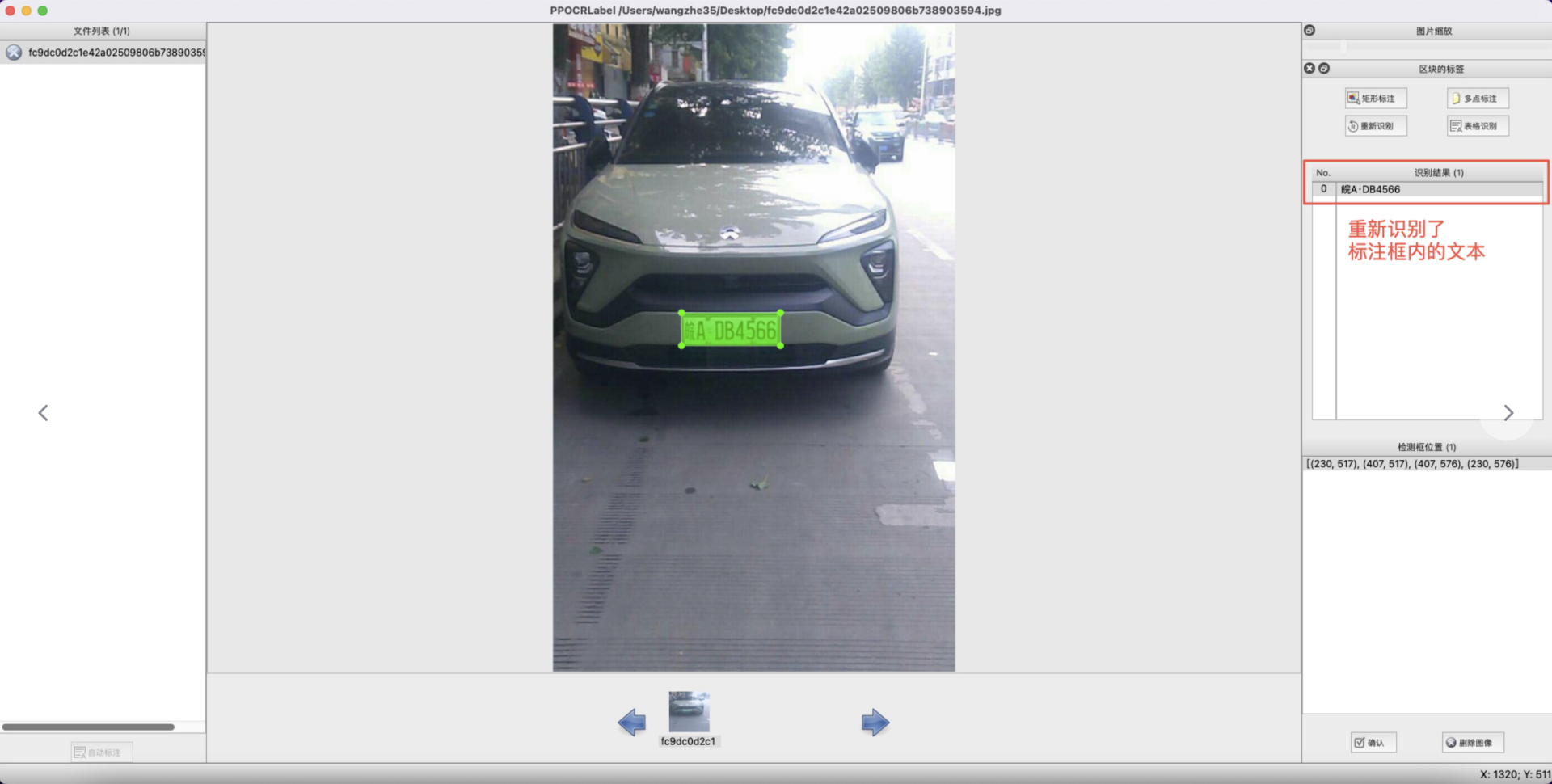
- 内容更改:单击识别结果,对不准确的识别结果进行手动更改。
- 确认标记:点击 “确认”,图片状态切换为 “√”,跳转至下一张。
- 删除:点击 “删除图像”,图片将会被删除至回收站。
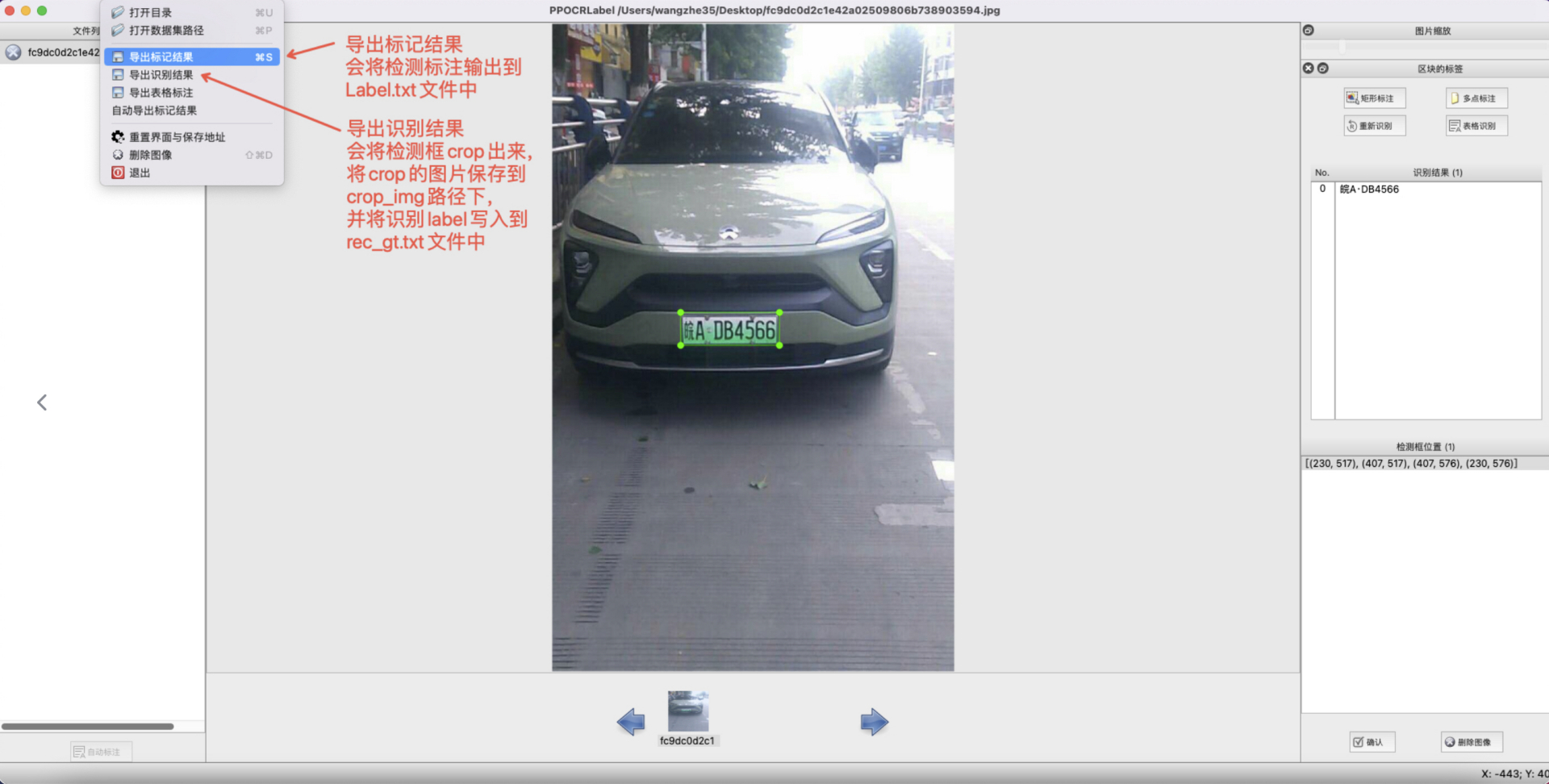
- 导出结果:用户可以通过菜单中“文件-导出标记结果”手动导出,同时也可以点击“文件 - 自动导出标记结果”开启自动导出。手动确认过的标记将会被存放在所打开图片文件夹下的
Label.txt中。在菜单栏点击 “文件” - "导出识别结果"后,会将此类图片的识别训练数据保存在crop_img文件夹下,识别标签保存在rec_gt.txt中。
 注意事项:
注意事项:
- PPOCRLabel以文件夹为基本标记单位,打开待标记的图片文件夹后,不会在窗口栏中显示图片,而是在点击 "选择文件夹" 之后直接将文件夹下的图片导入到程序中。
- 图片状态表示本张图片用户是否手动保存过,未手动保存过即为 “X”,手动保存过为 “√”。点击 “自动标注”按钮后,PPOCRLabel不会对状态为 “√” 的图片重新标注。
- 点击“重新识别”后,模型会对图片中的识别结果进行覆盖。因此如果在此之前手动更改过识别结果,有可能在重新识别后产生变动。
- PPOCRLabel产生的文件放置于标记图片文件夹下,包括以下几种,请勿手动更改其中内容,否则会引起程序出现异常。
|文件名|说明|
|-|-|
|Label.txt|检测标签,可直接用于PPOCR检测模型训练。用户每确认5张检测结果后,程序会进行自动写入。当用户关闭应用程序或切换文件路径后同样会进行写入。|
|fileState.txt|图片状态标记文件,保存当前文件夹下已经被用户手动确认过的图片名称。|
|Cache.cach|缓存文件,保存模型自动识别的结果。|
|rec_gt.txt|识别标签。可直接用于PPOCR识别模型训练。需用户手动点击菜单栏“文件” - "导出识别结果"后产生。|
|crop_img|识别数据。按照检测框切割后的图片。与rec_gt.txt同时产生。|
如果需要数据划分,可以按照如下步骤操作:
cd ./PPOCRLabel # 将目录切换到PPOCRLabel文件夹下
python gen_ocr_train_val_test.py --trainValTestRatio 7:3:0 --datasetRootPath ../train_data
trainValTestRatio是训练集、验证集、测试集的图像数量划分比例,根据实际情况设定,默认是6:2:2datasetRootPath是PPOCRLabel标注的完整数据集存放路径。默认路径是PaddleOCR/train_data分割数据集前应有如下结构:|-train_data |-crop_img |- word_001_crop_0.png |- word_002_crop_0.jpg |- word_003_crop_0.jpg | ... | Label.txt | rec_gt.txt |- word_001.png |- word_002.jpg |- word_003.jpg | ...
更多工具使用说明请参考详细说明
3. 数据格式
PaddleX针对文本检测任务定义的数据集,名称是TextDetDataset,整理标注完成的数据为如下文件组织形式和命名:
dataset_dir # 数据集根目录,目录名称可以改变
├── images # 存放图像的目录,目录名称可以改变,但要注意和train.txt val.txt的内容对应
├── train.txt # 训练集标注文件,文件名称不可改变,内容举例:images/img_0.jpg \t [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]]}, {...}]
└── val.txt # 验证集标注文件,文件名称不可改变,内容举例:images/img_61.jpg \t [{"transcription": "TEXT", "points": [[31, 10], [310, 140], [420, 220], [310, 170]]}, {...}]
将图像放置在images目录下,产生的Label.txt标注文件,重新命名为train.txt,同时标注验证集图像时产生的Label.txt标注文件,重新命名为val.txt文件,均放置在dataset_dir(名称可变)目录下。注意train.txt/val.txt中的图像的路径应是images/xxx。
标注文件的每行内容是一张图像的路径和一个组成元素是字典的列表,路径和列表必须使用制表符’\t‘进行分隔,不可使用空格进行分隔。
对于组成元素是字典的列表,字典中 points 表示文本框的四个顶点的坐标(x, y),从左上角的顶点开始按顺时针排序;字典中transcription表示该文本框的文字,若transcription 的内容为“###”时,表示该文本框无效,不参与训练。具体可以参考示例数据集。
如果您使用了PPOCRLabel标注数据,只需要在完成数据集划分后将文字检测(det)目录中的det_gt_train.txt改名为train.txt、det_gt_test.txt改名为val.txt即可。