
small_object_detection_tutorial.md 19 KB
comments: true
PaddleX 3.0 小目标检测产线———遥感图像小目标检测
PaddleX 提供了丰富的模型产线,模型产线由一个或多个模型组合实现,每个模型产线都能够解决特定的场景任务问题。PaddleX 所提供的模型产线均支持快速体验,如果效果不及预期,也同样支持使用私有数据微调模型,并且 PaddleX 提供了 Python API,方便将产线集成到个人项目中。在使用之前,您首先需要安装 PaddleX, 安装方式请参考 PaddleX 安装。此处以一个遥感小目标检测的任务为例子,介绍模型产线工具的使用流程。
1. 选择产线
首先,需要根据您的任务场景,选择对应的 PaddleX 产线,此处为遥感小目标检测,需要了解到这个任务属于小目标检测任务,对应 PaddleX 的小目标检测产线。如果无法确定任务和产线的对应关系,您可以在 PaddleX 支持的模型产线列表中了解相关产线的能力介绍。
2. 快速体验
PaddleX 提供了以下快速体验的方式,可以直接通过 PaddleX wheel 包在本地体验。
本地体验方式:
import paddlex from paddlex import create_model model = create_model("PP-YOLOE_plus_SOD-largesize-L") image_url = "https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/remote-scene-det_example.png" rst_save_dir = "./output" output = model.predict([image_url], batch_size=1) for res in output: res.print(json_format=False) res.save_to_img(rst_save_dir) res.save_to_json(rst_save_dir)
快速体验产出推理结果示例:
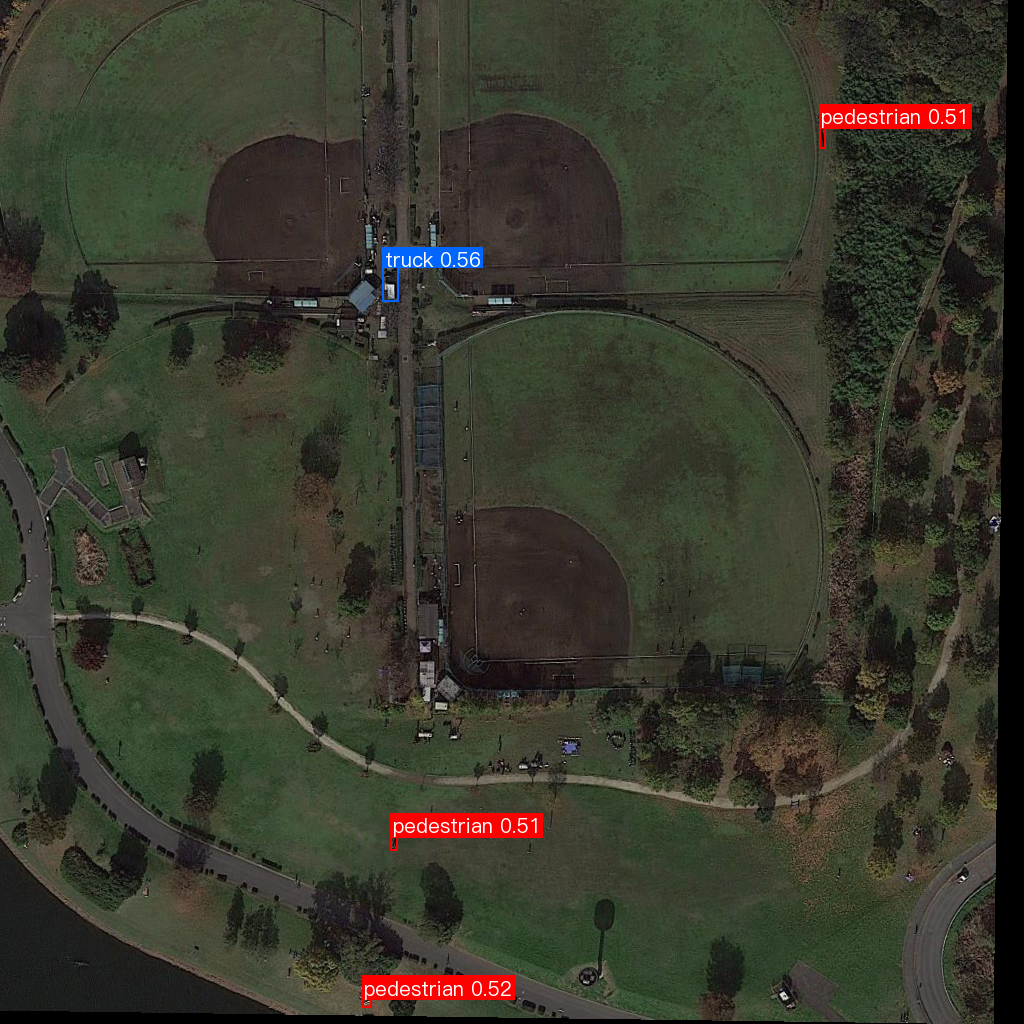
当体验完该产线之后,需要确定产线是否符合预期(包含精度、速度等),产线包含的模型是否需要继续微调,如果模型的速度或者精度不符合预期,则需要根据模型选择选择可替换的模型继续测试,确定效果是否满意。如果最终效果均不满意,则需要微调模型。本教程希望产出遥感领域的小目标检测模型,显然默认的权重(无人机航拍 数据集训练产出的权重)无法满足要求,需要采集和标注数据,然后进行训练微调。
3. 选择模型
PaddleX 提供了 3 个端到端的高精度高效率小目标检测模型,具体可参考 模型列表,其中部分模型的benchmark如下:
| 模型 | 模型下载链接 | mAP(0.5:0.95) | mAP(0.5) | GPU推理耗时(ms) [常规模式 / 高性能模式] |
GPU推理耗时(ms) [常规模式 / 高性能模式] |
模型存储大小(MB) | 介绍 |
|---|---|---|---|---|---|---|---|
| PP-YOLOE_plus_SOD-L | 推理模型/训练模型 | 31.9 | 52.1 | 100.02 / 48.33 | 271.29 / 151.20 | 324.93 | 基于VisDrone训练的PP-YOLOE_plus小目标检测模型。VisDrone是针对无人机视觉数据的基准数据集,由于目标较小同时具有一定的挑战性而被用于小目标检测任务的训练和评测 |
| PP-YOLOE_plus_SOD-S | 推理模型/训练模型 | 25.1 | 42.8 | 116.07 / 20.10 | 176.44 / 40.21 | 77.29 | |
| PP-YOLOE_plus_SOD-largesize-L | 推理模型/训练模型 | 42.7 | 65.9 | 515.69 / 460.17 | 2816.08 / 1736.00 | 340.42 |
注:以上精度指标为 VisDrone-DET 验证集 mAP(0.5:0.95)。所有模型 GPU 推理耗时基于 NVIDIA Tesla T4 机器,精度类型为 FP32, CPU 推理速度基于 Intel(R) Xeon(R) Gold 5117 CPU @ 2.00GHz,线程数为8,精度类型为 FP32。
4. 数据准备和校验
4.1 数据准备
本教程采用 遥感小目标检测数据集 作为示例数据集,可通过以下命令获取示例数据集。如果您使用自备的已标注数据集,需要按照 PaddleX 的格式要求对自备数据集进行调整,以满足 PaddleX 的数据格式要求。关于数据格式介绍,您可以参考 PaddleX 检测任务模块数据标注教程。
数据集获取命令:
cd /path/to/paddlex
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/remote_scene_object_detection.tar -P ./dataset
tar -xf ./dataset/remote_scene_object_detection.tar -C ./dataset/
4.2 数据集校验
在对数据集校验时,只需一行命令:
python main.py -c paddlex/configs/modules/small_object_detection/PP-YOLOE_plus_SOD-largesize-L.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/remote_scene_object_detection
执行上述命令后,PaddleX 会对数据集进行校验,并统计数据集的基本信息。命令运行成功后会在 log 中打印出 Check dataset passed ! 信息,同时相关产出会保存在当前目录的 ./output/check_dataset 目录下,产出目录中包括可视化的示例样本图片和样本分布直方图。校验结果文件保存在 ./output/check_dataset_result.json,校验结果文件具体内容为
{
"done_flag": true,
"check_pass": true,
"attributes": {
"num_classes": 15,
"train_samples": 172,
"train_sample_paths": [
"check_dataset\/demo_img\/P1751__1.0__824___824.png",
"check_dataset\/demo_img\/P1560__1.0__0___0.png",
"check_dataset\/demo_img\/P1051__1.0__0___0.png",
"check_dataset\/demo_img\/P1751__1.0__1648___0.png",
"check_dataset\/demo_img\/P0117__1.0__0___0.png",
"check_dataset\/demo_img\/P2365__1.0__1648___824.png",
"check_dataset\/demo_img\/P1750__1.0__0___1648.png",
"check_dataset\/demo_img\/P1560__1.0__824___1648.png",
"check_dataset\/demo_img\/P2152__1.0__0___0.png",
"check_dataset\/demo_img\/P0047__1.0__102___1143.png"
],
"val_samples": 80,
"val_sample_paths": [
"check_dataset\/demo_img\/P0551__1.0__288___354.png",
"check_dataset\/demo_img\/P0858__1.0__1360___441.png",
"check_dataset\/demo_img\/P1560__1.0__1648___2472.png",
"check_dataset\/demo_img\/P2722__1.0__1648___0.png",
"check_dataset\/demo_img\/P2462__1.0__824___824.png",
"check_dataset\/demo_img\/P0262__1.0__824___0.png",
"check_dataset\/demo_img\/P0047__1.0__0___0.png",
"check_dataset\/demo_img\/P2722__1.0__1648___1422.png",
"check_dataset\/demo_img\/P2645__1.0__0___1648.png",
"check_dataset\/demo_img\/P0858__1.0__0___441.png"
]
},
"analysis": {
"histogram": "check_dataset\/histogram.png"
},
"dataset_path": "rdet_dota_examples",
"show_type": "image",
"dataset_type": "COCODetDataset"
}
上述校验结果中,check_pass 为 True 表示数据集格式符合要求,其他部分指标的说明如下:
- attributes.num_classes:该数据集类别数为 15,此处类别数量为后续训练需要传入的类别数量;
- attributes.train_samples:该数据集训练集样本数量为 172;
- attributes.val_samples:该数据集验证集样本数量为 80;
- attributes.train_sample_paths:该数据集训练集样本可视化图片相对路径列表;
- attributes.val_sample_paths:该数据集验证集样本可视化图片相对路径列表;
另外,数据集校验还对数据集中所有类别的样本数量分布情况进行了分析,并绘制了分布直方图(histogram.png):
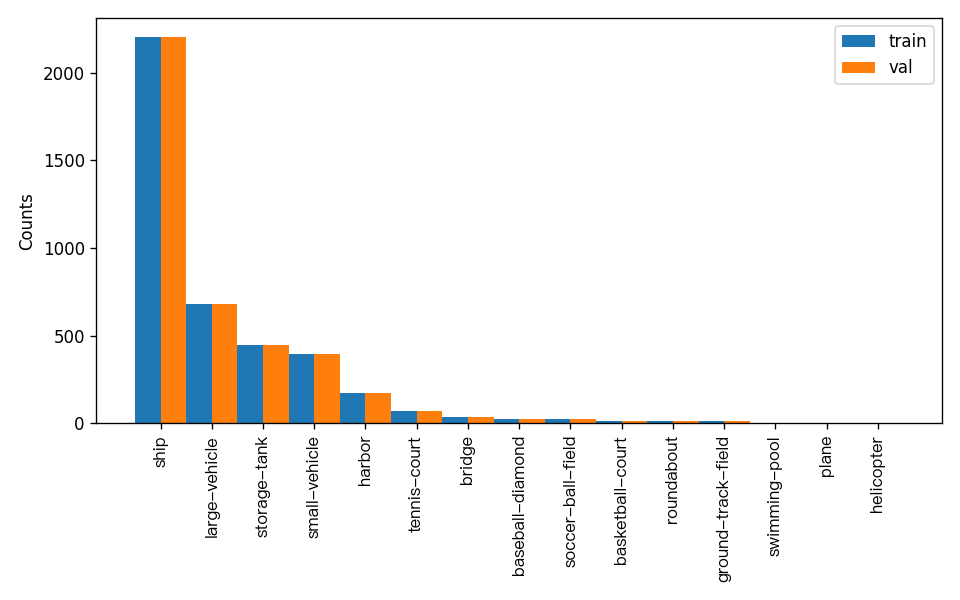
注:只有通过数据校验的数据才可以训练和评估。
4.3 数据集格式转换/数据集划分(非必选)
如需对数据集格式进行转换或是重新划分数据集,可通过修改配置文件或是追加超参数的方式进行设置。
数据集校验相关的参数可以通过修改配置文件中 CheckDataset 下的字段进行设置,配置文件中部分参数的示例说明如下:
CheckDataset:convert:enable: 是否进行数据集格式转换,为True时进行数据集格式转换,默认为False;src_dataset_type: 如果进行数据集格式转换,则需设置源数据集格式,数据可选源格式为LabelMe和VOC;
split:enable: 是否进行重新划分数据集,为True时进行数据集格式转换,默认为False;train_percent: 如果重新划分数据集,则需要设置训练集的百分比,类型为 0-100 之间的任意整数,需要保证和val_percent值加和为 100;val_percent: 如果重新划分数据集,则需要设置验证集的百分比,类型为 0-100 之间的任意整数,需要保证和train_percent值加和为 100;
数据转换和数据划分支持同时开启,对于数据划分原有标注文件会被在原路径下重命名为 xxx.bak,以上参数同样支持通过追加命令行参数的方式进行设置,例如重新划分数据集并设置训练集与验证集比例:-o CheckDataset.split.enable=True -o CheckDataset.split.train_percent=80 -o CheckDataset.split.val_percent=20。
5. 模型训练和评估
5.1 模型训练
在训练之前,请确保您已经对数据集进行了校验。完成 PaddleX 模型的训练,只需如下一条命令:
python main.py -c paddlex/configs/modules/small_object_detection/PP-YOLOE_plus_SOD-largesize-L.yaml \
-o Global.mode=train \
-o Global.dataset_dir=./dataset/remote_scene_object_detection \
-o Train.epochs_iters=80
在 PaddleX 中模型训练支持:修改训练超参数、单机单卡/多卡训练等功能,只需修改配置文件或追加命令行参数。
PaddleX 中每个模型都提供了模型开发的配置文件,用于设置相关参数。模型训练相关的参数可以通过修改配置文件中 Train 下的字段进行设置,配置文件中部分参数的示例说明如下:
Global:mode:模式,支持数据校验(check_dataset)、模型训练(train)、模型评估(evaluate);device:训练设备,可选cpu、gpu、xpu、npu、mlu,除 cpu 外,多卡训练可指定卡号,如:gpu:0,1,2,3;
Train:训练超参数设置;epochs_iters:训练迭代次数数设置;learning_rate:训练学习率设置;
更多超参数介绍,请参考 PaddleX 通用模型配置文件参数说明。
注:
- 以上参数可以通过追加令行参数的形式进行设置,如指定模式为模型训练:
-o Global.mode=train;指定前 2 卡 gpu 训练:-o Global.device=gpu:0,1;设置训练迭代次数为 80:-o Train.epochs_iters=80。 - 模型训练过程中,PaddleX 会自动保存模型权重文件,默认为
output,如需指定保存路径,可通过配置文件中-o Global.output字段 - PaddleX 对您屏蔽了动态图权重和静态图权重的概念。在模型训练的过程中,会同时产出动态图和静态图的权重,在模型推理时,默认选择静态图权重推理。
训练产出解释:
在完成模型训练后,所有产出保存在指定的输出目录(默认为./output/)下,通常有以下产出:
- train_result.json:训练结果记录文件,记录了训练任务是否正常完成,以及产出的权重指标、相关文件路径等;
- train.log:训练日志文件,记录了训练过程中的模型指标变化、loss 变化等;
- config.yaml:训练配置文件,记录了本次训练的超参数的配置;
- .pdparams、.pdema、.pdopt、.pdstate、.pdiparams、.pdmodel:模型权重相关文件,包括网络参数、优化器、EMA、静态图网络参数、静态图网络结构等;
5.2 模型评估
在完成模型训练后,可以对指定的模型权重文件在验证集上进行评估,验证模型精度。使用 PaddleX 进行模型评估,只需一行命令:
python main.py -c paddlex/configs/modules/small_object_detection/PP-YOLOE_plus_SOD-largesize-L.yaml \
-o Global.mode=evaluate \
-o Global.dataset_dir=./dataset/remote_scene_object_detection
与模型训练类似,模型评估支持修改配置文件或追加命令行参数的方式设置。
注: 在模型评估时,需要指定模型权重文件路径,每个配置文件中都内置了默认的权重保存路径,如需要改变,只需要通过追加命令行参数的形式进行设置即可,如-o Evaluate.weight_path=./output/best_model/model.pdparams。
5.3 模型调优
在学习了模型训练和评估后,我们可以通过调整超参数来提升模型的精度。通过合理调整训练轮数,您可以控制模型的训练深度,避免过拟合或欠拟合;而学习率的设置则关乎模型收敛的速度和稳定性。因此,在优化模型性能时,务必审慎考虑这两个参数的取值,并根据实际情况进行灵活调整,以获得最佳的训练效果。
推荐在调试参数时遵循控制变量法:
- 首先固定训练迭代次数为 40,批大小为 1。
- 基于 PP-YOLOE+ SOD 模型启动三个实验,学习率分别为:0.000625,0.00125,0.0125。
- 可以发现实验三精度最高的配置为学习率为 0.00125,在该训练超参数基础上,增加训练轮次数到80,可以看到达到更优的精度。
学习率探寻实验结果:
| 实验 | 迭代轮数 | 学习率 | batch_size | 训练环境 | mAP(0.5:0.95) |
|---|---|---|---|---|---|
| 实验一 | 40 | 0.000625 | 1 | 4卡 | 0.476 |
| 实验二 | 40 | 0.00125 | 1 | 4卡 | 0.412 |
| 实验三 | 40 | 0.0125 | 1 | 4卡 | 0.501 |
改变 epoch 实验结果:
| 实验 | 迭代轮数 | 学习率 | batch_size | 训练环境 | mAP(0.5:0.95) |
|---|---|---|---|---|---|
| 实验三 | 40 | 0.4 | 1 | 4卡 | 0.501 |
| 实验三增大训练迭代次数 | 80 | 0.4 | 1 | 4卡 | 0.512 |
注:本教程为8卡教程,如果您只有1张GPU,可通过调整训练卡数完成本次实验,但最终指标未必和上述指标对齐,属正常情况。
6. 产线测试
将产线中的模型替换为微调后的模型进行测试,如:
python main.py -c paddlex/configs/modules/small_object_detection/PP-YOLOE_plus_SOD-largesize-L.yaml \
-o Global.mode=predict \
-o Predict.model_dir="output/best_model/inference" \
-o Predict.input="https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/remote-scene-det_example.png"
通过上述可在./output下生成预测结果,预测结果如下:

7. 开发集成/部署
如果小目标检测产线可以达到您对产线推理速度和精度的要求,您可以直接进行开发集成/部署。
若您需要使用微调后的模型权重,可以获取 small_object_detection 产线配置文件,并加载配置文件进行预测。可执行如下命令将结果保存在
my_path中:paddlex --get_pipeline_config small_object_detection --save_path ./my_path
将微调后模型权重的本地路径填写至产线配置文件中的 model_dir 即可, 若您需要将通用小目标检测产线直接应用在您的 Python 项目中,可以参考 如下示例:
pipeline_name: small_object_detection
SubModules:
SmallObjectDetection:
module_name: small_object_detection
model_name: PP-YOLOE_plus_SOD-L
model_dir: null # 此处替换为您训练后得到的模型权重本地路径
batch_size: 1
threshold: 0.5
随后,在您的 Python 代码中,您可以这样使用产线:
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="my_path/small_object_detection.yaml")
output = pipeline.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/remote-scene-det_example.png")
for res in output:
res.print() # 打印预测的结构化输出
res.save_to_img("./output/") # 保存结果可视化图像
res.save_to_json("./output/") # 保存预测的结构化输出
更多参数请参考 小目标检测产线使用教程。
- 此外,PaddleX 也提供了其他三种部署方式,详细说明如下:
- 高性能部署:在实际生产环境中,许多应用对部署策略的性能指标(尤其是响应速度)有着较严苛的标准,以确保系统的高效运行与用户体验的流畅性。为此,PaddleX 提供高性能推理插件,旨在对模型推理及前后处理进行深度性能优化,实现端到端流程的显著提速,详细的高性能部署流程请参考 PaddleX 高性能推理指南。
- 服务化部署:服务化部署是实际生产环境中常见的一种部署形式。通过将推理功能封装为服务,客户端可以通过网络请求来访问这些服务,以获取推理结果。PaddleX 支持用户以低成本实现产线的服务化部署,详细的服务化部署流程请参考 PaddleX 服务化部署指南。
- 端侧部署:端侧部署是一种将计算和数据处理功能放在用户设备本身上的方式,设备可以直接处理数据,而不需要依赖远程的服务器。PaddleX 支持将模型部署在 Android 等端侧设备上,详细的端侧部署流程请参考 PaddleX端侧部署指南。
您可以根据需要选择合适的方式部署模型产线,进而进行后续的 AI 应用集成。