
QUCK_STARTED.md 6.4 KB
快速开始
参考本教程内容,快速体验 PaddleX,轻松完成深度学习模型开发全流程。本教程以『图像分类』任务为例,训练图像分类模型,解决花图像分类问题,数据集为常用的 Flowers102。
Flowers102 数据集中包含上千张花的图像,共涵盖 102 个花的品种,其中训练集有 1020 张图像,验证集有 1020 张图像。模型选择 PP-LCNet_x1_0,PP-LCNet_x1_0 是一个超轻量级的图像分类模型,训练和推理速度较快,PaddleX 中内置了 PP-LCNet_x1_0 模型的配置文件(paddlex/configs/image_classification/PP-LCNet_x1_0.yaml)。
接下来,就从环境配置开始,完成模型训练开发,最终得到能解决该问题的模型。
1. 环境配置与安装
参考 文档 完成环境配置与安装。
2. 准备数据
下载数据集压缩包 Flowers102数据集,并解压到 PaddleX/dataset/ 目录下。对于 Linux、MacOS 用户,也可参考以下命令完成:
cd PaddleX/dataset/
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/cls_flowers_examples.tar
tar xf cls_flowers_examples
准备完成后,数据集目录结构应为如下格式:
PaddleX
└── dataset
└── cls_flowers_examples
├── images
├── label.txt
├── train.txt
└── val.txt
3. 数据集校验
PaddleX 提供了数据集校验功能,能够对所用数据集的内容进行检查分析,确认数据集格式是否符合 PaddleX 要求,并分析数据集的概要信息。请参考下述命令完成。
python main.py -c paddlex/configs/image_classification/PP-LCNet_x1_0.yaml -o Global.mode=check_dataset -o Global.dataset_dir=dataset/cls_flowers_examples
在完成数据集校验后,会生成校验结果文件output/check_dataset_result.json,具体内容为
{
"done_flag": true,
"check_pass": true,
"attributes": {
"label_file": "dataset/label.txt",
"num_classes": 102,
"train_samples": 1020,
"train_sample_paths": [
"tmp/image_01904.jpg",
"tmp/image_06940.jpg"
],
"val_samples": 1020,
"val_sample_paths": [
"tmp/image_01937.jpg",
"tmp/image_06958.jpg"
]
},
"analysis": {
"histogram": "histogram.png"
},
"dataset_path": "dataset",
"show_type": "image",
"dataset_type": "ClsDataset"
}
上述校验结果中,check_pass 为 True 表示数据集格式符合要求,其他部分指标的说明如下:
- attributes.num_classes:该数据集类别数为 102;
- attributes.train_samples:该数据集训练集样本数量为 1020;
- attributes.val_samples:该数据集验证集样本数量为 1020;
另外,数据集校验还对数据集中所有类别的样本数量分布情况进行了分析,并绘制了分布直方图(histogram.png):
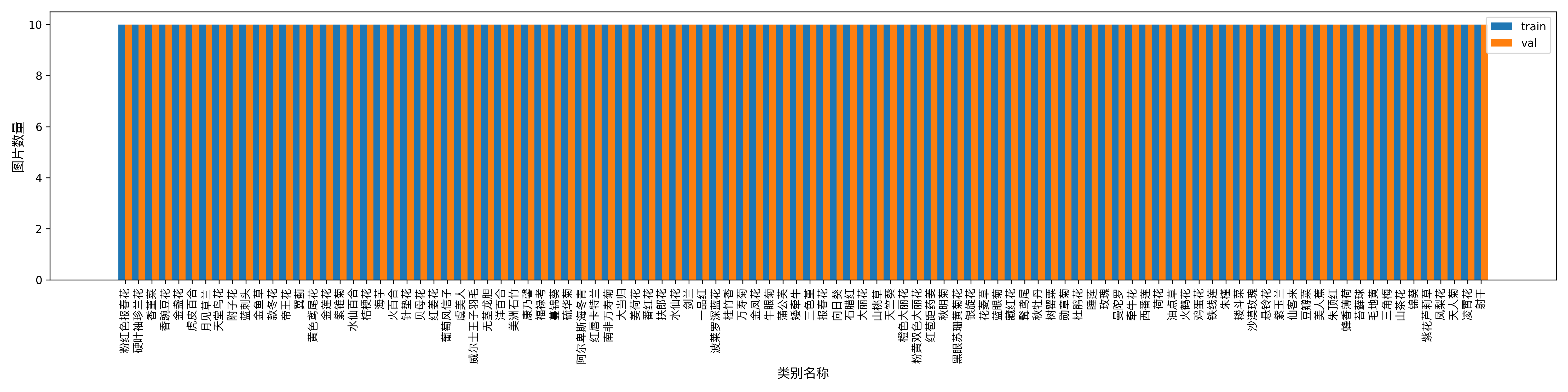
4. 模型训练
在完成数据集校验并通过后,即可使用该数据集训练模型。使用 PaddleX 训练模型仅需一条命令,
python main.py -c paddlex/configs/image_classification/PP-LCNet_x1_0.yaml -o Global.mode=train -o Global.dataset_dir=dataset/cls_flowers_examples
在完成模型训练后,会生成训练结果文件output/train_result.json,具体内容为
{
"model_name": "PP-LCNet_x1_0",
"done_flag": true,
"config": "config.yaml",
"label_dict": "label_dict.txt",
"train_log": "train.log",
"visualdl_log": "vdlrecords.1717143354.log",
"models": {
"last_1": {
"score": 0.6137255430221558,
"pdparams": "epoch_20.pdparams",
"pdema": "",
"pdopt": "epoch_20.pdopt",
"pdstates": "epoch_20.pdstates",
"inference_config": "epoch_20/inference.yml",
"pdmodel": "epoch_20/inference.pdmodel",
"pdiparams": "epoch_20/inference.pdiparams",
"pdiparams.info": "epoch_20/inference.pdiparams.info"
},
"best": {
"score": 0.6137255430221558,
"pdparams": "best_model.pdparams",
"pdema": "",
"pdopt": "best_model.pdopt",
"pdstates": "best_model.pdstates",
"inference_config": "best_model/inference.yml",
"pdmodel": "best_model/inference.pdmodel",
"pdiparams": "best_model/inference.pdiparams",
"pdiparams.info": "best_model/inference.pdiparams.info"
}
}
}
训练结果文件中的部分内容:
- train_log:训练日志文件的路径为
output/train.log; - models:训练产出的部分模型文件,其中:
- last_1:训练过程中,最后一轮 epoch 产出的模型;
- best:训练过程中产出的最佳模型,其在验证集上的精度最高,一般作为最终的模型用于后续处理;
在完成模型训练后,可以对训练得到的模型进行评估:
python main.py -c paddlex/configs/image_classification/PP-LCNet_x1_0.yaml -o Global.mode=evaluate -o Global.dataset_dir=dataset/cls_flowers_examples
在完成模型评估后,会生成评估结果文件output/evaluate_result.json,具体内容为
{
"done_flag": true,
"metrics": {
"val.top1": 0.62059,
"val.top5": 0.84118
}
}
评估结果文件中,展示了所评估的模型在验证集上的精度:
- val.top1:验证集上 Top1 的分类准确率;
- val.top5:验证集上 Top5 的分类准确率;
5. 模型推理
在训练得到满意的模型后,可以使用训练好的模型进行推理预测:
python main.py -c paddlex/configs/image_classification/PP-LCNet_x1_0.yaml -o Global.mode=predict -o Predict.model_dir="output/best_model" -o Predict.input_path="/paddle/dataset/paddlex/cls/cls_flowers_examples/images/image_00002.jpg"
上述命令中,可以通过修改配置文件(paddlex/configs/image_classification/PP-LCNet_x1_0.yaml)或-o追加参数的方式设置模型推理相关参数:
Predict.model_dir:使用的推理模型文件所在目录,在完成模型训练后,最佳模型的推理文件默认保存在output/best_model中,推理模型文件为inference.pdparams、inference.pdmodel等;Predict.input_path:待预测图像路径;
在执行上述命令进行推理后,可以在控制台输出预测结果,如下所示:
[{'class_ids': [76], 'scores': [0.66833], 'label_names': ['西番莲']}]