
dataset_check.md 13 KB
PaddleX 数据集校验
PaddleX 针对常见 AI 任务模块,给出通用简明的数据集规范,涵盖数据集名称、组织结构、标注格式。您可以参考下面不同任务的说明准备数据,进而可以通过 PaddleX 的数据校验,最后完成全流程任务开发。在数据校验过程中,PaddleX 支持额外的功能,如数据集格式转换、数据集划分等,您可以根据自己的需求选择使用。
1. 图像分类任务模块数据校验
1.1 数据准备
您需要按照 PaddleX 支持的数据格式要求准备数据,关于数据标注,您可以参考PaddleX 数据标注,关于数据格式介绍,您可以参考PaddleX 数据格式介绍,此处我们准备了图像分类 Demo 数据供您使用。
cd /path/to/paddlex
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/cls_flowers_examples.tar -P ./dataset
tar -xf ./dataset/cls_flowers_examples.tar -C ./dataset/
1.2 数据集校验
在对数据集校验时,只需一行命令:
python main.py -c paddlex/configs/image_classification/PP-LCNet_x1_0.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/cls_flowers_examples
执行上述命令后,PaddleX 会对数据集进行校验,并统计数据集的基本信息。命令运行成功后会在log中打印出 Check dataset passed ! 信息,同时相关产出会保存在当前目录的 ./output/check_dataset 目录下,产出目录中包括可视化的示例样本图片和样本分布直方图。校验结果文件保存在 ./output/check_dataset_result.json,校验结果文件具体内容为
{
"done_flag": true,
"check_pass": true,
"attributes": {
"label_file": "dataset/label.txt",
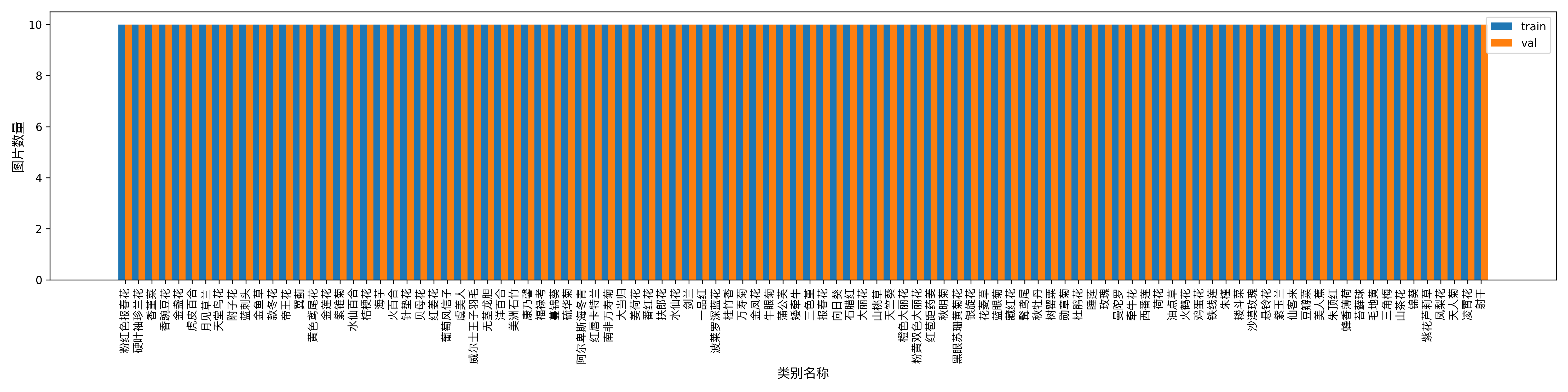
"num_classes": 102,
"train_samples": 1020,
"train_sample_paths": [
"check_dataset/demo_img/image_01904.jpg",
"check_dataset/demo_img/image_06940.jpg"
],
"val_samples": 1020,
"val_sample_paths": [
"check_dataset/demo_img/image_01937.jpg",
"check_dataset/demo_img/image_06958.jpg"
]
},
"analysis": {
"histogram": "check_dataset/histogram.png"
},
"dataset_path": "./dataset/cls_flowers_examples",
"show_type": "image",
"dataset_type": "ClsDataset"
}
上述校验结果中,check_pass 为 True 表示数据集格式符合要求,其他部分指标的说明如下:
- attributes.num_classes:该数据集类别数为 102;
- attributes.train_samples:该数据集训练集样本数量为 1020;
- attributes.val_samples:该数据集验证集样本数量为 1020;
- attributes.train_sample_paths:该数据集训练集样本可视化图片相对路径列表;
- attributes.val_sample_paths:该数据集验证集样本可视化图片相对路径列表;
另外,数据集校验还对数据集中所有类别的样本数量分布情况进行了分析,并绘制了分布直方图(histogram.png):
注:只有通过数据校验的数据才可以训练和评估。
1.3 数据集格式转换/数据集划分(非必选)
如需对数据集格式进行转换或是重新划分数据集,可通过修改配置文件或是追加超参数的方式进行设置。
数据集校验相关的参数可以通过修改配置文件中 CheckDataset 下的字段进行设置,配置文件中部分参数的示例说明如下:
CheckDataset:convert:enable: 是否进行数据集格式转换,为True时进行数据集格式转换,默认为False;src_dataset_type: 如果进行数据集格式转换,则需设置源数据集格式;
split:enable: 是否进行重新划分数据集,为True时进行数据集格式转换,默认为False;train_percent: 如果重新划分数据集,则需要设置训练集的百分比,类型为0-1之间的任意小数,需要保证和val_percent值加和为1;val_percent: 如果重新划分数据集,则需要设置验证集的百分比,类型为0-1之间的任意小数,需要保证和train_percent值加和为1;
数据转换和数据划分支持同时开启,对于数据划分原有标注文件会被在原路径下重命名为 xxx.bak,以上参数同样支持通过追加命令行参数的方式进行设置,例如如重新划分数据集并设置训练集与验证集比例:-o CheckDataset.split=True -o CheckDataset.train_percent=0.8 -o CheckDataset.val_percent=0.2。
2.目标检测任务模块数据校验
2.1 数据准备
您需要按照 PaddleX 支持的数据格式要求准备数据,关于数据标注,您可以参考PaddleX 数据标注,关于数据格式介绍,您可以参考PaddleX 数据格式介绍,此处我们准备了目标检测 Demo 数据供您使用。
cd /path/to/paddlex
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/det_coco_examples.tar -P ./dataset
tar -xf ./dataset/det_coco_examples.tar -C ./dataset/
2.2 数据集校验
在对数据集校验时,只需一行命令:
python main.py -c paddlex/configs/object_detection/PicoDet-S.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/det_coco_examples
执行上述命令后,PaddleX 会对数据集进行校验,并统计数据集的基本信息。命令运行成功后会在log中打印出 Check dataset passed ! 信息,同时相关产出会保存在当前目录的 ./output/check_dataset 目录下,产出目录中包括可视化的示例样本图片和样本分布直方图。校验结果文件保存在 ./output/check_dataset_result.json,校验结果文件具体内容为
{
"done_flag": true,
"check_pass": true,
"attributes": {
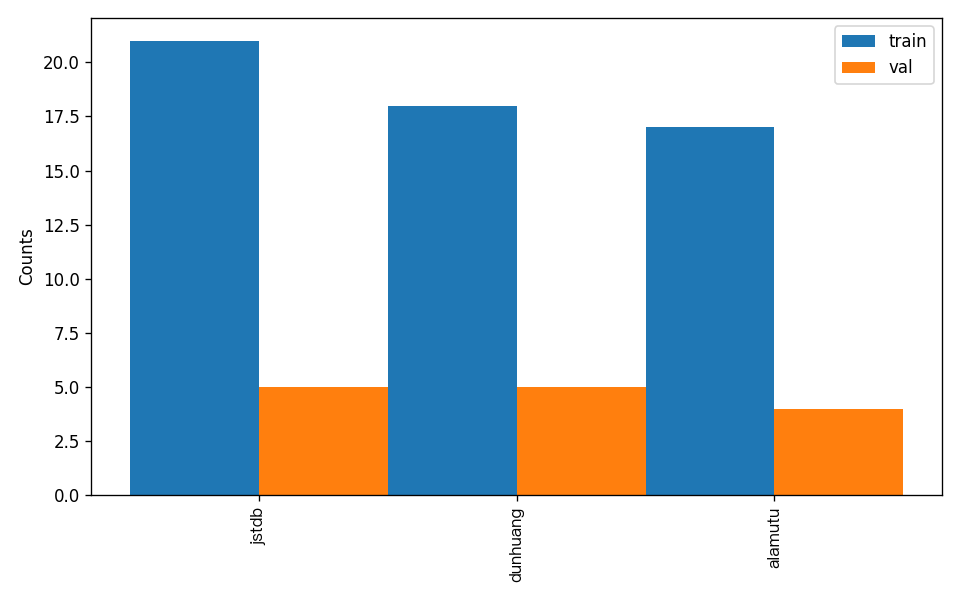
"num_classes": 3,
"train_samples": 56,
"train_sample_paths": [
"check_dataset/demo_img/304.png",
"check_dataset/demo_img/322.png"
],
"val_samples": 14,
"val_sample_paths": [
"check_dataset/demo_img/114.png",
"check_dataset/demo_img/206.png"
]
},
"analysis": {
"histogram": "check_dataset/histogram.png"
},
"dataset_path": "./dataset/det_coco_examples",
"show_type": "image",
"dataset_type": "COCODetDataset"
}
上述校验结果中,check_pass 为 True 表示数据集格式符合要求,其他部分指标的说明如下:
- attributes.num_classes:该数据集类别数为 3;
- attributes.train_samples:该数据集训练集样本数量为 56;
- attributes.val_samples:该数据集验证集样本数量为 14;
- attributes.train_sample_paths:该数据集训练集样本可视化图片相对路径列表;
- attributes.val_sample_paths:该数据集验证集样本可视化图片相对路径列表;
另外,数据集校验还对数据集中所有类别的样本数量分布情况进行了分析,并绘制了分布直方图(histogram.png):
注:只有通过数据校验的数据才可以训练和评估。
2.3 数据集格式转换/数据集划分(非必选)
如需对数据集格式进行转换或是重新划分数据集,可通过修改配置文件或是追加超参数的方式进行设置。
数据集校验相关的参数可以通过修改配置文件中 CheckDataset 下的字段进行设置,配置文件中部分参数的示例说明如下:
CheckDataset:convert:enable: 是否进行数据集格式转换,为True时进行数据集格式转换,默认为False;src_dataset_type: 如果进行数据集格式转换,则需设置源数据集格式;
split:enable: 是否进行重新划分数据集,为True时进行数据集格式转换,默认为False;train_percent: 如果重新划分数据集,则需要设置训练集的百分比,类型为0-1之间的任意小数,需要保证和val_percent值加和为1;val_percent: 如果重新划分数据集,则需要设置验证集的百分比,类型为0-1之间的任意小数,需要保证和train_percent值加和为1;
数据转换和数据划分支持同时开启,对于数据划分原有标注文件会被在原路径下重命名为 xxx.bak,以上参数同样支持通过追加命令行参数的方式进行设置,例如如重新划分数据集并设置训练集与验证集比例:-o CheckDataset.split=True -o CheckDataset.train_percent=0.8 -o CheckDataset.val_percent=0.2。
3.语义分割任务模块数据校验
3.1 数据准备
您需要按照 PaddleX 支持的数据格式要求准备数据,关于数据标注,您可以参考PaddleX 数据标注,关于数据格式介绍,您可以参考PaddleX 数据格式介绍,此处我们准备了语义分割 Demo 数据供您使用。
cd /path/to/paddlex
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/seg_optic_examples.tar -P ./dataset
tar -xf ./dataset/seg_optic_examples.tar -C ./dataset/
3.2 数据集校验
在对数据集校验时,只需一行命令:
python main.py -c paddlex/configs/semantic_segmentation/PP-LiteSeg-T.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/seg_optic_examples
执行上述命令后,PaddleX 会对数据集进行校验,并统计数据集的基本信息。命令运行成功后会在log中打印出 Check dataset passed ! 信息,同时相关产出会保存在当前目录的 ./output/check_dataset 目录下,产出目录中包括可视化的示例样本图片和样本分布直方图。校验结果文件保存在 ./output/check_dataset_result.json,校验结果文件具体内容为
{
"done_flag": true,
"check_pass": true,
"attributes": {
"train_sample_paths": [
"check_dataset/demo_img/P0005.jpg",
"check_dataset/demo_img/P0050.jpg"
],
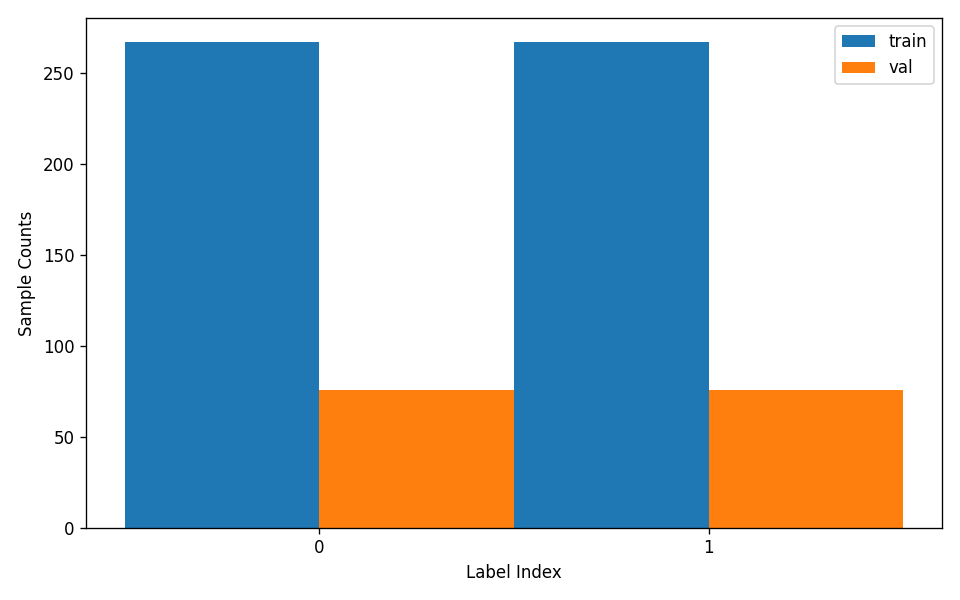
"train_samples": 267,
"val_sample_paths": [
"check_dataset/demo_img/N0139.jpg",
"check_dataset/demo_img/P0137.jpg"
],
"val_samples": 76,
"num_classes": 2
},
"analysis": {
"histogram": "check_dataset/histogram.png"
},
"dataset_path": "./dataset/seg_optic_examples",
"show_type": "image",
"dataset_type": "SegDataset"
}
上述校验结果中,check_pass 为 True 表示数据集格式符合要求,其他部分指标的说明如下:
- attributes.num_classes:该数据集类别数为 2;
- attributes.train_samples:该数据集训练集样本数量为 267;
- attributes.val_samples:该数据集验证集样本数量为 76;
- attributes.train_sample_paths:该数据集训练集样本可视化图片相对路径列表;
- attributes.val_sample_paths:该数据集验证集样本可视化图片相对路径列表;
另外,数据集校验还对数据集中所有类别的样本数量分布情况进行了分析,并绘制了分布直方图(histogram.png):
注:只有通过数据校验的数据才可以训练和评估。
3.3 数据集格式转换/数据集划分(非必选)
如需对数据集格式进行转换或是重新划分数据集,可通过修改配置文件或是追加超参数的方式进行设置。
数据集校验相关的参数可以通过修改配置文件中 CheckDataset 下的字段进行设置,配置文件中部分参数的示例说明如下:
CheckDataset:convert:enable: 是否进行数据集格式转换,为True时进行数据集格式转换,默认为False;src_dataset_type: 如果进行数据集格式转换,则需设置源数据集格式;
split:enable: 是否进行重新划分数据集,为True时进行数据集格式转换,默认为False;train_percent: 如果重新划分数据集,则需要设置训练集的百分比,类型为0-1之间的任意小数,需要保证和val_percent值加和为1;val_percent: 如果重新划分数据集,则需要设置验证集的百分比,类型为0-1之间的任意小数,需要保证和train_percent值加和为1;
数据转换和数据划分支持同时开启,对于数据划分原有标注文件会被在原路径下重命名为 xxx.bak,以上参数同样支持通过追加命令行参数的方式进行设置,例如如重新划分数据集并设置训练集与验证集比例:-o CheckDataset.split=True -o CheckDataset.train_percent=0.8 -o CheckDataset.val_percent=0.2。