
windows.md 8.0 KB
基于PaddleInference的推理-Windows环境编译
本文档指引用户如何基于PaddleInference对飞桨模型进行推理,并编译执行。Windows 平台下,我们使用Visual Studio 2019 Community 进行了测试。微软从Visual Studio 2017开始即支持直接管理CMake跨平台编译项目,但是直到2019才提供了稳定和完全的支持,所以如果你想使用CMake管理项目编译构建,我们推荐你使用Visual Studio 2019环境下构建。
环境依赖
- Visual Studio 2019
- CUDA 10.0/CUDA 10.1/CUDA 10 .2等, CUDNN 7+ (仅在使用GPU版本的预测库时需要,需要与下载的预测库版本一致)
- CMake 3.0+
编译步骤
下面所有示例以工作目录为 D:\projects演示。
Step1: 下载PaddleX预测代码
d:
mkdir projects
cd projects
git clone https://github.com/PaddlePaddle/PaddleX.git
说明:其中C++预测代码在PaddleX\dygraph\deploy\cpp 目录,该目录不依赖任何PaddleX下其他目录。所有的公共实现代码在model_deploy目录下,所有示例代码都在demo目录下。
Step2: 下载PaddlePaddle C++ 预测库
PaddlePaddle C++ 预测库针对是否使用GPU、是否支持TensorRT、以及不同的CUDA版本提供了已经编译好的预测库,目前PaddleX支持Paddle预测库2.0+,最新2.1版本下载链接如下所示:
| 版本说明 | 预测库(2.1) | 编译器 | 构建工具 | cuDNN | CUDA |
|---|---|---|---|---|---|
| cpu_avx_mkl | paddle_inference.zip | Visual Studio 15 2017 | CMake v3.17.0 | - | - |
| cuda10.1_cudnn7_avx_mkl_trt6 | paddle_inference.zip | MSVC 2015 update 3 | CMake v3.17.0 | 7.6 | 10.1 |
| cuda10.2_cudnn7_avx_mkl_trt7 | paddle_inference.zip | MSVC 2015 update 3 | CMake v3.17.0 | 7.6 | 10.2 |
| cuda11.0_cudnn8_avx_mkl_trt7 | paddle_inference.zip | MSVC 2015 update 3 | CMake v3.17.0 | 8.0 | 11.0 |
请根据实际情况选择下载,如若以上版本不满足您的需求,请至C++预测库下载列表选择符合的版本。
将预测库解压后,其所在目录(例如D:\projects\paddle_inference_install_dir\)下主要包含的内容有:
├── \paddle\ # paddle核心库和头文件
|
├── \third_party\ # 第三方依赖库和头文件
|
└── \version.txt # 版本和编译信息
Step3: 安装配置OpenCV和加密
- 在OpenCV官网下载适用于Windows平台的3.4.6版本 下载地址
- 运行下载的可执行文件,将OpenCV解压至指定目录,例如
D:\projects\opencv - 配置环境变量,如下流程所示
- 我的电脑->属性->高级系统设置->环境变量
- 在系统变量中找到Path(如没有,自行创建),并双击编辑
- 新建,将opencv路径填入并保存,如
D:\projects\opencv\build\x64\vc15\bin - 在进行cmake构建时,会有相关提示,请注意vs2019的输出
- 如果开启加密,点击下载openssl,并解压至某个目录
Step4: 使用Visual Studio 2019直接编译CMake
- 打开Visual Studio 2019 Community,点击
继续但无需代码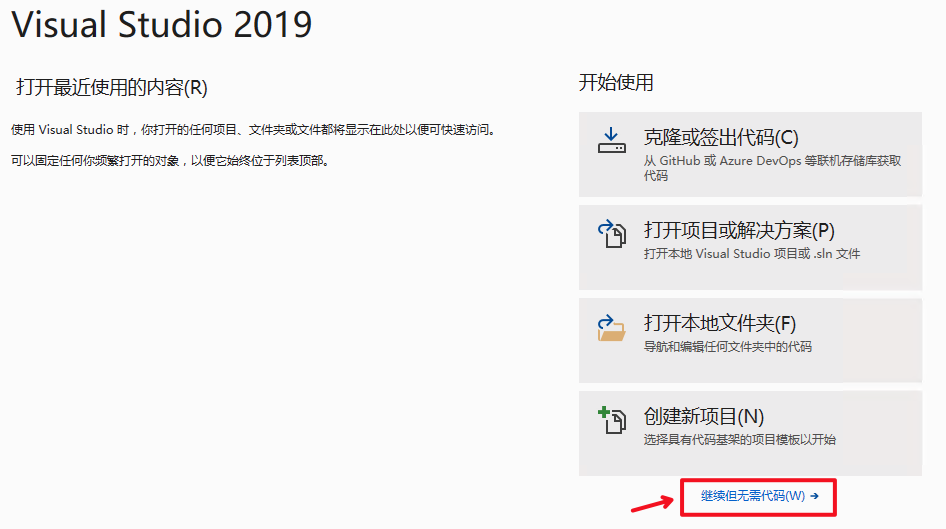
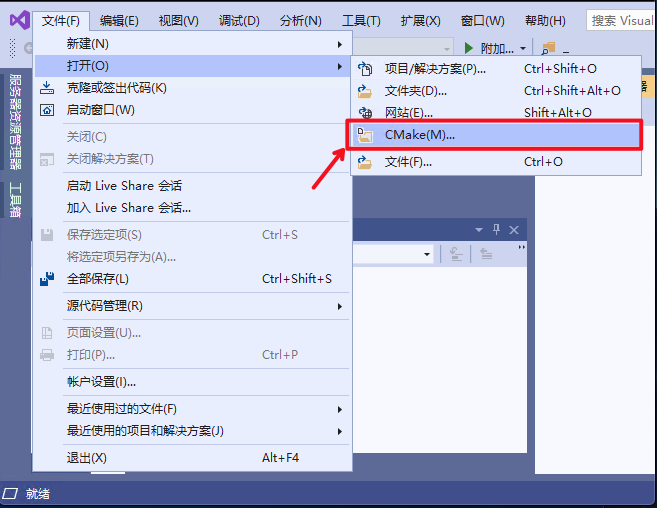
- 点击:
文件->打开->CMake
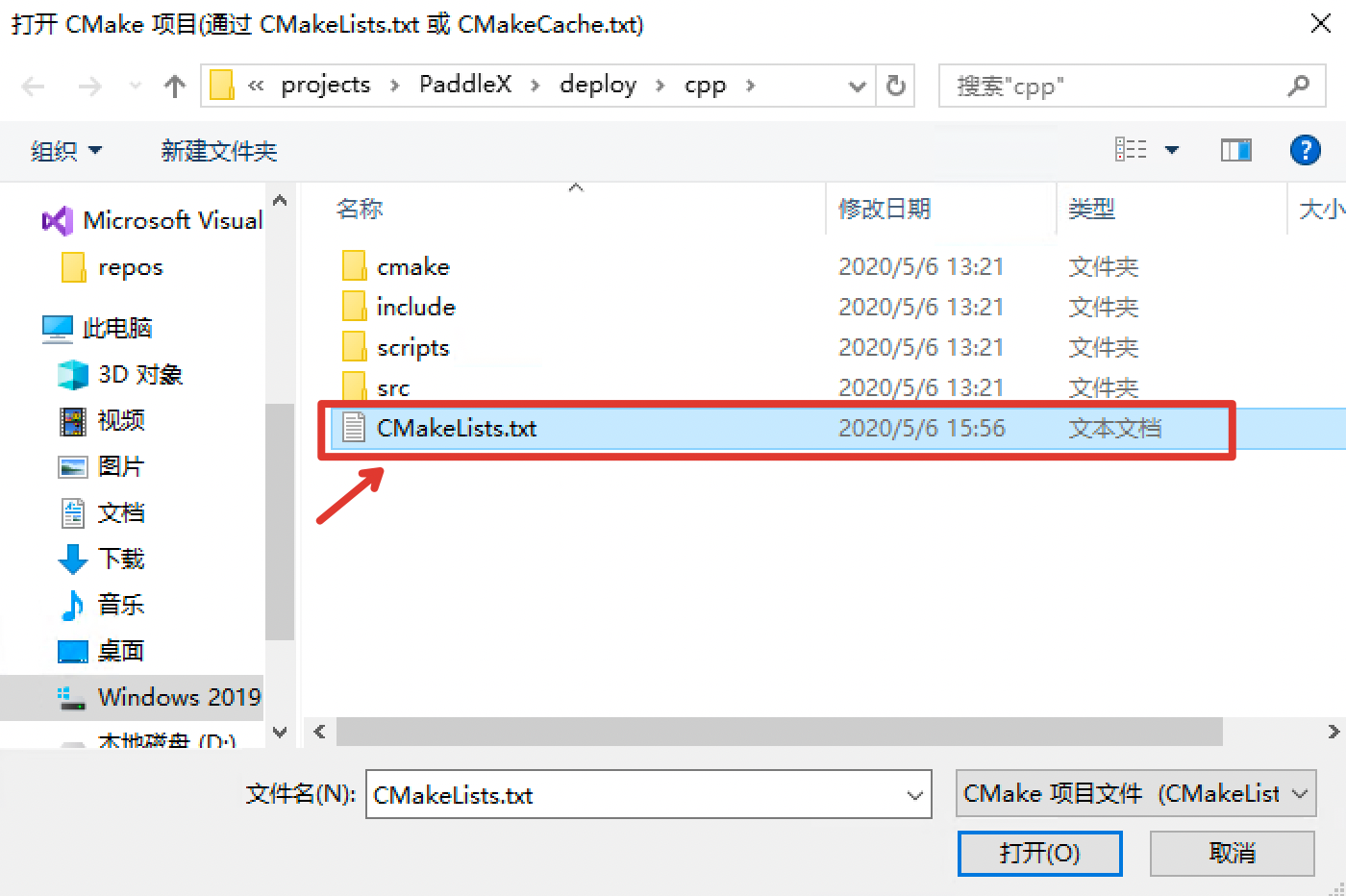
选择C++预测代码所在路径(例如D:\projects\PaddleX\dygraph\deploy\cpp),并打开CMakeList.txt:
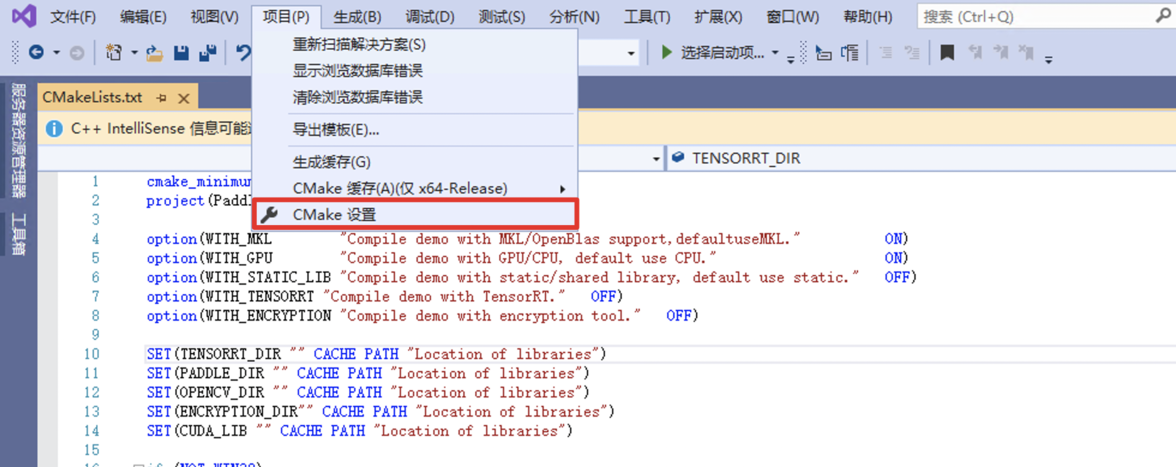
- 打开项目时,可能会自动构建。由于没有进行下面的依赖路径设置会报错,这个报错可以先忽略。
点击:项目->CMake设置(也可能叫PaddleDeploy的CMake设置)
- 点击
浏览,分别设置编译选项指定CUDA、OpenCV、Paddle预测库的路径(也可以点击右上角的“编辑 JSON”,直接修改json文件,然后保存点 项目->生成缓存) 如果需要模型加密,需要把WITH_ENCRYPTION勾选上,并填写openssl解压后的路径。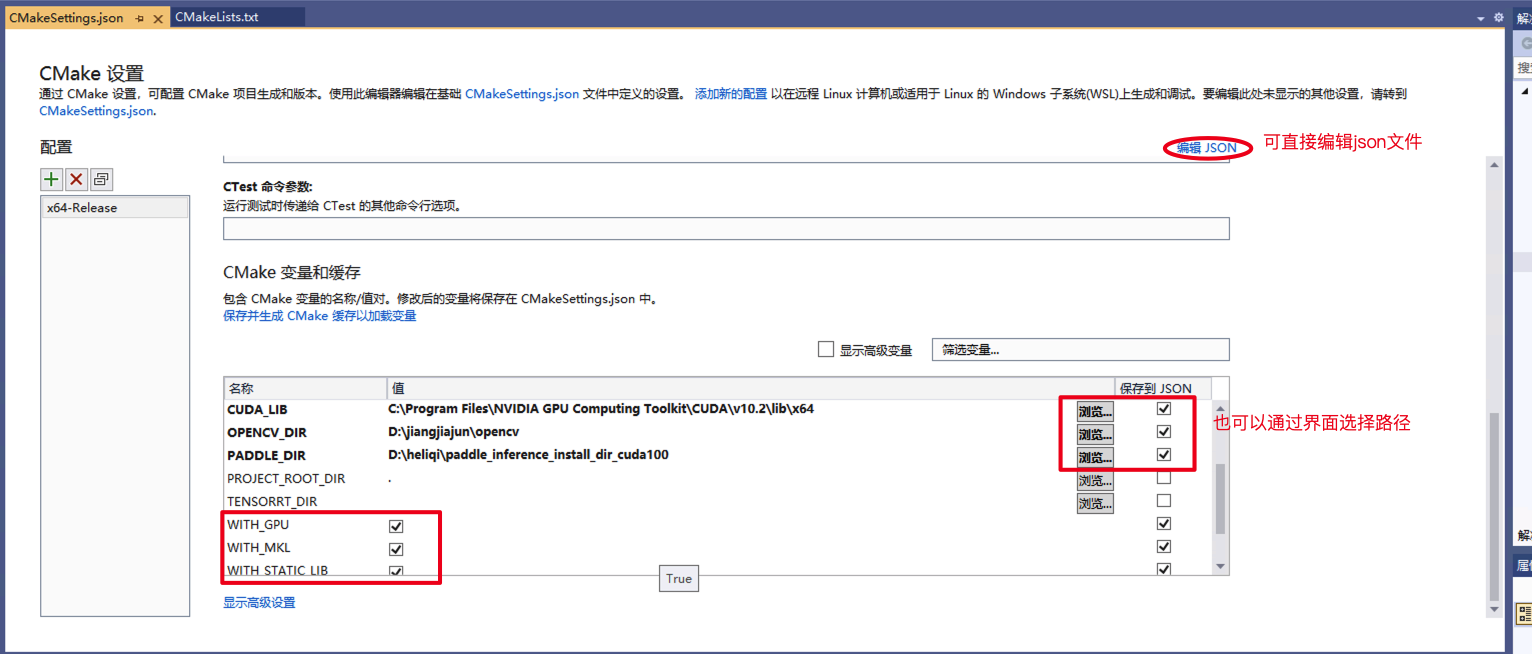 依赖库路径的含义说明如下(带*表示仅在使用GPU版本预测库时指定, 其中CUDA库版本尽量与Paddle预测库的对齐,例如Paddle预测库是使用9.0、10.0版本编译的,则编译PaddleX预测代码时不使用9.2、10.1等版本CUDA库):
依赖库路径的含义说明如下(带*表示仅在使用GPU版本预测库时指定, 其中CUDA库版本尽量与Paddle预测库的对齐,例如Paddle预测库是使用9.0、10.0版本编译的,则编译PaddleX预测代码时不使用9.2、10.1等版本CUDA库):
| 参数名 | 含义 |
|---|---|
| *CUDA_LIB | CUDA的库路径, 注:请将CUDNN的cudnn.lib文件拷贝到CUDA_LIB路径下。 例如 C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v10.2\\lib\\x64 |
| OPENCV_DIR | OpenCV的安装路径,例如D:\\projects\\opencv |
| PADDLE_DIR | Paddle c++预测库的路径,例如 D:\\projects\\paddle_inference_install_dir |
编译注意事项
- 如果使用
CPU版预测库,请把WITH_GPU的值去掉勾 - 如果使用的是
openblas版本,请把WITH_MKL的值去掉勾 - 如果无法联网,请手动点击下载 yaml-cpp.zip,无需解压,并修改
PaddleX\dygraph\deploy\cpp\cmake\yaml.cmake中将URL https://bj.bcebos.com/paddlex/deploy/deps/yaml-cpp.zip中的网址替换为第3步中下载的路径,如改为URL D:\projects\yaml-cpp.zip。 - 如果使用GPU, 当前官网下载的Paddle预测库一定要链接TensorRT。
- 如果使用加密部署, 一定记得勾选上WITH_ENCRYPTION,并填写OpenSSL路径
- 保存并生成CMake缓存
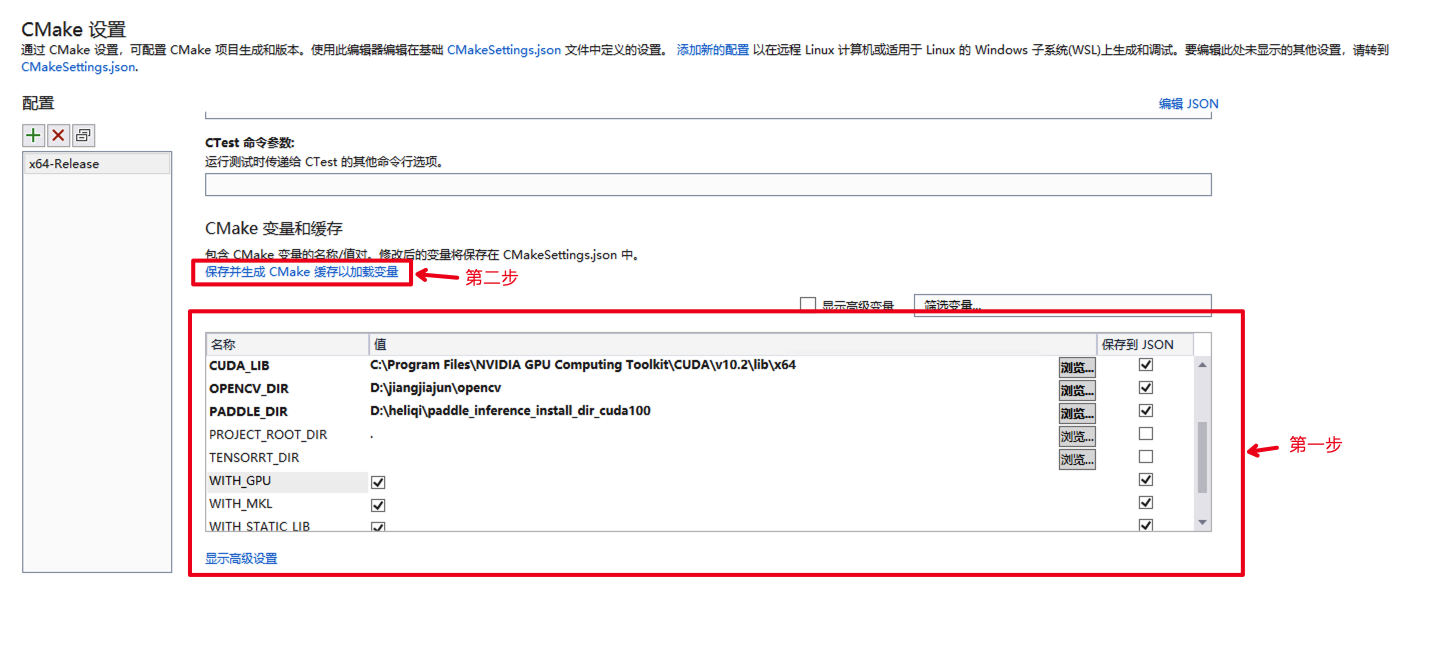 设置完成后, 点击上图中
设置完成后, 点击上图中保存并生成CMake缓存以加载变量。然后我们可以看到vs的输出会打印CMake生成的过程,出现CMake 生成完毕且无报错代表生成完毕。
- 点击
生成->全部生成,生成demo里的可执行文件。
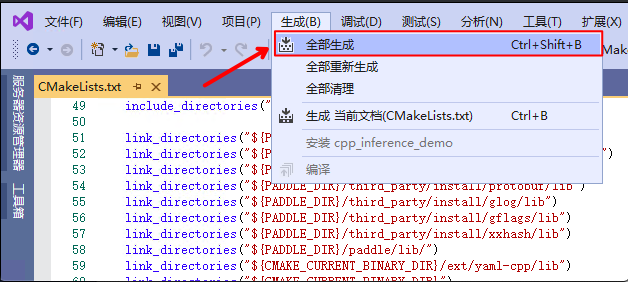
Step5: 编译结果
编译后会在PaddleX/dygraph/deploy/cpp/build/demo目录下生成model_infer和multi_gpu_model_infer两个可执行二进制文件示例,分别用于在单卡/多卡上加载模型进行预测,示例使用参考如下文档
如果编译时开启TensorRT, 会多成一个tensorrt_infer二进制文件示例。示例使用参考如下文档:
如果编译时开启加密, 会多成一个decrypt_infer二进制文件示例。示例使用参考如下文档: