
blog.md 25 KB
dots.ocr: Multilingual Document Layout Parsing in a Single Vision-Language Model
Introduction
dots.ocr is a powerful, multilingual document parser that unifies layout detection and content recognition within a single vision-language model while maintaining good reading order. Despite its compact 1.7B-parameter LLM foundation, it achieves state-of-the-art(SOTA) performance.
- Powerful Performance: dots.ocr achieves SOTA performance for text, tables, and reading order on OmniDocBench, while delivering formula recognition results comparable to much larger models like Doubao-1.5 and gemini2.5-pro.
- Multilingual Support: dots.ocr demonstrates robust parsing capabilities for low-resource languages, achieving decisive advantages across both layout detection and content recognition on our in-house multilingual documents benchmark.
- Unified and Simple Architecture: By leveraging a single vision-language model, dots.ocr offers a significantly more streamlined architecture than conventional methods that rely on complex, multi-model pipelines. Switching between tasks is accomplished simply by altering the input prompt, proving that a VLM can achieve competitive detection results compared to traditional detection models like DocLayout-YOLO.
- Efficient and Fast Performance: Built upon a compact 1.7B LLM, dots.ocr provides faster inference speeds than many other high-performing models based on larger foundations.
Performance Comparison on Document Parsing Benchmarks
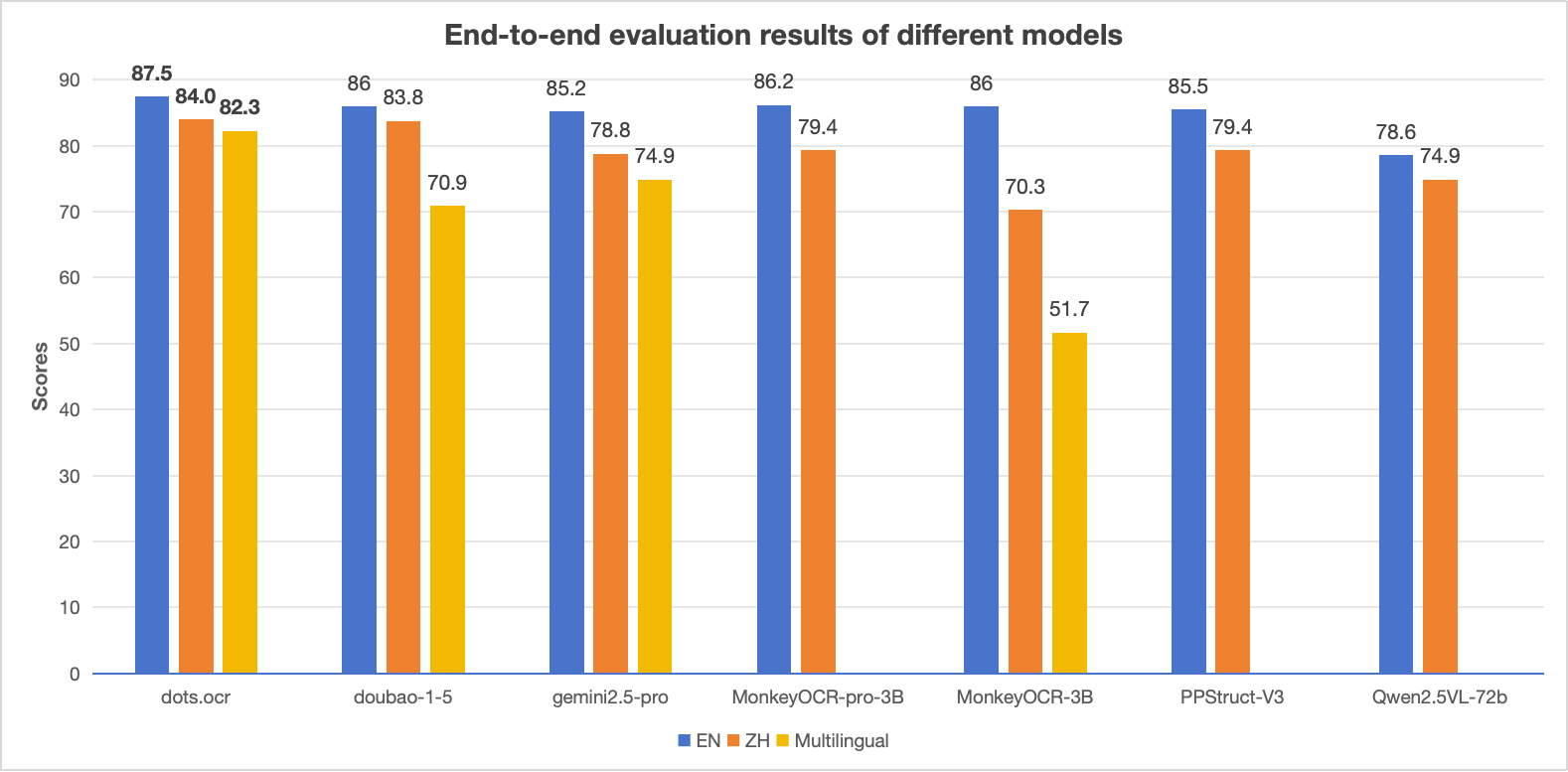
Notes:
- The EN, ZH metrics are the end2end evaluation results of OmniDocBench, and Multilingual metric is the end2end evaluation results of dots.ocr-bench.
Show Case
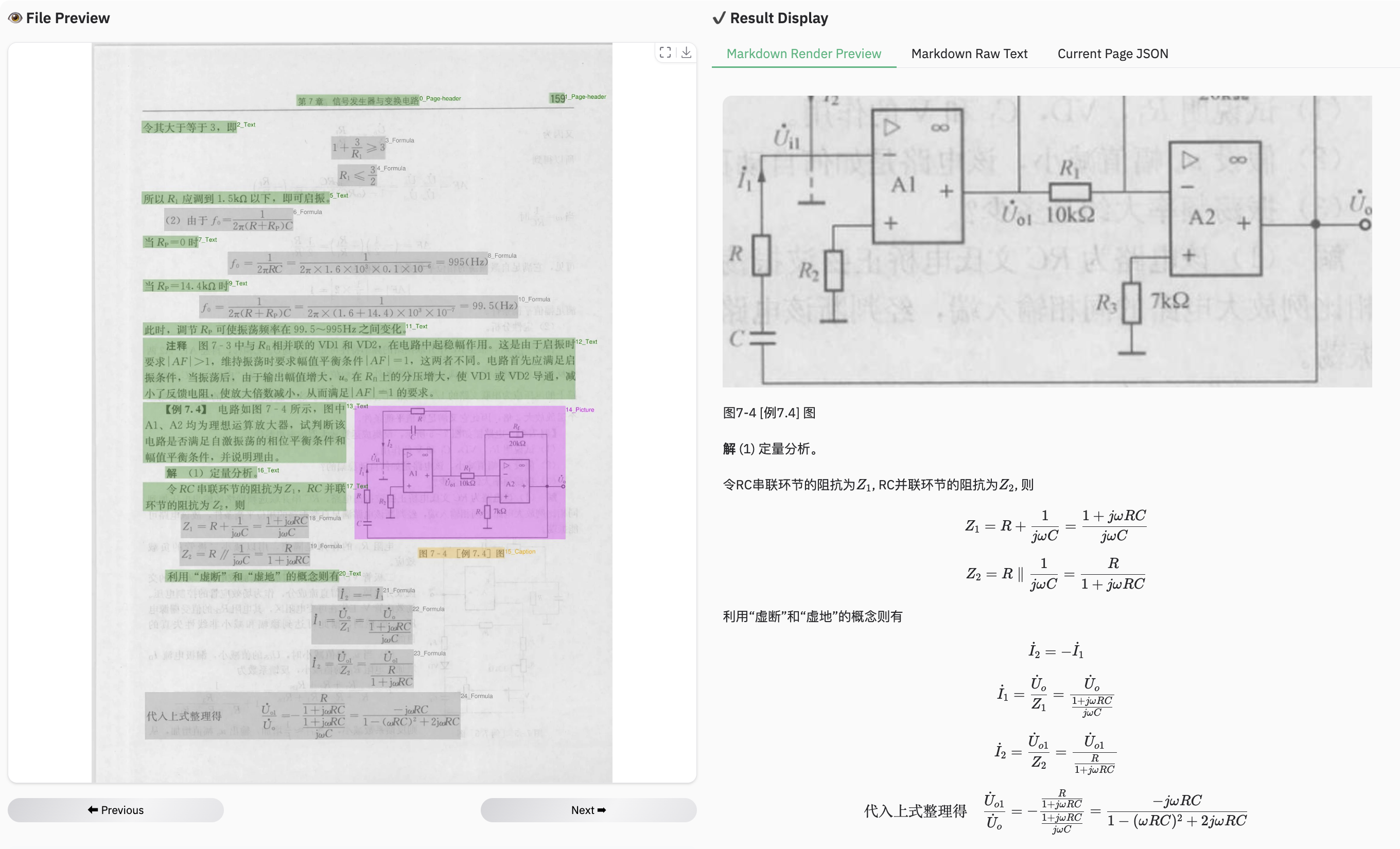
Example for formula document


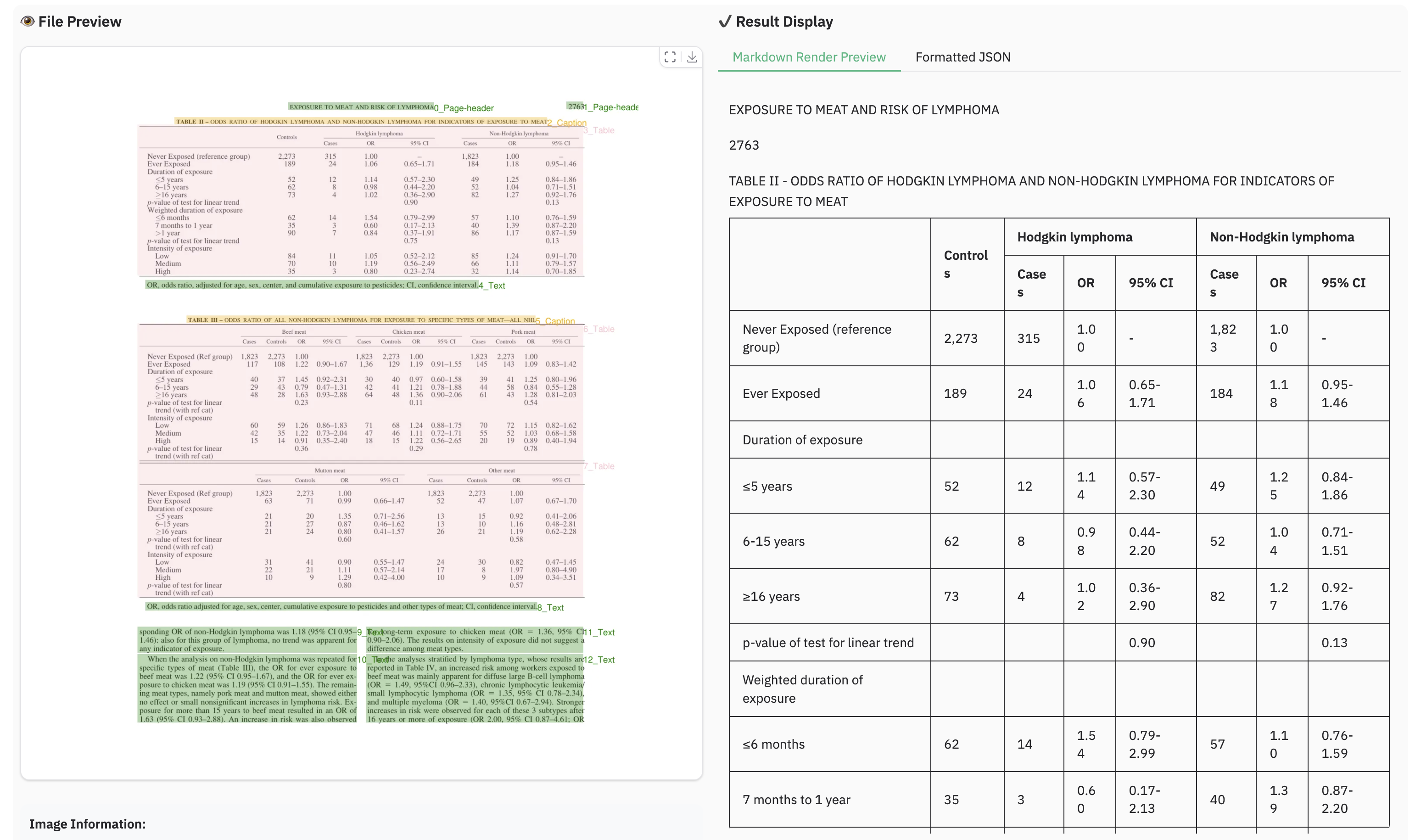
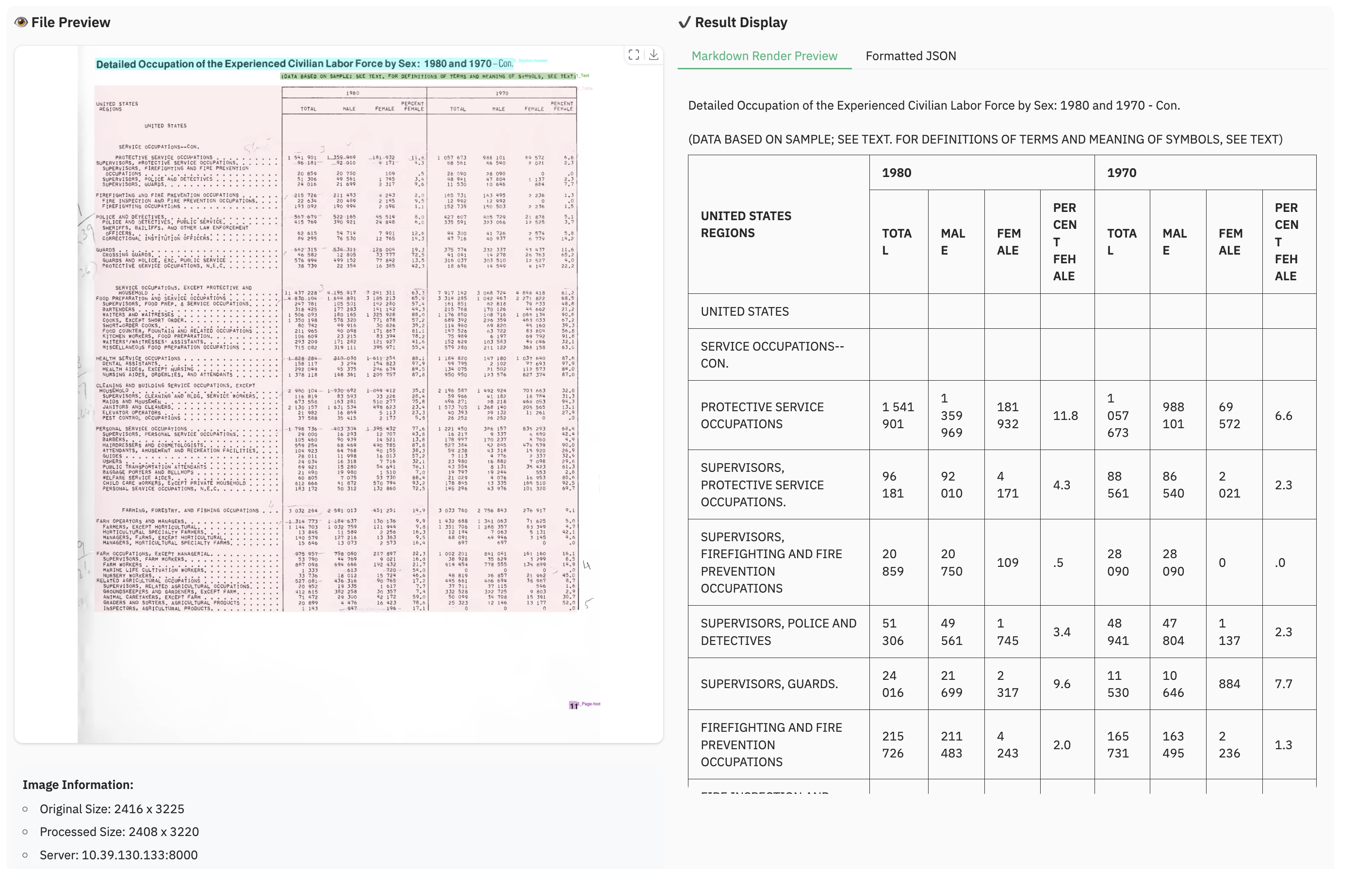
Example for table document
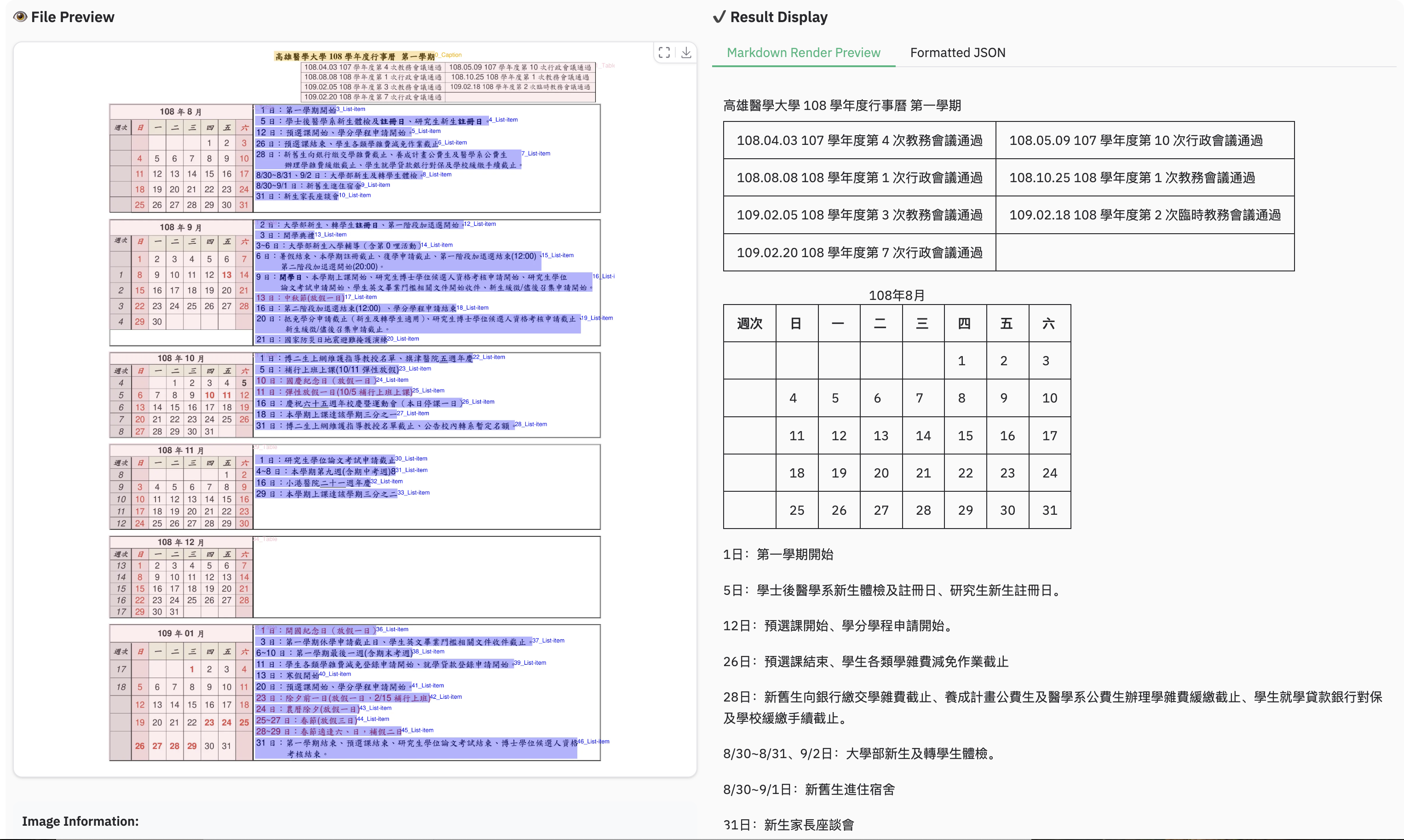
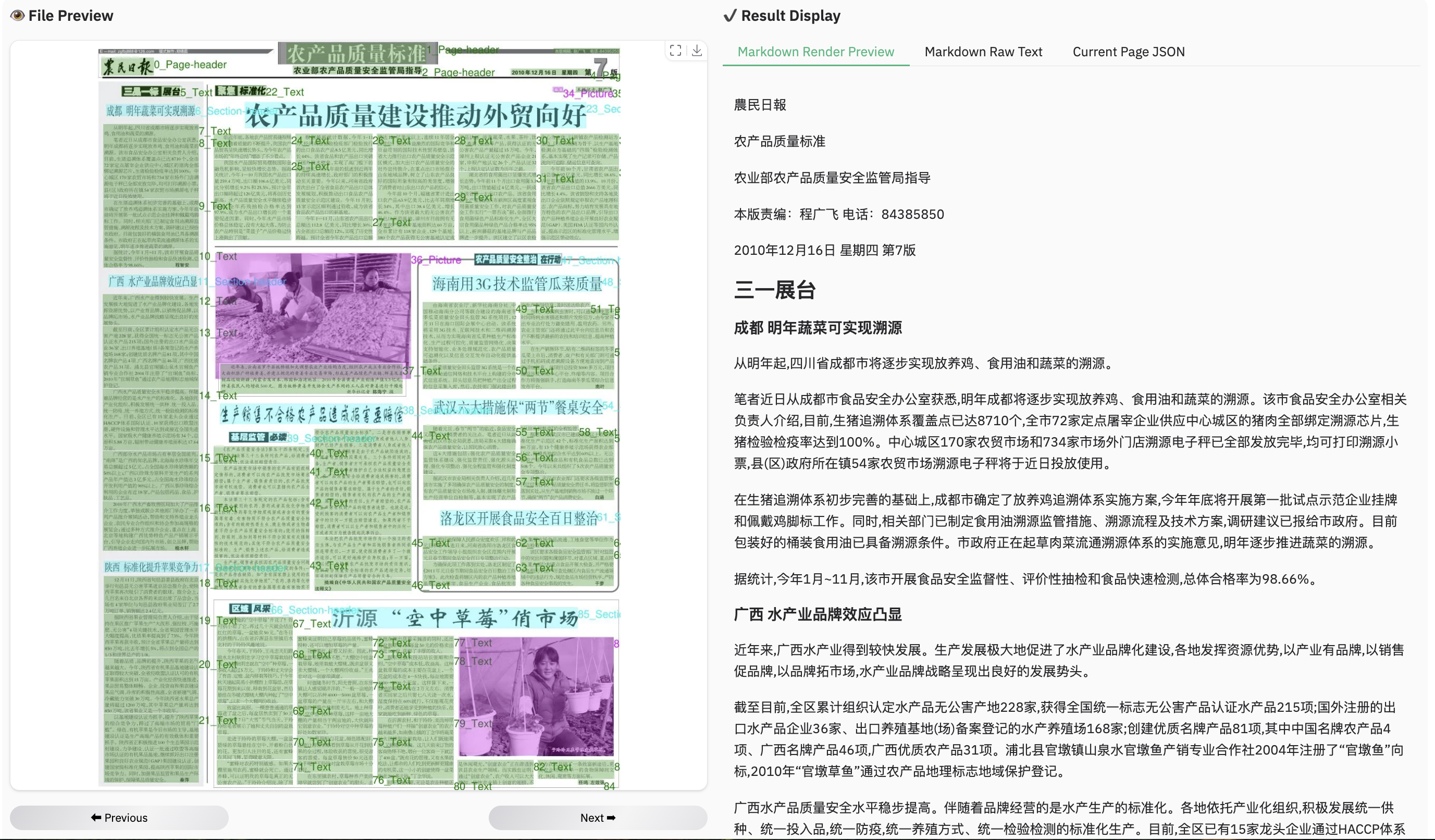
Example for multilingual document





Example for reading order
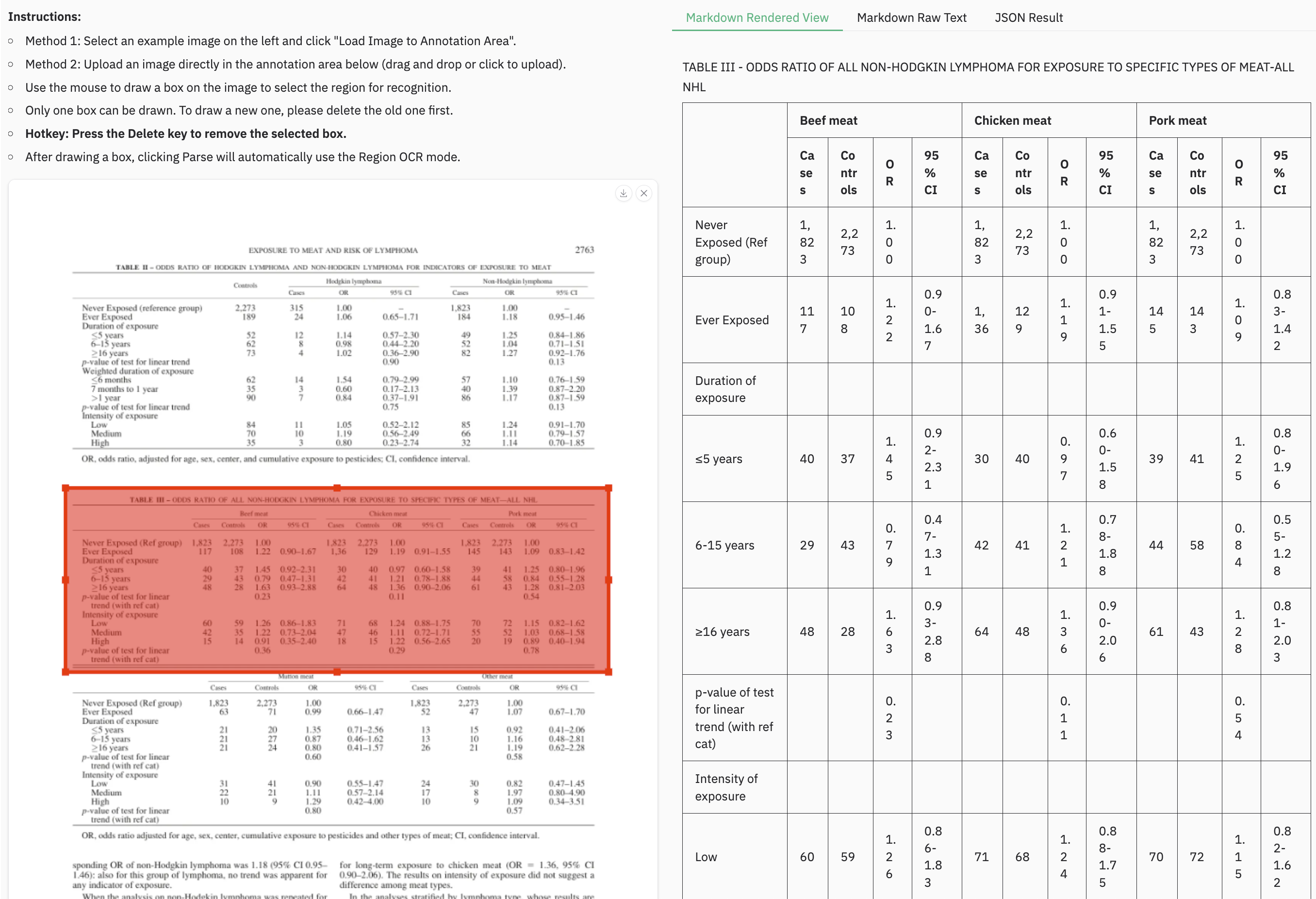
Example for grounding ocr
Benchmark Results
1. OmniDocBench
The end-to-end evaluation results of different tasks.
| Model Type |
Methods | OverallEdit↓ | TextEdit↓ | FormulaEdit↓ | TableTEDS↑ | TableEdit↓ | Read OrderEdit↓ | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EN | ZH | EN | ZH | EN | ZH | EN | ZH | EN | ZH | EN | ZH | ||
| Pipeline Tools |
MinerU | 0.150 | 0.357 | 0.061 | 0.215 | 0.278 | 0.577 | 78.6 | 62.1 | 0.180 | 0.344 | 0.079 | 0.292 |
| Marker | 0.336 | 0.556 | 0.080 | 0.315 | 0.530 | 0.883 | 67.6 | 49.2 | 0.619 | 0.685 | 0.114 | 0.340 | |
| Mathpix | 0.191 | 0.365 | 0.105 | 0.384 | 0.306 | 0.454 | 77.0 | 67.1 | 0.243 | 0.320 | 0.108 | 0.304 | |
| Docling | 0.589 | 0.909 | 0.416 | 0.987 | 0.999 | 1 | 61.3 | 25.0 | 0.627 | 0.810 | 0.313 | 0.837 | |
| Pix2Text | 0.320 | 0.528 | 0.138 | 0.356 | 0.276 | 0.611 | 73.6 | 66.2 | 0.584 | 0.645 | 0.281 | 0.499 | |
| Unstructured | 0.586 | 0.716 | 0.198 | 0.481 | 0.999 | 1 | 0 | 0.06 | 1 | 0.998 | 0.145 | 0.387 | |
| OpenParse | 0.646 | 0.814 | 0.681 | 0.974 | 0.996 | 1 | 64.8 | 27.5 | 0.284 | 0.639 | 0.595 | 0.641 | |
| PPStruct-V3 | 0.145 | 0.206 | 0.058 | 0.088 | 0.295 | 0.535 | - | - | 0.159 | 0.109 | 0.069 | 0.091 | |
| Expert VLMs |
GOT-OCR | 0.287 | 0.411 | 0.189 | 0.315 | 0.360 | 0.528 | 53.2 | 47.2 | 0.459 | 0.520 | 0.141 | 0.280 |
| Nougat | 0.452 | 0.973 | 0.365 | 0.998 | 0.488 | 0.941 | 39.9 | 0 | 0.572 | 1.000 | 0.382 | 0.954 | |
| Mistral OCR | 0.268 | 0.439 | 0.072 | 0.325 | 0.318 | 0.495 | 75.8 | 63.6 | 0.600 | 0.650 | 0.083 | 0.284 | |
| OLMOCR-sglang | 0.326 | 0.469 | 0.097 | 0.293 | 0.455 | 0.655 | 68.1 | 61.3 | 0.608 | 0.652 | 0.145 | 0.277 | |
| SmolDocling-256M | 0.493 | 0.816 | 0.262 | 0.838 | 0.753 | 0.997 | 44.9 | 16.5 | 0.729 | 0.907 | 0.227 | 0.522 | |
| Dolphin | 0.206 | 0.306 | 0.107 | 0.197 | 0.447 | 0.580 | 77.3 | 67.2 | 0.180 | 0.285 | 0.091 | 0.162 | |
| MinerU 2 | 0.139 | 0.240 | 0.047 | 0.109 | 0.297 | 0.536 | 82.5 | 79.0 | 0.141 | 0.195 | 0.069< | 0.118 | |
| OCRFlux | 0.195 | 0.281 | 0.064 | 0.183 | 0.379 | 0.613 | 71.6 | 81.3 | 0.253 | 0.139 | 0.086 | 0.187 | |
| MonkeyOCR-pro-3B | 0.138 | 0.206 | 0.067 | 0.107 | 0.246 | 0.421 | 81.5 | 87.5 | 0.139 | 0.111 | 0.100 | 0.185 | |
| General VLMs |
GPT4o | 0.233 | 0.399 | 0.144 | 0.409 | 0.425 | 0.606 | 72.0 | 62.9 | 0.234 | 0.329 | 0.128 | 0.251 |
| Qwen2-VL-72B | 0.252 | 0.327 | 0.096 | 0.218 | 0.404 | 0.487 | 76.8 | 76.4 | 0.387 | 0.408 | 0.119 | 0.193 | |
| Qwen2.5-VL-72B | 0.214 | 0.261 | 0.092 | 0.18 | 0.315 | 0.434 | 82.9 | 83.9 | 0.341 | 0.262 | 0.106 | 0.168 | |
| Gemini2.5-Pro | 0.148 | 0.212 | 0.055 | 0.168 | 0.356 | 0.439 | 85.8 | 86.4 | 0.13 | 0.119 | 0.049 | 0.121 | |
| doubao-1-5-thinking-vision-pro-250428 | 0.140 | 0.162 | 0.043 | 0.085 | 0.295 | 0.384 | 83.3 | 89.3 | 0.165 | 0.085 | 0.058 | 0.094 | |
| Expert VLMs | dots.ocr | 0.125 | 0.160 | 0.032 | 0.066 | 0.329 | 0.416 | 88.6 | 89.0 | 0.099 | 0.092 | 0.040 | 0.067 |
| Model Type |
Models | Book | Slides | Financial Report |
Textbook | Exam Paper |
Magazine | Academic Papers |
Notes | Newspaper | Overall |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Pipeline Tools |
MinerU | 0.055 | 0.124 | 0.033 | 0.102 | 0.159 | 0.072 | 0.025 | 0.984 | 0.171 | 0.206 |
| Marker | 0.074 | 0.340 | 0.089 | 0.319 | 0.452 | 0.153 | 0.059 | 0.651 | 0.192 | 0.274 | |
| Mathpix | 0.131 | 0.220 | 0.202 | 0.216 | 0.278 | 0.147 | 0.091 | 0.634 | 0.690 | 0.300 | |
| Expert VLMs |
GOT-OCR | 0.111 | 0.222 | 0.067 | 0.132 | 0.204 | 0.198 | 0.179 | 0.388 | 0.771 | 0.267 |
| Nougat | 0.734 | 0.958 | 1.000 | 0.820 | 0.930 | 0.830 | 0.214 | 0.991 | 0.871 | 0.806 | |
| Dolphin | 0.091 | 0.131 | 0.057 | 0.146 | 0.231 | 0.121 | 0.074 | 0.363 | 0.307 | 0.177 | |
| OCRFlux | 0.068 | 0.125 | 0.092 | 0.102 | 0.119 | 0.083 | 0.047 | 0.223 | 0.536 | 0.149 | |
| MonkeyOCR-pro-3B | 0.084 | 0.129 | 0.060 | 0.090 | 0.107 | 0.073 | 0.050 | 0.171 | 0.107 | 0.100 | |
| General VLMs |
GPT4o | 0.157 | 0.163 | 0.348 | 0.187 | 0.281 | 0.173 | 0.146 | 0.607 | 0.751 | 0.316 |
| Qwen2.5-VL-7B | 0.148 | 0.053 | 0.111 | 0.137 | 0.189 | 0.117 | 0.134 | 0.204 | 0.706 | 0.205 | |
| InternVL3-8B | 0.163 | 0.056 | 0.107 | 0.109 | 0.129 | 0.100 | 0.159 | 0.150 | 0.681 | 0.188 | |
| doubao-1-5-thinking-vision-pro-250428 | 0.048 | 0.048 | 0.024 | 0.062 | 0.085 | 0.051 | 0.039 | 0.096 | 0.181 | 0.073 | |
| Expert VLMs | dots.ocr | 0.031 | 0.047 | 0.011 | 0.082 | 0.079 | 0.028 | 0.029 | 0.109 | 0.056 | 0.055 |
Notes:
- The metrics are from MonkeyOCR, OmniDocBench, and our own internal evaluations.
- We delete the Page-header and Page-footer cells in the result markdown.
- We use tikz_preprocess pipeline to upsample the images to dpi 200.
2. dots.ocr-bench
This is an inhouse benchmark which contain 1493 pdf images with 100 languages.
The end-to-end evaluation results of different tasks.
| Methods | OverallEdit↓ | TextEdit↓ | FormulaEdit↓ | TableTEDS↑ | TableEdit↓ | Read OrderEdit↓ | MonkeyOCR-3B | 0.483 | 0.445 | 0.627 | 50.93 | 0.452 | 0.409 |
|---|---|---|---|---|---|---|
| doubao-1-5-thinking-vision-pro-250428 | 0.291 | 0.226 | 0.440 | 71.2 | 0.260 | 0.238 |
| doubao-1-6 | 0.299 | 0.270 | 0.417 | 71.0 | 0.258 | 0.253 |
| Gemini2.5-Pro | 0.251 | 0.163 | 0.402 | 77.1 | 0.236 | 0.202 |
| dots.ocr | 0.177 | 0.075 | 0.297 | 79.2 | 0.186 | 0.152 |
Notes:
- We use the same metric calculation pipeline of OmniDocBench.
- We delete the Page-header and Page-footer cells in the result markdown.
Layout Detection
| Method | F1@IoU=.50:.05:.95↑ | F1@IoU=.50↑ | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Overall | Text | Formula | Table | Picture | Overall | Text | Formula | Table | Picture | DocLayout-YOLO-DocStructBench | 0.733 | 0.694 | 0.480 | 0.803 | 0.619 | 0.806 | 0.779 | 0.620 | 0.858 | 0.678 |
| dots.ocr-parse all | 0.831 | 0.801 | 0.654 | 0.838 | 0.748 | 0.922 | 0.909 | 0.770 | 0.888 | 0.831 |
| dots.ocr-detection only | 0.845 | 0.816 | 0.716 | 0.875 | 0.765 | 0.930 | 0.917 | 0.832 | 0.918 | 0.843 |
Notes:
- prompt_layout_all_en for parse all, prompt_layout_only_en for detection only, please refer to prompts
3. olmOCR-bench.
| Model | ArXiv | Old Scans Math |
Tables | Old Scans | Headers and Footers |
Multi column |
Long Tiny Text |
Base | Overall |
|---|---|---|---|---|---|---|---|---|---|
| GOT OCR | 52.7 | 52.0 | 0.2 | 22.1 | 93.6 | 42.0 | 29.9 | 94.0 | 48.3 ± 1.1 |
| Marker | 76.0 | 57.9 | 57.6 | 27.8 | 84.9 | 72.9 | 84.6 | 99.1 | 70.1 ± 1.1 |
| MinerU | 75.4 | 47.4 | 60.9 | 17.3 | 96.6 | 59.0 | 39.1 | 96.6 | 61.5 ± 1.1 |
| Mistral OCR | 77.2 | 67.5 | 60.6 | 29.3 | 93.6 | 71.3 | 77.1 | 99.4 | 72.0 ± 1.1 |
| Nanonets OCR | 67.0 | 68.6 | 77.7 | 39.5 | 40.7 | 69.9 | 53.4 | 99.3 | 64.5 ± 1.1 |
| GPT-4o (No Anchor) |
51.5 | 75.5 | 69.1 | 40.9 | 94.2 | 68.9 | 54.1 | 96.7 | 68.9 ± 1.1 |
| GPT-4o (Anchored) |
53.5 | 74.5 | 70.0 | 40.7 | 93.8 | 69.3 | 60.6 | 96.8 | 69.9 ± 1.1 |
| Gemini Flash 2 (No Anchor) |
32.1 | 56.3 | 61.4 | 27.8 | 48.0 | 58.7 | 84.4 | 94.0 | 57.8 ± 1.1 |
| Gemini Flash 2 (Anchored) |
54.5 | 56.1 | 72.1 | 34.2 | 64.7 | 61.5 | 71.5 | 95.6 | 63.8 ± 1.2 |
| Qwen 2 VL (No Anchor) |
19.7 | 31.7 | 24.2 | 17.1 | 88.9 | 8.3 | 6.8 | 55.5 | 31.5 ± 0.9 |
| Qwen 2.5 VL (No Anchor) |
63.1 | 65.7 | 67.3 | 38.6 | 73.6 | 68.3 | 49.1 | 98.3 | 65.5 ± 1.2 |
| olmOCR v0.1.75 (No Anchor) |
71.5 | 71.4 | 71.4 | 42.8 | 94.1 | 77.7 | 71.0 | 97.8 | 74.7 ± 1.1 |
| olmOCR v0.1.75 (Anchored) |
74.9 | 71.2 | 71.0 | 42.2 | 94.5 | 78.3 | 73.3 | 98.3 | 75.5 ± 1.0 |
| MonkeyOCR-pro-3B | 83.8 | 68.8 | 74.6 | 36.1 | 91.2 | 76.6 | 80.1 | 95.3 | 75.8 ± 1.0 |
| dots.ocr | 82.1 | 64.2 | 88.3 | 40.9 | 94.1 | 82.4 | 81.2 | 99.5 | 79.1 ± 1.0 |
Note:
Methods
Pretrain
We developed a foundational Vision-Language Model (VLM) through a three-stage training process:
- Stage1: Vision Encoder Pre-training We trained a 1.2-billion-parameter Vision Encoder (VE) from scratch on a vast and comprehensive dataset of image-text pairs.
- Stage2: VE Continued Pre-training
We incorporated additional visual data, including OCR, video, grounding data, etc. Leveraging the
NaViTarchitecture, our model supports high-resolution inputs of up to 11 million pixels. The VE was then aligned with theQwen2.5-1.5Blanguage model and trained on this diverse visual data with LLM frozen, which resulted in our general vision encoderdots.vit. - Stage3: VLM Specialization for OCR
We then used a pure OCR dataset for training. To improve training efficiency, we first trained on a certain volume of tokens with the VE parameters frozen. Subsequently, we unfroze all parameters and continued training on an additional one-fifth of that token volume, which produced our foundational OCR model,
dots.ocr.base.
SFT
The SFT stage was implemented on the following key strategies:
- Diverse SFT Dataset: We constructed a dataset of nearly 300,000 samples, integrating our in-house manual annotations, synthetic data (tables, formulas, multilingual OCR), as well as open-source datasets.
- Iterative Data Flywheel: We employed a feedback loop to build an inhouse multilingual structured layout data with 15k samples. This process, repeated over three iterations, involved:
- Sampling "bad cases" based on model performance.
- Manually annotating these cases.
- Adding them back into the training set.
- Reading Order: We corrected the sequence of all layout element boxes to establish the correct reading order. This was primarily done using larger models for sorting, supplemented by rule-based post-processing methods. We found that with sufficient data diversity and quality, training the model on a list of elements sorted in their natural reading order yields excellent results.
- Quality and Robustness: We build a multi-expert system for data cleaning and distillation, and applied data augmentation (resizing, rotation, noise) to improve model robustness.
- Multitask training: We leveraged a single source of structured layout data to generate the SFT data with a variety of prompts. This approach enables the model to perform different tasks, such as detection and recognition, based on the specific prompt provided.
The resulting dots.ocr model demonstrates performance on par with models possessing significantly more parameters.
Limitation & Future Work
Complex Document Elements:
- Table&Formula: dots.ocr is not yet perfect for high-complexity tables and formula extraction.
- Picture: Pictures in documents are currently not parsed.
Parsing Failures: The model may fail to parse under certain conditions:
- When the character-to-pixel ratio is excessively high. Try enlarging the image or increasing the PDF parsing DPI (a setting of 200 is recommended). However, please note that the model performs optimally on images with a resolution under 11289600 pixels.
- Continuous special characters, such as ellipses (
...) and underscores (_), may cause the prediction output to repeat endlessly. In such scenarios, consider using alternative prompts likeprompt_layout_only_en,prompt_ocr, orprompt_grounding_ocr(details here).
Performance Bottleneck: Despite its 1.7B parameter LLM foundation, dots.ocr is not yet optimized for high-throughput processing of large PDF volumes.
We are committed to achieving more accurate table and formula parsing, as well as enhancing the model's OCR capabilities for broader generalization, all while aiming for a more powerful, more efficient model. Furthermore, we are actively considering the development of a more general-purpose perception model based on Vision-Language Models (VLMs), which would integrate general detection, image captioning, and OCR tasks into a unified framework. Parsing the content of the pictures in the documents is also a key priority for our future work. We believe that collaboration is the key to tackling these exciting challenges. If you are passionate about advancing the frontiers of document intelligence and are interested in contributing to these future endeavors, we would love to hear from you. Please reach out to us via email at: [yanqing4@xiaohongshu.com].
Author List
Contributors
Mi Jian, Yumeng Li, Bowen Wang, Xiaomin He, Zheyuan Gu
Project Leader
Qing Yan
Advisor
Colin Zhang, Lei Zhang